ReLU层的设计:
ReLU函数:
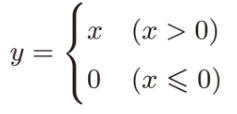
导数:

class Relu: def __init__(self): self.mask=None def forword(self,x): self.mask=(x<0) #变量mask是由True/False构成的Numpy数组 out=x.copy() out[self.mask]=0 return out def backward(self,dout): dout[self.mask]=0 dx=dout return dx
Sigmoid层的设计:
class Sigmoid: def __init__(self): self.out = None def forward(self, x): out = 1 / (1 + np.exp(-x)) self.out = out return out def backward(self, dout): dx = dout * (1.0 - self.out) * self.out return dx
Affine 层:
class Affine: def __init__(self, W, b): self.W = W self.b = b self.x = None self.dW = None self.db = None def forward(self, x): self.x = x out = np.dot(x, self.W) + self.b return out def backward(self, dout): dx = np.dot(dout, self.W.T) self.dW = np.dot(self.x.T, dout) self.db = np.sum(dout, axis=0) return dx
Softmax-with-Loss 层的实现
class SoftmaxWithLoss: def __init__(self): self.loss = None # 损失 self.y = None # softmax的输出 self.t = None # 监督数据(one-hot vector) def forward(self, x, t): self.t = t self.y = softmax(x) self.loss = cross_entropy_error(self.y, self.t) return self.loss def backward(self, dout=1): batch_size = self.t.shape[0] dx = (self.y - self.t) / batch_size return dx
对应误差反向传播法的神经网络的实现:
import sys, os sys.path.append(os.pardir) import numpy as np from common.layers import * from common.gradient import numerical_gradient from collections import OrderedDict class TwoLayerNet: def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01): # 初始化权重 self.params = {} self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size) self.params['b1'] = np.zeros(hidden_size) self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size) self.params['b2'] = np.zeros(output_size) # 生成层 self.layers = OrderedDict() # OrderedDict是有序字典 self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1']) self.layers['Relu1'] = Relu() self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2']) self.lastLayer = SoftmaxWithLoss() def predict(self, x): for layer in self.layers.values(): x = layer.forward(x) return x # x:输入数据, t:监督数据 def loss(self, x, t): y = self.predict(x) return self.lastLayer.forward(y, t) def accuracy(self, x, t): y = self.predict(x) y = np.argmax(y, axis=1) if t.ndim != 1 : t = np.argmax(t, axis=1) accuracy = np.sum(y == t) / float(x.shape[0]) return accuracy # x:输入数据, t:监督数据 def numerical_gradient(self, x, t): loss_W = lambda W: self.loss(x, t) grads = {} grads['W1'] = numerical_gradient(loss_W, self.params['W1']) grads['b1'] = numerical_gradient(loss_W, self.params['b1']) grads['W2'] = numerical_gradient(loss_W, self.params['W2']) grads['b2'] = numerical_gradient(loss_W, self.params['b2']) return grads def gradient(self, x, t): # forward self.loss(x, t) # backward dout = 1 dout = self.lastLayer.backward(dout) layers = list(self.layers.values()) layers.reverse() for layer in layers: dout = layer.backward(dout) # 设定 grads = {} grads['W1'] = self.layers['Affine1'].dW grads['b1'] = self.layers['Affine1'].db grads['W2'] = self.layers['Affine2'].dW grads['b2'] = self.layers['Affine2'].db return grads