作者:关中旭
小T导读:陕西煤业股份有限公司(股票代码:601225),是陕西煤业化工集团有限责任公司煤炭资产唯一上市平台。陕煤在煤矿智能化发展上成绩斐然,开创了首个全国智能化无人开采工作面,首个全国智能化掘进机器人。不仅是国内采煤新方式的先河,更填补了煤矿开采技术的空白。

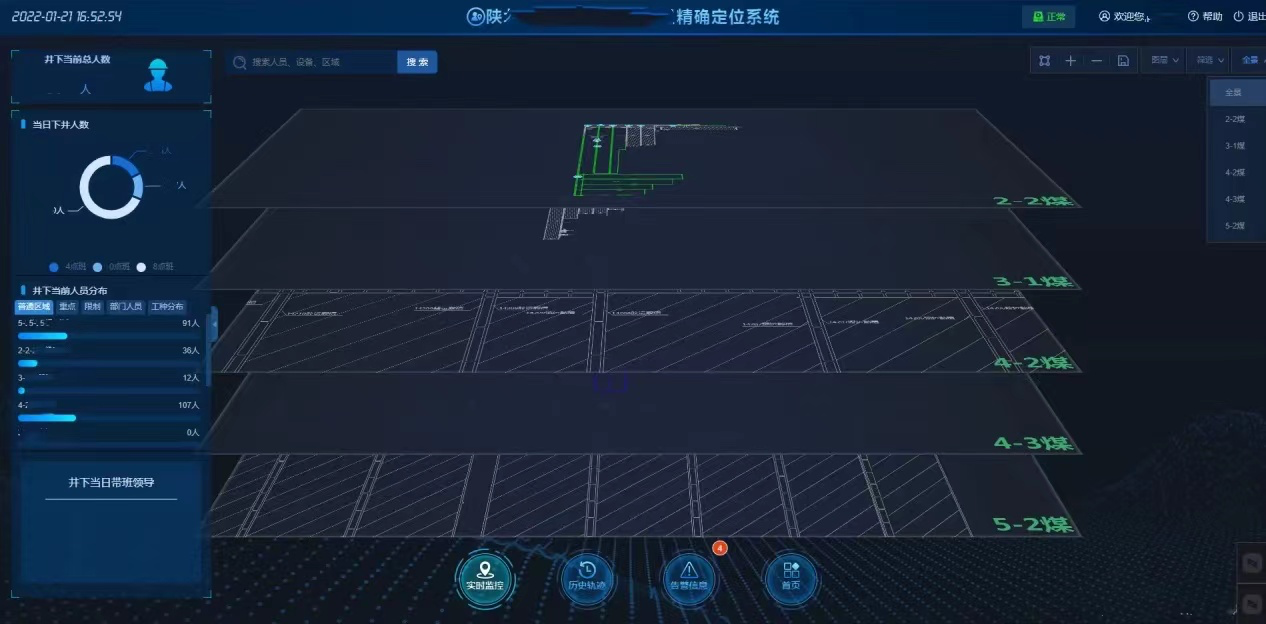
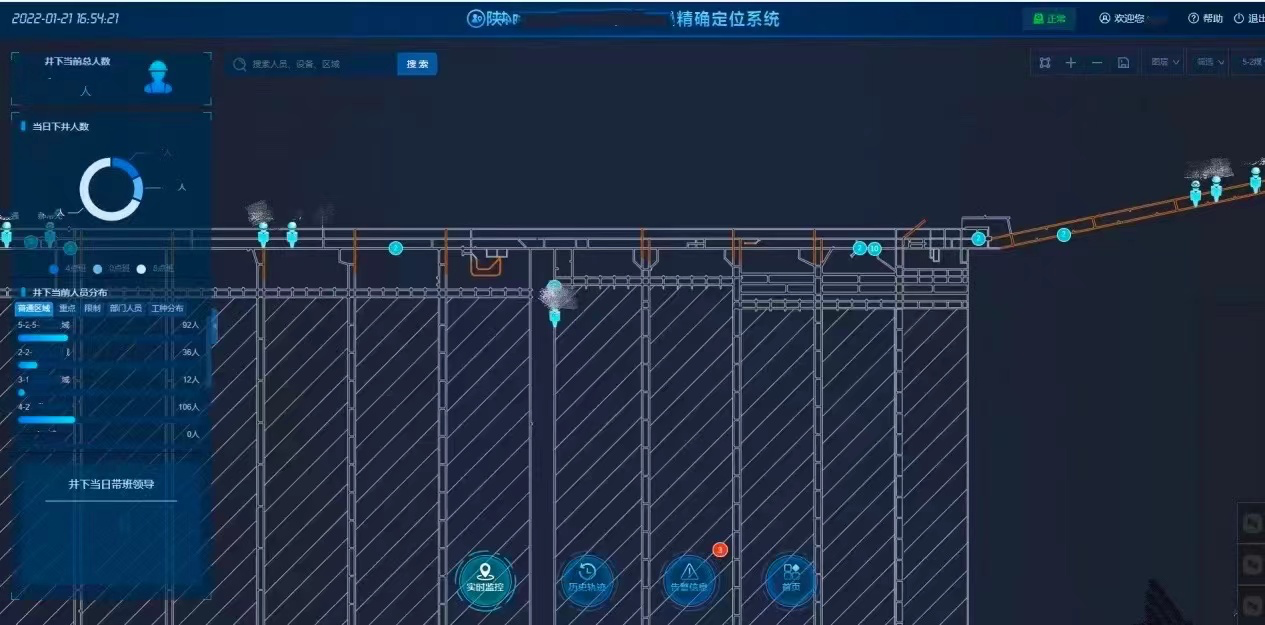
为实现煤矿企业数字化生产管理,提高煤矿企业生产安全性、扩展煤矿企业管理手段及管理思路,陕煤开发团队考虑将煤矿企业人员、车辆、设备、环境参数等各类基础数据,进行统一存储和智能分析决策,在此背景下打造全矿井数字化平台,实现了煤矿企业井下人员、胶轮车及电机·车位置监控、井下各类设备状态监控、井下各类传感器数据监控、井下位置地点的告警分析及事件联动。
此平台的搭建意义在于打通煤矿生产环境中各类单一子系统之间的数据壁垒,实现各类子系统数据之间的互联互通。在实现路径上,平台底层基于标准TCP/UDP协议接入公司自研硬件设备,并通过定制化的协议转换模组接入其他非标的设备通信协议,将上传数据进行归集入库存储并通过大数据分析平台进行驱动分析,最后根据业务具体情况生成数据统计与驱动结果。
一、技术选型
以位置数据为例,井下人员、车辆佩戴安装定位设备后将基于井下网络进行位置数据的实时上传,人员默认上报周期为1秒,车辆默认为0.5秒。在原有单系统项目中,由于初期系统容量较小且硬件设备上传周期较大,所以采用了传统SQL Server数据库来进行轨迹数据存储。但随着后续项目迭代,硬件设备定位精度提高且上报周期缩短,也导致数据库存储压力增大。
为解决大数据量存储问题,我们先是考虑在数据接收端增加大量数据过滤算法,对原始数据进行预筛来减少最终入库数量,在数据库侧则采用增加分库分表的策略,那在数据查询端就需要对分库分表进行大量的查询语句优化。这样一来,整体项目不仅复杂度较高,而且后续维护类工作量巨大。
在平台设计阶段,一是鉴于上述失败经验,其次我们也考虑到不管是位置数据还是传感器数据,虽然数据载体不一样,但它们都是包含时间戳的序列数据,且数据存储固化后很少再有需要更新的业务场景,采用时序数据库来存储这类数据再合适不过了。基于此,我们开始进行选型调研,对几类时序数据库进行了综合比较:
- OpenTSDB
基于HBase的时序数据库实现,支持集群横向扩展,但是部署及运维成本较高,且提供的查询函数较少,不适合后续查询业务的扩展。 - TDengine
早在TDengine开源之初我们就对其有所关注。对一个新兴基础开源项目,稳定性一直是我们衡量的重要标准,TDengine在后续开源的2.X版本中不仅增加了集群模块且稳定性也大幅提高,同时其SQL语句与传统关系型数据库语句相似,部署及维护相对简单,社区环境很好,也有企业合作模式。 - InfluxDB
InfluxDB在开源时序库领域长期占据TOP1的位置,社区比较活跃且生态建设也挺好。但由于集群模块没有开源,不适用公司产品的高可用要求。
综合上述几类时序数据库的优缺点,最终我们决定采用TDengine作为本项目基础数据的存储方案。
二、建库建表
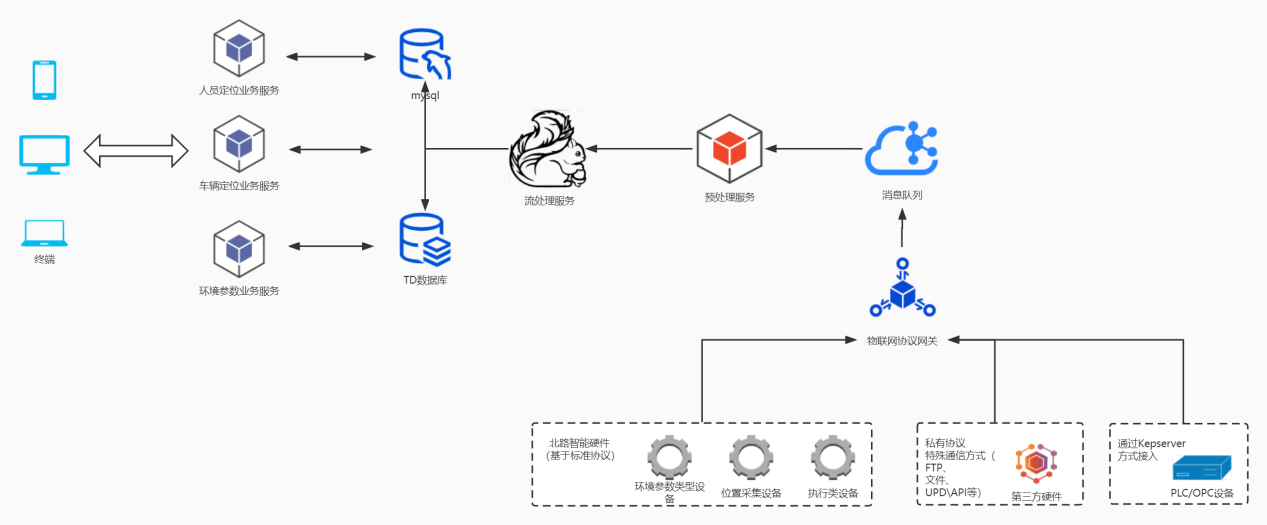
- 基于TDengine的产品架构图搭建如下:
- 建模思路
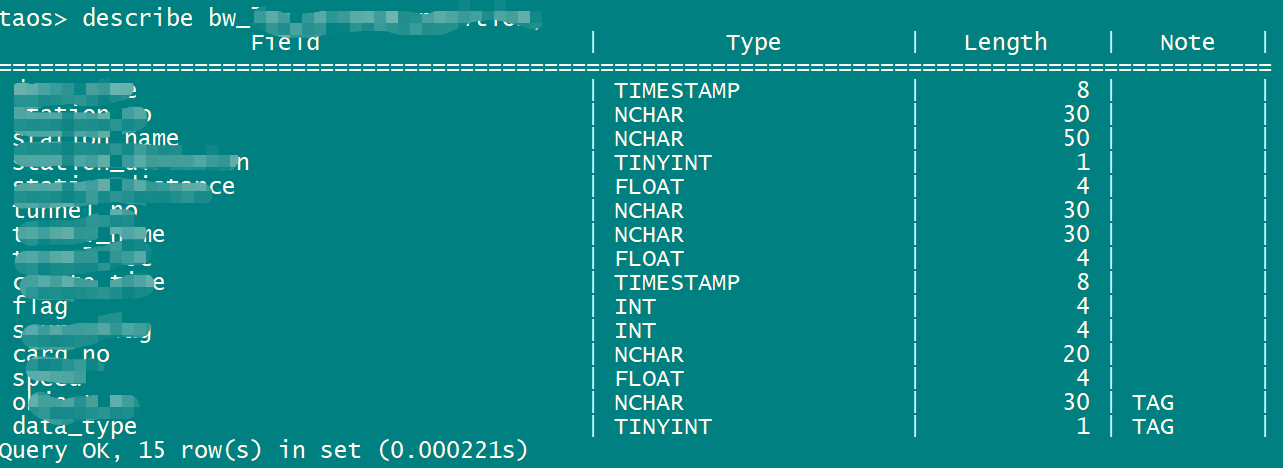
在定位业务时可以细分出人员、车辆等不同的定位对象,尽管数据类型不同,但定位相关数据字段均一致,因此定位数据使用一张超级表进行管理即可。在TDengine超级表内数据类型及各个数据对象编号将作为tag进行区分,在查询业务时使用超级表并关联tag字段进行查询。
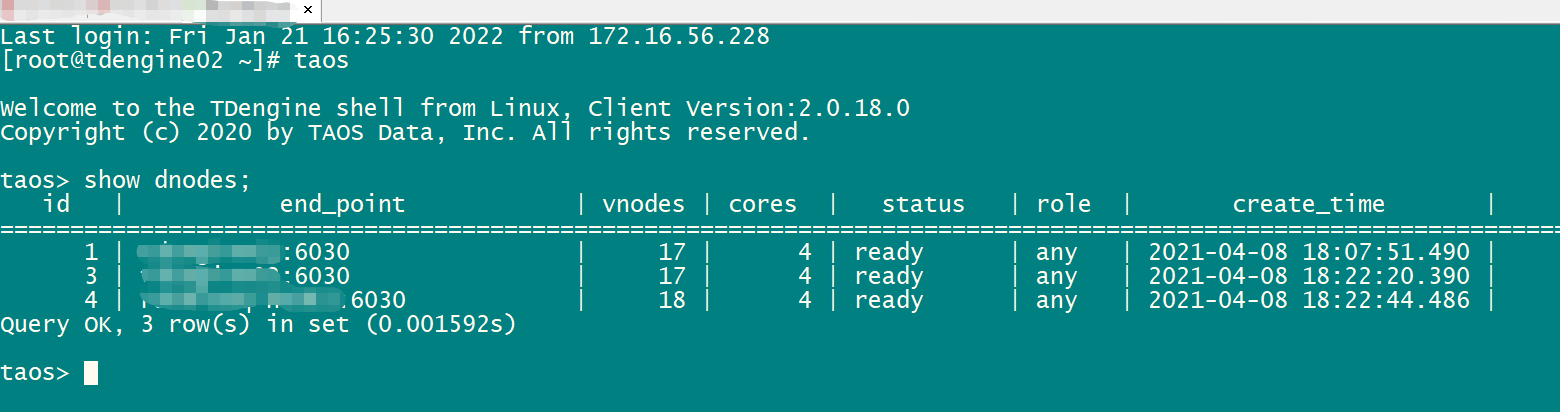
从我们的实际业务出发,具体建表思路如下:


三、落地效果
最终落地时项目采用了3个节点的集群环境,定位设备采用超级表进行管理,将数据标签及数据类型作为tag区分各类定位设备。每个定位设备采用子表存储,实际项目已包含2万多个定位设备。从写入性能到查询性能均大幅满足现场实际需求:总计定位数据量超过11亿条,数据压缩后TDengine数据目录占用磁盘大约12G,整体压缩率可以达到3/100。
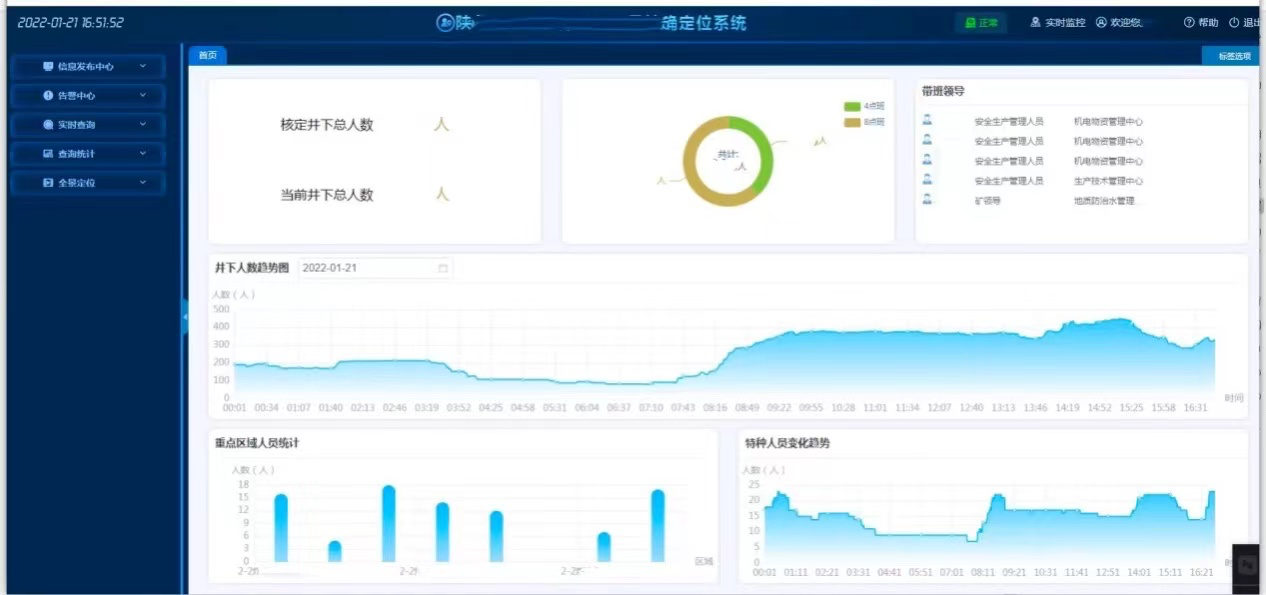
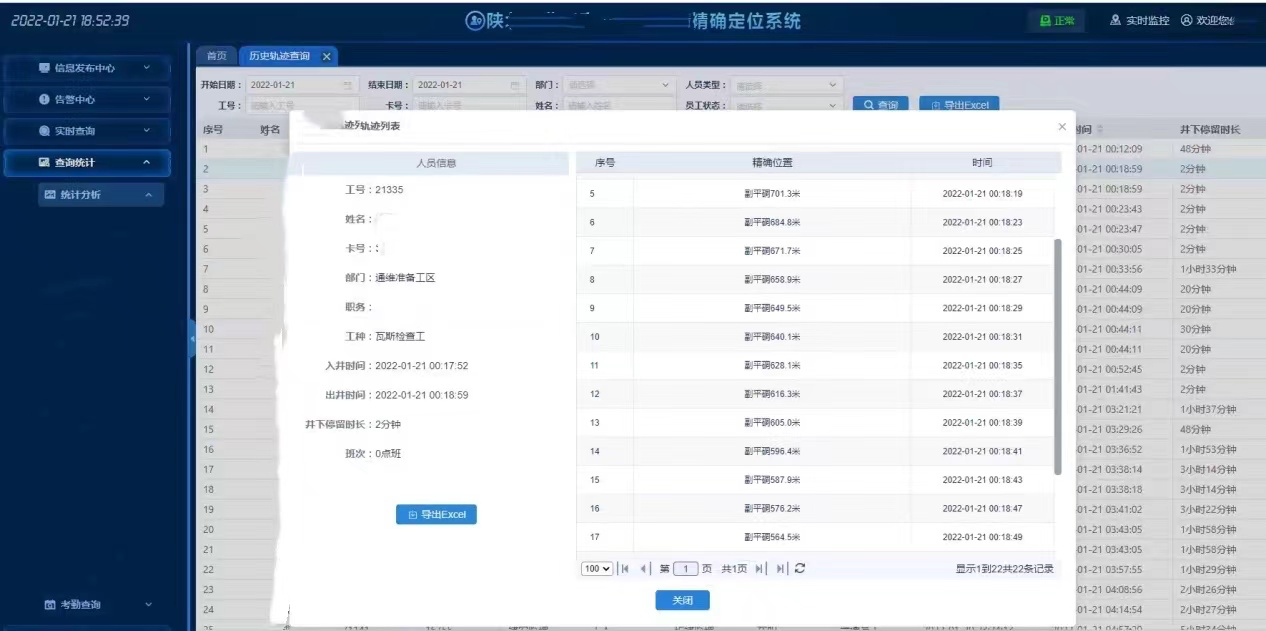
下图示例为项目中人员与车辆定位实际使用场景,基于TDengine数据库引擎,对井下的人员、车辆数量以及位置进行实时统计与展示。
四、未来规划
随着项目的不断推进直到实施落地,我们也见证了TDengine的几次大版本更新,目前集群整体运行情况相对稳定,性能和成本管控也达到了我们的预期。为了帮助TDengine能够实现更好地发展,在此也为其提出几点优化建议:
- 目前TDengine在陕煤使用的监控功能还较为简单,希望后续版本升级过程中能够优化集群环境监控相关的功能。
- 目前项目在使用JDBC驱动时,是通过客户端连接TDengine的。随着版本升级,运维工作量较高,需要同步升级服务器和客户端,且JDBC驱动升级的话还需要同步升级对应服务,步骤相对繁琐,希望在接下来的版本中能加以改善。
想了解更多TDengine的具体细节,欢迎大家在GitHub上查看相关源代码。