当我们打开计算机里的记事本,记下了新学的英文单词的时候,你可曾想过英文单词是如何保存到计算机里呢?我们都知道计算机是二进制体系,最底层一定存储的是二进制信息,那么问题来了,这些英文字符是如何转换到二进制的呢?这里就采用了字符编码技术了,就是我们常说ASCII编码。ASCII 全称:American Standard Code for Information Interchange 美国信息交换标准代码。为什么是美国制定的标准?因为计算机最早是美国人发明的,他们最早遇到如何将字符存入计算机的问题,所以理所当然也就是美国人发明出了ASCII码了。
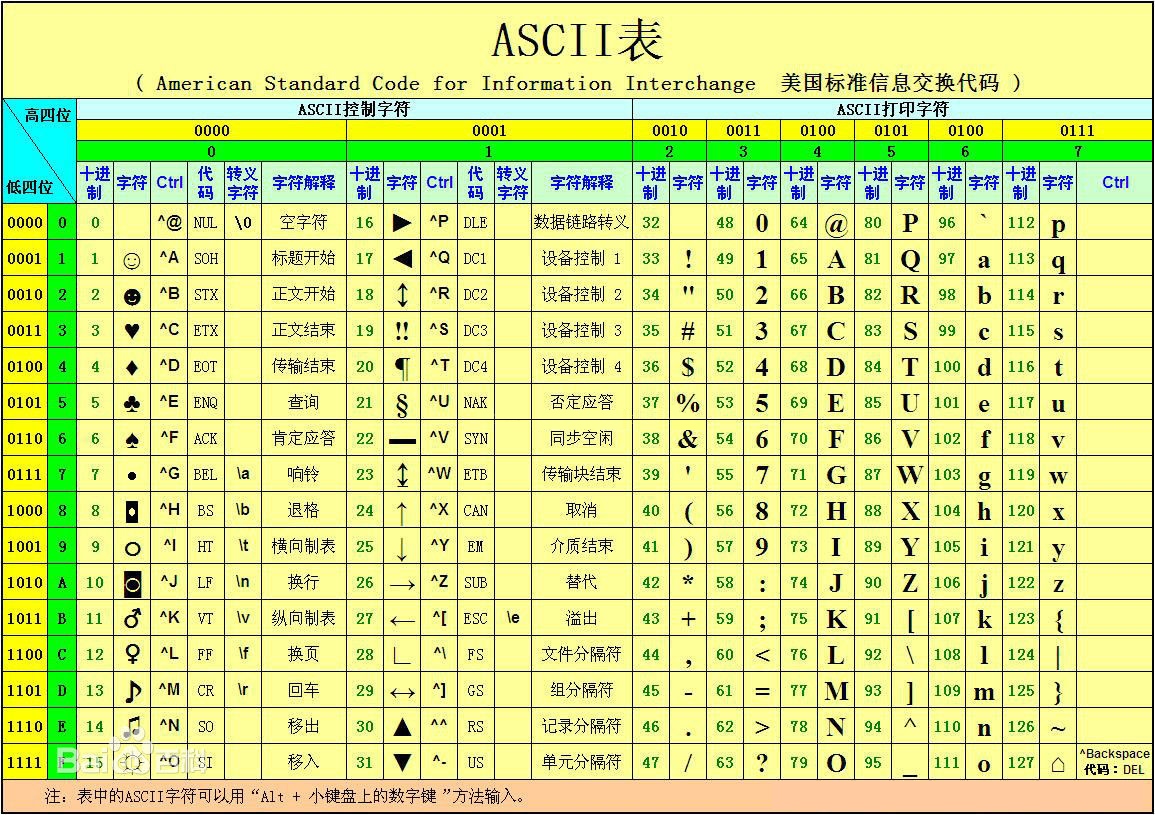
下面一起看一下ASCII码都有什么特点,以下只是部分摘抄了ASCII
二进制 十进制 缩写/字符 解释0000 0000 0 NUL(null) 空字符0000 1101 13 CR 回车键0100 0001 65 A 大写字母A0111 1111 127 DEL(delete) 删除
从以上列表中,我们得出了ASCII码的几个特点:
(1)总共定义了128个字符,从十进制的0开始一直到127;
(2)这些字符包括了以下几类:大写字母A至Z,小写字母a至z,数字0至9,还有键盘上一些特殊符号(!@#$~),最后包括了控制字符,如上表中的回车键或删除键等。
(3)二进制的最高位为0,只用了7位存储信息,因为2=128,所以存储了128个字符。
下面再简单介绍下位(bit)、字节(Byte)的概念,位表示的是二进制位,一般称为比特,是计算机运算和存储的最小单位。字节是计算机中数据处理的基本单位。1个字节等于8个比特(1Byte=8bit),比字节大的单位有KB、MB、GB、T ,它们间换算关系为:1KB=1024B 1MB=1024KB 1GB=1024MB 1T=1024GB。
现在再来看ASCII码表,假设用8位存储的话,二进制则表示为1111 1111,这个数字换算成十进制是255,这就说明用8位存储的话,可以存储0-255,总共存256个信息,这是因为2=256。综上所述,说明7位可以存储128个信息,最大值127,8位可以存储256个信息,最大值255。在这里为什么会专门讲这个,因为我们编程的时候经常会遇到存储的问题,所以这些基本概念一定要清楚。还有个问题就是关于控制字符,控制字符都是不可见的字符,但却是我们编程中经常使用的。比如用户敲了回车键,我们可以根据ASCII码得出该键的十进制为13,只要判断是否等于13就知道用户是否敲了回车键,如果等于13的话,则可以调用相应的计算机指令完成相应的功能。
当计算机进入中国后,发现一个最大的问题,就是我们的汉字没有办法存储到计算机中。于是,中国的科学家们就编制了一套中文字符编码,这个中文编码就是GB2312。GB2312 是 1980 年制定的中国汉字编码国家标准。共收录 7445 个字符,其中汉字 6763 个。GB2312 兼容标准 ASCII码,采用扩展 ASCII 码的编码空间进行编码,一个汉字占用两个字节,每个字节的最高位为 1。
在这里我们需要记住GB2312的两个特点:
(1)GB2312的第一个字节还是原来的ASCII编码;
(2)一个汉字占用了两个字节存储;
既然中国有中国的编码,同样日本、韩国等,只要有自己的语言文字,都会有一套自己的编码,这样我们在处理文字信息的时候,就会非常繁琐。于是,后来人们就想到了要统一编码,就好像人类交流的通用语言是英文一样,统一的编码就叫Unicode码。
Unicode码扩展自ASCII字元集,它为每种语言中的每个字符设定了统一并且唯一的二进制编码。Unicode 编码共有三种具体实现,分别为utf-8,utf-16,utf-32,其中utf-8占用一到四个字节,utf-16占用二或四个字节,utf-32占用四个字节。
我们在开发中应用的主要是utf-8,所以下面介绍下utf-8
utf-8使用1~4字节为每个字符编码:
(1)ASCIl字符还是原来的1字节编码。
(2)带有变音符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文等字母则需要2字节编码。
(3)汉字(包括日韩文字、东南亚文字、中东文字等)使用3字节编码。
(4)其他极少使用的语言字符使用4字节编码
当然字符编码不止我介绍的这三种,在这里主要是帮助初学者建立一个基本的概念。如果你觉得文章还不错,请帮忙转发给需要的朋友。
看完这个 再学习 下面的知识会比较容易