软件开发规范
我们在开发程序的时候,要让程序看起来优雅简洁,让操作代码和阅读代码的人一目了然,并且便于我们操作管理。
所以我们在编写代码的时候就会用到模块的概念,而我们的开发规范就是把具有不同功能的模块进行分类,放在对应的文件夹中,这样就达到
了我上述所说的目的。
如下图所示:
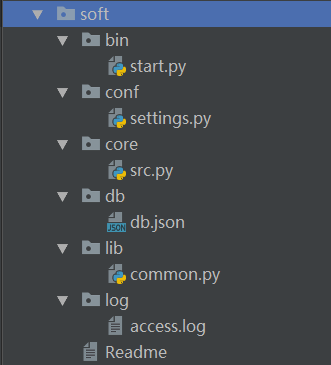
通常我们会把一个程序放在一个大的根目录文件夹中,下面的子文件就是各种不同的功能模块,例如配置文件里面就存入配置类型的模块,主要功能模块放一个文件,还有一些附加在程序上面的如日志、时间等模块。还有固定的诸如bin是作为执行程序文件,最后还要加上对这个程序的功能及介绍的文本。
这样我们一个简单的程序模式就搭建好了,然后我们再一步完善各个文件所要达到的功能。
目录详细的中文释义:
1、bin:启动目录,里面只需要有一个启动程序即可,所有文件的启动都由这里开始
2、conf:配置目录,里面是关于程序运行的所有配置文件,例如路径配置,日志配置等
3、core:主体目录,程序的主体架构,所有的核心逻辑
4、db:文件目录:在程序运行当中需要用到的一些文件
5、lib:工具目录,常用的工具,模块
6、log:日志目录,所有的日志文件
7、readme:关于程序的介绍(相当于说明书)
还有一件我们前期就要做的事情,就是把项目加到环境变量中,因为以后我们的程序都是给用户使用的,所以不能把路径固定死了(我们并不知道用户想使用什么文件路径),这里我们要用到
logging模块
logging模块的配置
"""
logging配置
"""
import os
import logging.config
# 定义三种日志输出格式 开始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]'
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s'
# 定义日志输出格式 结束
logfile_dir = os.path.dirname(os.path.abspath(__file__)) # log文件的目录
logfile_name = 'all2.log' # log文件名
# 如果不存在定义的日志目录就创建一个
if not os.path.isdir(logfile_dir):
os.mkdir(logfile_dir)
# log文件的全路径
logfile_path = os.path.join(logfile_dir, logfile_name)
# log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {},
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
},
},
}
def load_my_logging_cfg():
logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置
logger = logging.getLogger(__name__) # 生成一个log实例
logger.info('It works!') # 记录该文件的运行状态
if __name__ == '__main__':
load_my_logging_cfg()
logging配置文件
logging模块的五个级别:
CRITICAL = 50 #FATAL = CRITICAL ERROR = 40 WARNING = 30 #WARN = WARNING INFO = 20 DEBUG = 10 NOTSET = 0 #不设置
logging模块的对象
#logger:产生日志的对象 #Filter:过滤日志的对象 #Handler:接收日志然后控制打印到不同的地方,FileHandler用来打印到文件中,StreamHandler用来打印到终端 #Formatter对象:可以定制不同的日志格式对象,然后绑定给不同的Handler对象使用,以此来控制不同的Handler的日志格式
默认级别为warning,默认打印到终端
import logging
logging.debug('调试debug')
logging.info('消息info')
logging.warning('警告warn')
logging.error('错误error')
logging.critical('严重critical')
'''
WARNING:root:警告warn
ERROR:root:错误error
CRITICAL:root:严重critical
'''
为logging模块指定全局配置,针对所有logger有效,控制打印到文件中
可在logging.basicConfig()函数中通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
#格式
%(name)s:Logger的名字,并非用户名,详细查看
%(levelno)s:数字形式的日志级别
%(levelname)s:文本形式的日志级别
%(pathname)s:调用日志输出函数的模块的完整路径名,可能没有
%(filename)s:调用日志输出函数的模块的文件名
%(module)s:调用日志输出函数的模块名
%(funcName)s:调用日志输出函数的函数名
%(lineno)d:调用日志输出函数的语句所在的代码行
%(created)f:当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d:输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s:字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d:线程ID。可能没有
%(threadName)s:线程名。可能没有
%(process)d:进程ID。可能没有
%(message)s:用户输出的消息
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
#========使用
import logging
logging.basicConfig(filename='access.log',
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=10)
logging.debug('调试debug')
logging.info('消息info')
logging.warning('警告warn')
logging.error('错误error')
logging.critical('严重critical')
#========结果
access.log内容:
2017-07-28 20:32:17 PM - root - DEBUG -test: 调试debug
2017-07-28 20:32:17 PM - root - INFO -test: 消息info
2017-07-28 20:32:17 PM - root - WARNING -test: 警告warn
2017-07-28 20:32:17 PM - root - ERROR -test: 错误error
2017-07-28 20:32:17 PM - root - CRITICAL -test: 严重critical
part2: 可以为logging模块指定模块级的配置,即所有logger的配置
Logger与Handler的级别
logger是第一级过滤,然后才能到handler,我们可以给logger和handler同时设置level,但是需要注意的是
Logger is also the first to filter the message based on a level — if you set the logger to INFO, and all handlers to DEBUG, you still won't receive DEBUG messages on handlers — they'll be rejected by the logger itself. If you set logger to DEBUG, but all handlers to INFO, you won't receive any DEBUG messages either — because while the logger says "ok, process this", the handlers reject it (DEBUG < INFO).
#验证
import logging
form=logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',)
ch=logging.StreamHandler()
ch.setFormatter(form)
# ch.setLevel(10)
ch.setLevel(20)
l1=logging.getLogger('root')
# l1.setLevel(20)
l1.setLevel(10)
l1.addHandler(ch)
l1.debug('l1 debug')
json与pickle模块
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。(其实就会序列化和反序列化)
1 import json 2 x="[null,true,false,1]" 3 print(eval(x)) #报错,无法解析null类型,而json就可以 4 print(json.loads(x))
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
为什么要序列化?
1:持久保存状态
需知一个软件/程序的执行就在处理一系列状态的变化,在编程语言中,'状态'会以各种各样有结构的数据类型(也可简单的理解为变量)的形式被保存在内存中。
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。
在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
具体的来说,你玩使命召唤闯到了第13关,你保存游戏状态,关机走人,下次再玩,还能从上次的位置开始继续闯关。或如,虚拟机状态的挂起等。
2:跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
如何序列化之json和pickle:
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
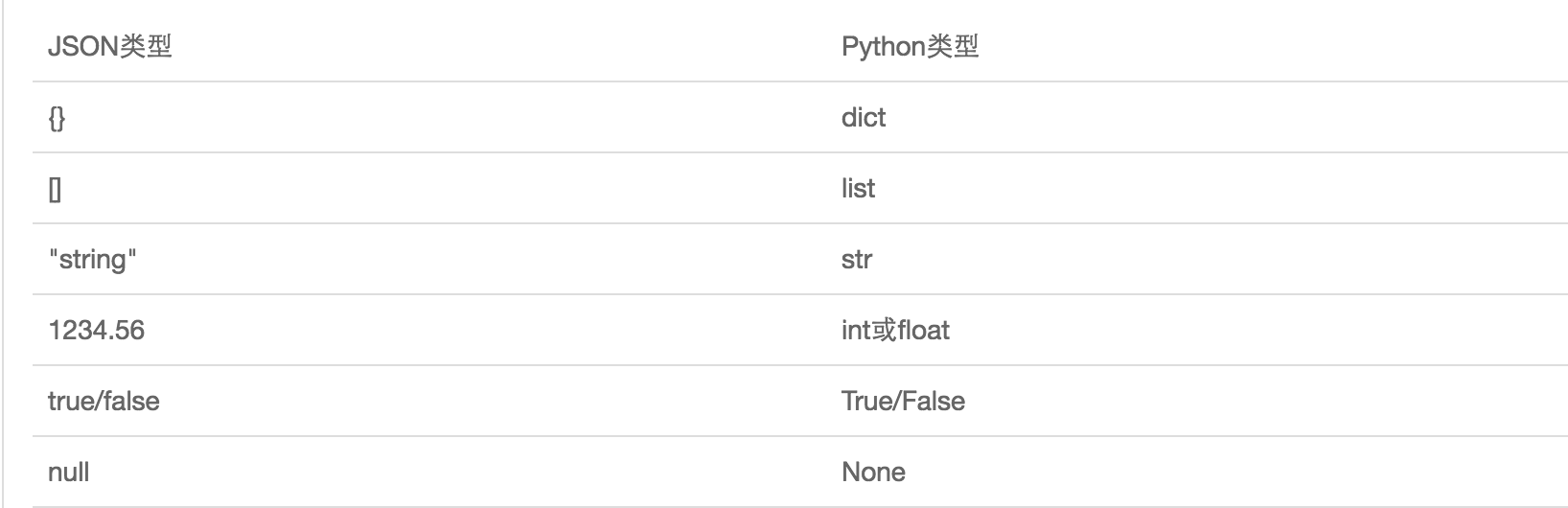
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
import json
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=json.dumps(dic)
print(type(j))#<class 'str'>
f=open('序列化对象','w')
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()
#-----------------------------反序列化<br>
import json
f=open('序列化对象')
data=json.loads(f.read())# 等价于data=json.load(f)
pickle
import pickle
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=pickle.dumps(dic)
print(type(j))#<class 'bytes'>
f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #-------------------等价于pickle.dump(dic,f)
f.close()
#-------------------------反序列化
import pickle
f=open('序列化对象_pickle','rb')
data=pickle.loads(f.read())# 等价于data=pickle.load(f)
print(data['age'])