
作者:黄培健,陈驰|叁零肆零科技有限公司。
小 T 导读:上海叁零肆零科技有限公司致力于能源(气和热)的数字化转型,以现阶段压力和流量监测物联为切入,结合企业已有的信息化数据,利用物联技术解决能源企业的安全运行痛点,助力其提升智慧运营效率。
依托数字孪生和人工智能算法模型,我们构建了实时反映管网实际运营工况的瞬态的仿真平台。该平台致力于为能源企业提供包括客户认知、需求负荷分析、管网状态监控和优化、多工况计算、气(热)源匹配、通路寻优等一系列数据服务。下图为平台实际运作场景画面。
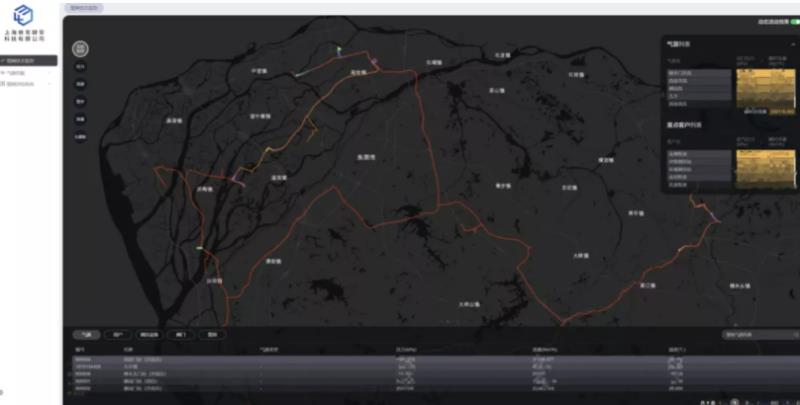
在此项目中,构建数字孪生的主要数据来源于以下两个地方:
- 物联数据:物联设备每 5 分钟上报一次物联数据;
- 仿真数据:依托于大量物联设备的接入,将工况数据进行实时对齐上传做仿真求解以此得到仿真数据。
在项目即将投入研发测试之际,我们却发现了一些会影响到项目正常运作的问题——两种数据类型都非常庞大,此前常用的数据库难以支撑如此庞大数据量的存储查询等操作。带着这个问题,我们将目光转移到当前市面上的数据库产品上,试图从中筛选到最适合本项目的数据库。
波折重重的数据库选型
从项目涉及到的数据类型来看,物联数据具有典型的时序数据特点,量大但不会变化,仿真数据的计算结果量同样很大。这两类数据都需要快速的存储、实时的查询响应,但相比于存储来讲,查询并不会过于复杂。
基于以上背景需求,我们开始进行数据库产品选型。
首先尝试使用的是非关系数据库 MongoDB,在通用数据库中 MongoDB 已经是佼佼者了,但是查询和存储效率仍然都没有达到我们的预期。在思考过后,我们从数据类型出发缩小数据库选型范围,最终决定从时序数据库中进行选择。
我们率先将目光锁定在当前市面比较流行的时序数据库 InfluxDB 上,一套测试下来发现,尽管业务需求将将能够满足,但 InfluxDB 的运维成本太高,而且其集群版并未开源,使用成本不低,因此 InfluxDB 也排除在我们的选型范围之外。
一次偶然的机会,我们了解到了时序数据库 TDengine,发现这一款数据库性能胜于 InfluxDB 的同时,甚至把集群也做了开源,方便进行水平扩展,且在成本管控上也达到了最优的状态,轻量化、类 SQL 的结构设定大幅降低运维和学习成本。在众多优点的推动下,我们便尝试将 TDengine 投入测试使用。
非常高兴的是,期间我们在 TDengine 的官方社群中获得了及时专业的技术支持,最终顺利地把开源版 TDengine 应用到了项目开发中。而 TDengine 也没有让我们失望,成功上线后其在运行上十分高效稳定。
具体场景与配置
目前我们选用的 TDengine 版本是 2.2.0.1,单机版暂时毫无压力,但出于业务扩展的需求,同时也在筹备单机横向拓展为集群的工作。
在实际操作中,当前服务器配置是“24G 内存 + 12 核 3.60GHzCPU +机械硬盘”。如下图所示,库中共有子表 20000+,超级表 6 张,其中常用的有 4 张表。数据保留日期为 10 年,数据周增幅大概为 1000 余万行。


根据涛思数据提供的资料,我们通过合理的配置参数让数据库的 Vnode 数量恰好等于计算机的 CPU 核数,从而可以充分利用计算机性能,顺利完成环境搭建。
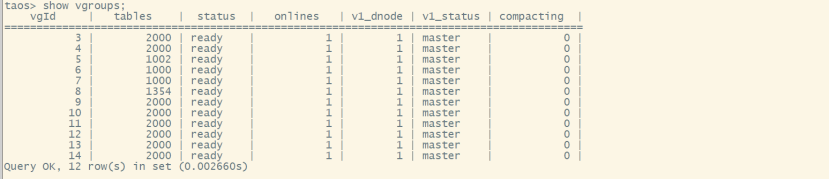
千万级别数据量的查询效果
超级表 computing_result 保存了所有仿真计算的结果,单表总计 21 列,单行长度 1.8k,当前数据量为千万级别,是我们的主要查询对象——
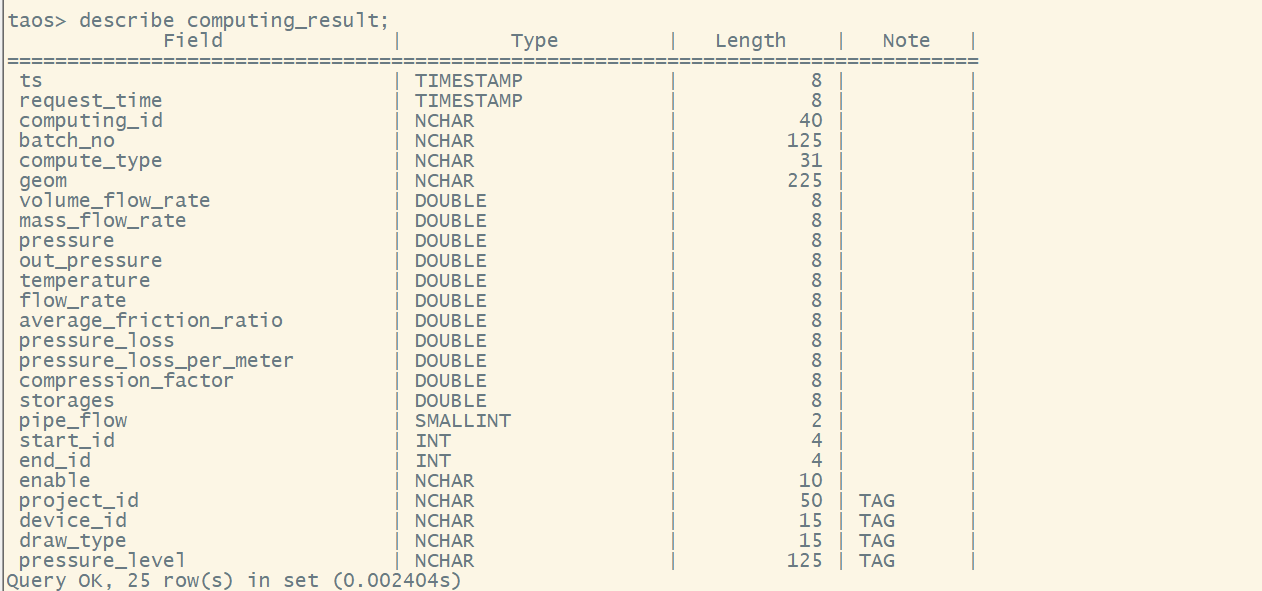

针对以上的查询数据,具体的查询效果如下:
1. 查询某些设备的所有仿真计算结果为 0.09 秒,代码示例如下:
select * from slsl_digital_twin.computing_result r where r.batch_no in ( 'c080018_20211029080000' ) and r.device_id in ( '347444', '73593', '18146', '235652', '350382' );

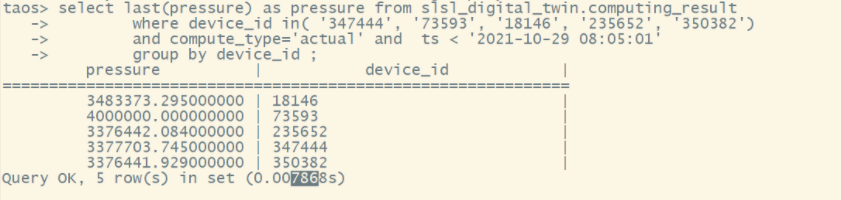
2. 查询某些设备在一定时间范围内的,最新的压力数据耗时 7.8 毫秒。
3. 根据区域 id 分组,查询该区域下不同设备的最新数据,耗时 9 毫秒(由于 2.1 版本增加了嵌套查询功能,我们得以更好地实现相对复杂的逻辑去得到查询结果)。代码示例如下:
select sum(pressure) as pressure, sum(flow) as flow, sum(temperature) as temperature,last(on_off) as onOff,gis_id from (select last(pressure) as pressure, last(flow) as flow, last(temperature) as temperature,last(on_off) as on_off from slsl_digital_twin.enn_iot where in_out_flag = 'OUT' and gis_id in( '347444', '73593', '18146', '235652', '350382') group by device_id,gis_id ) group by gis_id;

值得一提的是,在实现高效的存储查询性能下,TDengine 占用的存储空间不足 500MB。但事实上,仅仅 computing_result 单张超级表的实际数据量理论上就应为(82+(40+125+31+225)4+811+2+42+10)字节*12409408 行数,即 21GB 左右,更不用提把静态数据抽取出来做成内存里的标签大幅度减少了原数据量。
但由于 nchar 类数据中有部分 null 值,在本文中我们无法精准计算压缩率。即便如此,TDengine 的表现也已经令我们足够惊艳了。

写在最后
未来,随着我们接入更多城市的管网仿真、爆炸辐射、泄漏预警等计算模型,产生的数据量将会达到 10 亿+,子表数量也会达到数千万级。TDengine 即将上线的 3.0 版本可以轻松支持亿级别的表数量,这一点让我们更加期待未来和 TDengine 的深度合作,同时也对 TDengine 抱以更大的信心。在合作的过程中,我们也会继续探索如何将 TDengine 应用于更多的业务场景,以更好地满足我们的各类仿真计算环节的业务需求。
关于作者
黄培健,叁零肆零架构师。目前负责公司数字孪生项目和公司整体技术架构。
陈驰,叁零肆零高级工程师。目前负责公司数字孪生项目整体开发。