摘要:2022 年 8 月 5 日,2022 阿里云生命科学与智能计算峰会在北京望京昆泰酒店举行,阿里云高性能计算负责人何万青博士,带来了题为《阿里云大计算加速 HPC 与 AI 融合》的分享,以下是他的演讲内容整理,供大家阅览:

阿里云高性能计算负责人 何万青
人类历史上各种广谱药的发现,是一个漫长且靠运气的过程。新药的发现和制造往往需要十多年的时间,每年 FDA 能够批准上市的新药少之又少。
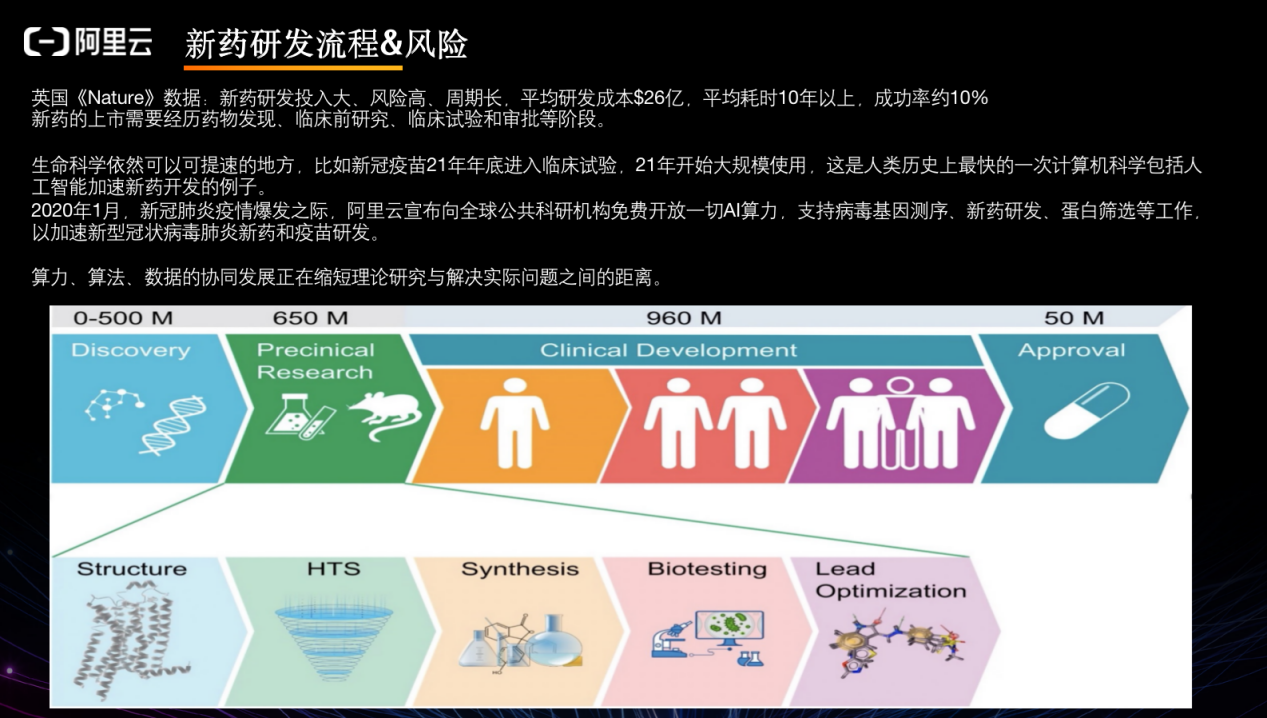
而新冠的爆发带来了一个重要契机,我们通过整合云上计算资源,第一时间帮到科研机构开展新冠研究,从而发现了云计算具备的独特优势。据报道,世界上前 20 大药厂 70% 的算力和研发都在往云上迁移。

在新冠疫情爆发初期,阿里云第一时间免费开放 AI 算力支持抗疫研发,支持科研人员围绕新冠病毒进行药物研究;其次,通过大数据进行公共医疗政策的研究,助力大数据系统、追踪系统以及决策系统;另外,向全世界开放阿里的科研抗疫平台,对接了来自 50 个国家 &地区的 33 个需求。
而这个契机也让我们意识到,AI 是一种即将爆发的新的 IT 技术、新的计算平台。
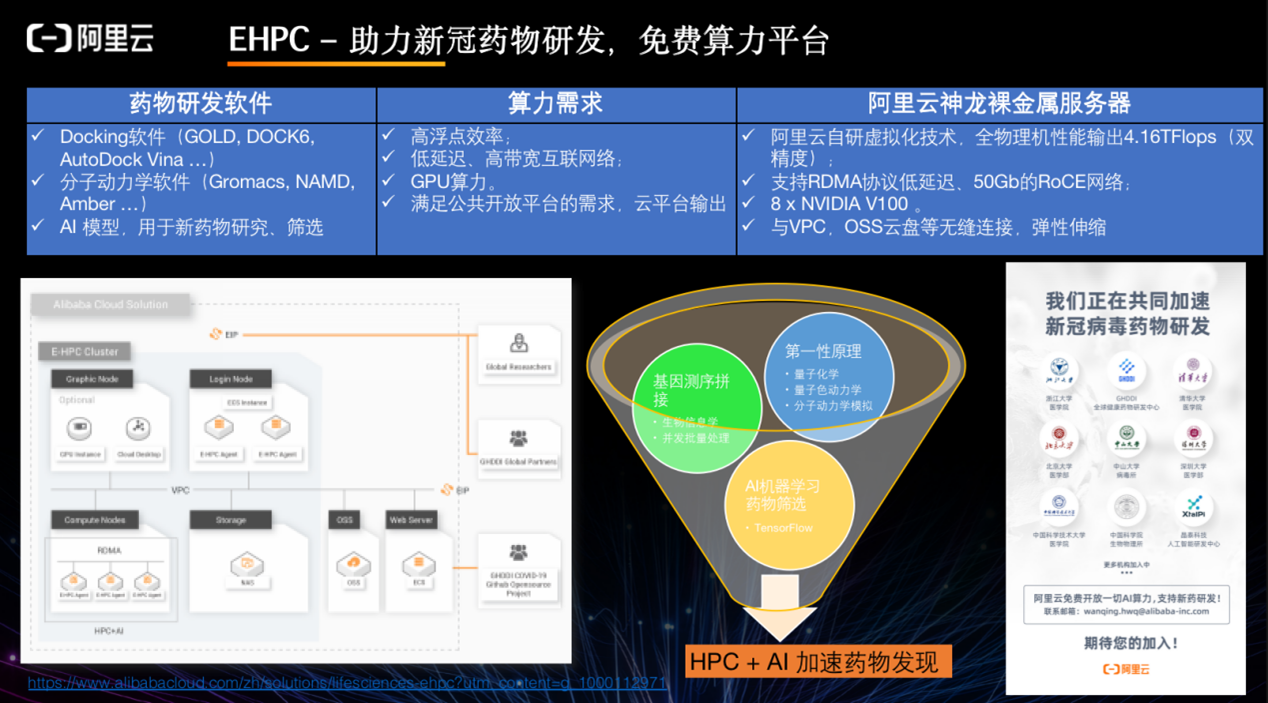
过去,高性能计算支持生命科学的发展,主要着力于科研和科研团队的培养,但并不明确会导向何种药物、何种结果。而现如今,此类需求非常明显,我们面对大量的数据库和化合物,需要对疾病和样本做分析、基因测序。
过去的应用分为两大类:第一类是基于第一性原理的分子动力学、量子色动力学等,比如分析细胞组成的分子之间的作用力、化合物之间的作用;第二类是面向精准治疗时的基因测序,同样需要非常大的算力,科学家需要解决的是机理和算法问题,但大规模的实现需要工程人员来解决,比如高通量测序。
最近几年发展最快的是 AI 算法,通过 AI 对大量数据进行筛查。而此过程需要解决的问题有:如何将 AI 算法和技术放在云超算平台上?大量的数据如何在云上进行传输?
总结来说,高性能计算在云上进行服务,需要解决以下线下超算的痛点:

① 弹性扩展难:实际业务中,往往难以预测突发情况的需求,因此,弹性伸缩十分必要。
② 可靠性不高:计算中心或物理集群规模扩大之后,无法保证百分百的稳定性,因此必然会出现重新计算的需求,针对此需求,云计算稳定的 SLA 之外,还实现了断点续算技术。
③ 性能瓶颈:云上计算突破了海量数据进行机器学习或筛查的 GPU 瓶颈,过去花费数周数月才能够完成的计算,如今可缩短为几天。
④ 成本挑战:过去,成本和算力难以兼得,自建超算中心往往 CAPEX 不低,且后续运维成本 OPEX 更大,难以实现。
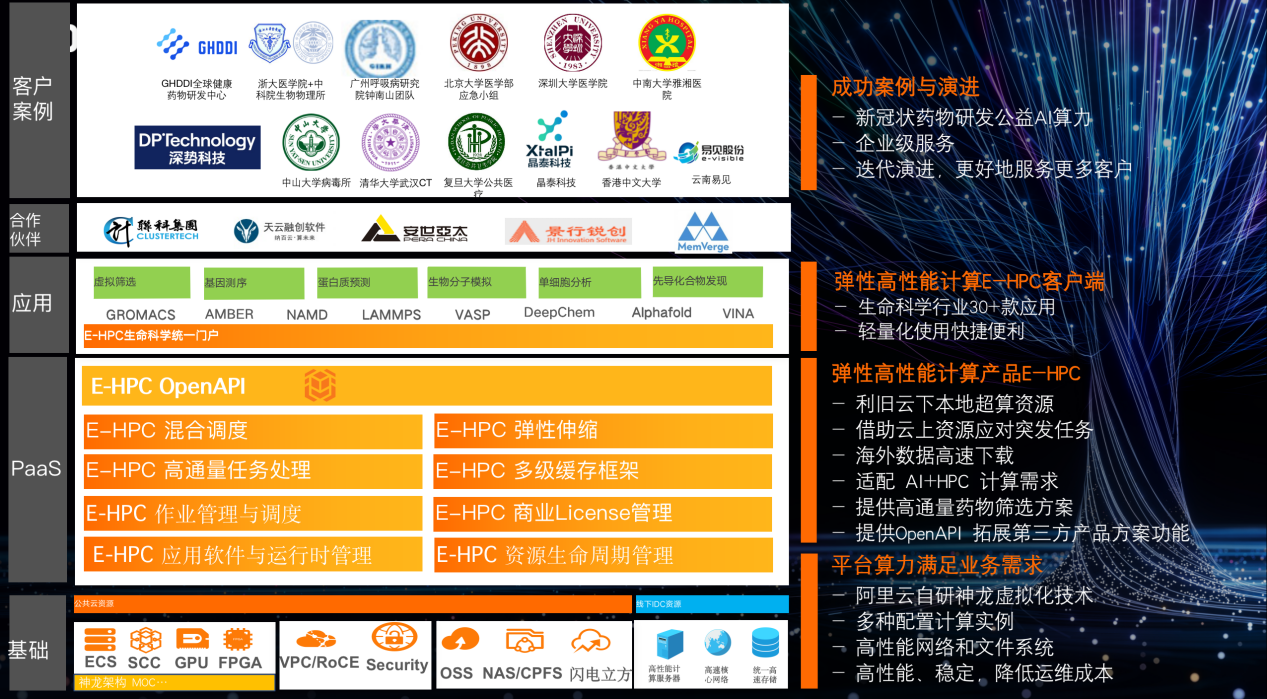
借助云平台,科学家和科研人员能够专心于自己专业内的工作,聚焦于应用。而应用这一层,科研人员将它作为软件放至云上,让更多的科研人员实现科研合作和服务共享。
阿里云最基本的能力是提供弹性的伸缩算力,在此之上,高性能计算最核心的部分是与伸缩算力耦合的并行作业调度,还需要支持 AI Framework。用户如果有自己的计算资源,可以通过混合调度在云上利用原有的计算资源。大部分科研人员对本地环境最熟悉,需要将它们的能力迁移至云上。此外,生命科学领域非常依赖于全世界的 NH 数据库,且需要高速互联,也可以通过阿里云的高速来实现。
HPC 应用是 Data go to compute,但 AI 是分布式、数量极大的 compute go to data 计算模式,有自己的生态,如何对两者进行结合?中国的软件公司依然不够发达,新产品、新发现难以在短时间内为人所知,受限于盗版问题和推广问题。但在云上可以实现 SaaS 化,通过 OpenAPI 将产品变为云上的服务。
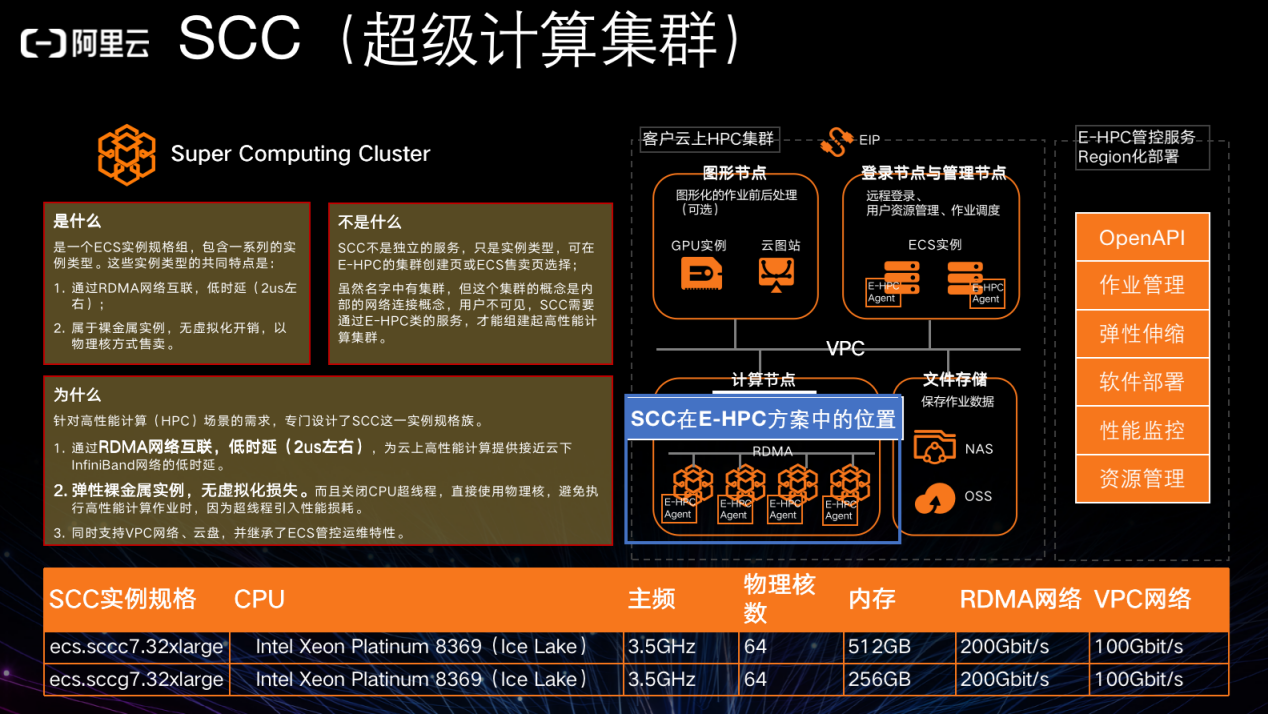
高性能计算里有两个很大的领域需要无限的算力,分别是地球物理和气象和生命科学。这就需要基于神龙的弹性裸金属超级计算集群 SCC 来提供了低延迟网络和并行文件系统的高性能集群。
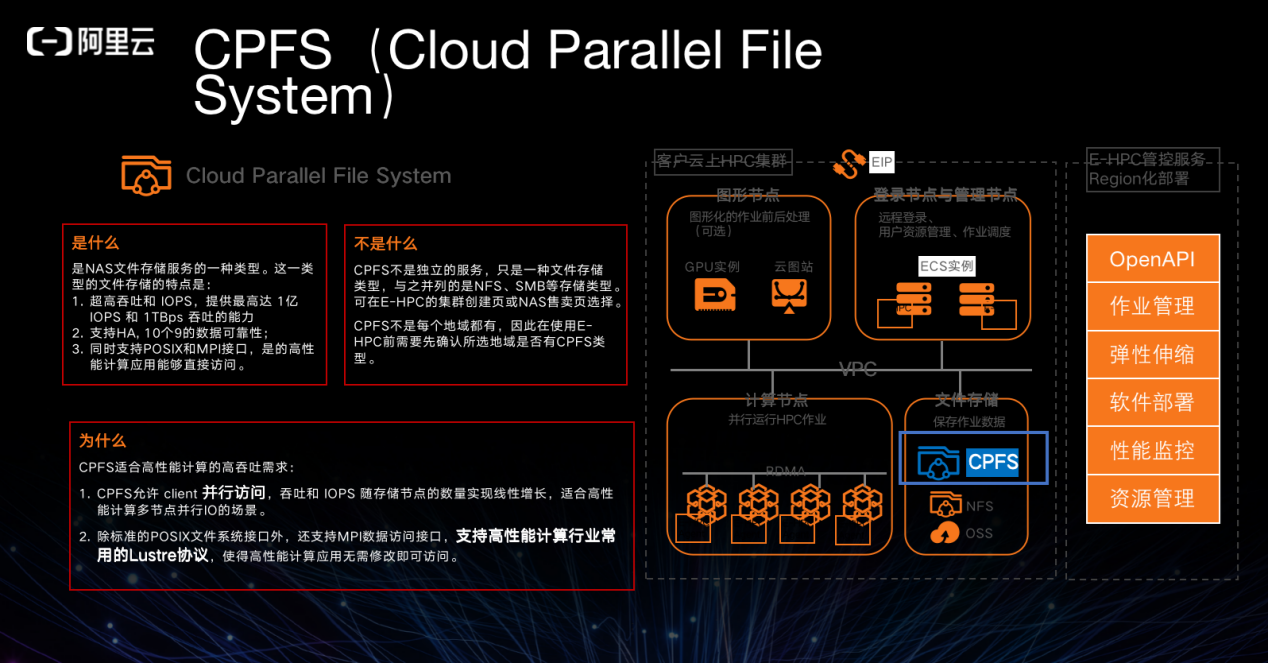
通过高性能计算推动实现了阿里云 CPFS 并行文件系统,提供了除了云上大数据类型的 HDFS 分布式存储,能够实现了大批量并行吞吐的需求。
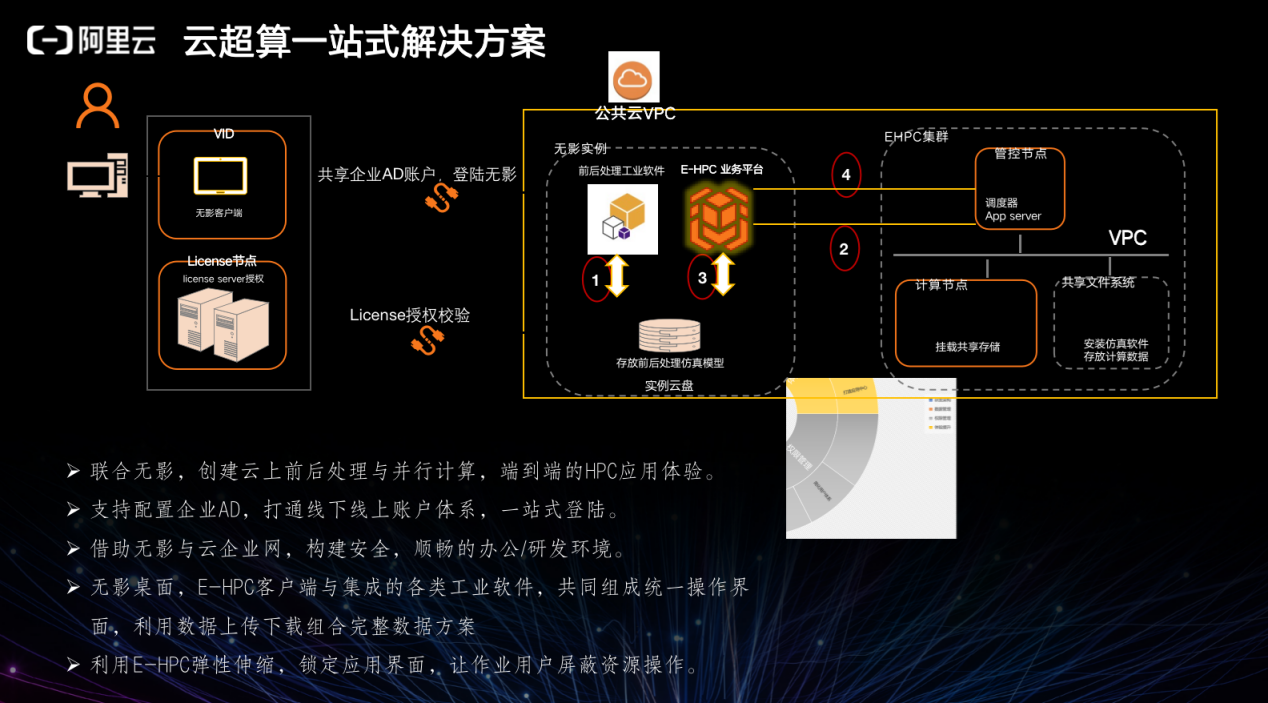
通过阿里提供的“无影”,可以访问任何端和云上的计算资源,包括但不限于 PC、手机、屏幕等,可以将公共云的操作、应用入口以及背后的集群资源管理整合在一处。一方面可以作为虚拟的桌面,另一方面也可以作为应用入口。
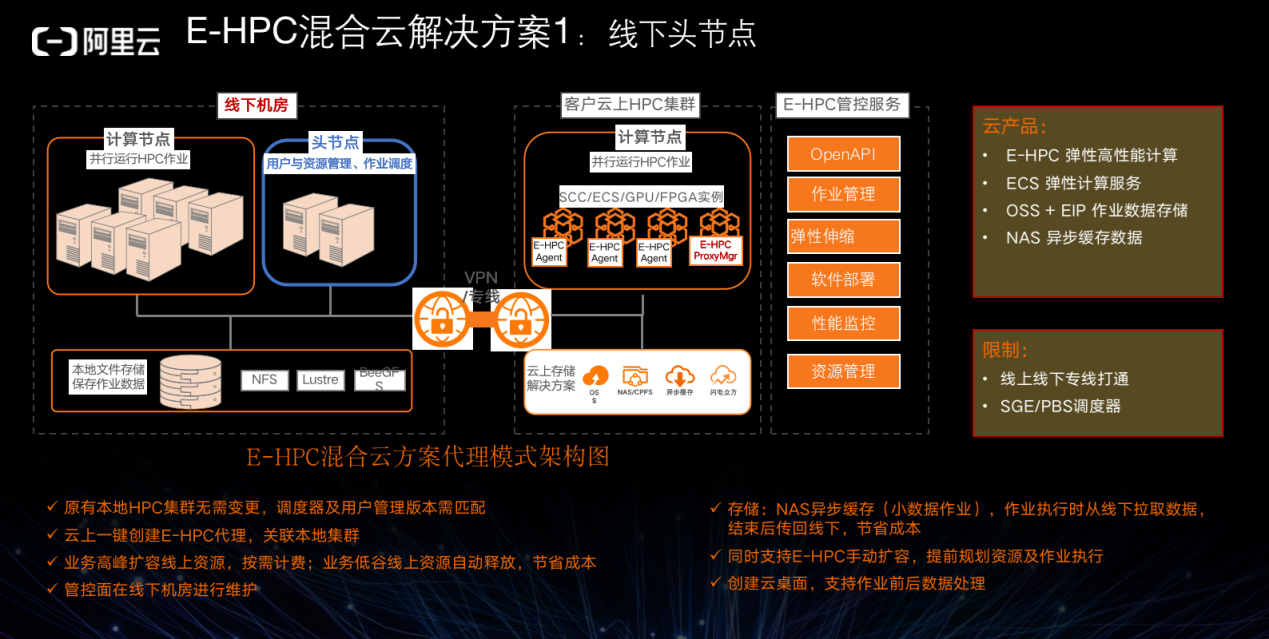
我们打通了云上云下,云下可以通过专线连至云上,头节点在线下,然后在云上安装 E-HPC agent 即可通过 job scheduler 调度资源。大部分情况下,任务数据需要进行两边的传输,因此可以充分利用线上线下的高峰低谷。此外,NAS 异步存储的数据可以在作业执行时从线下拉取,这在高通量计算场景下非常必要。
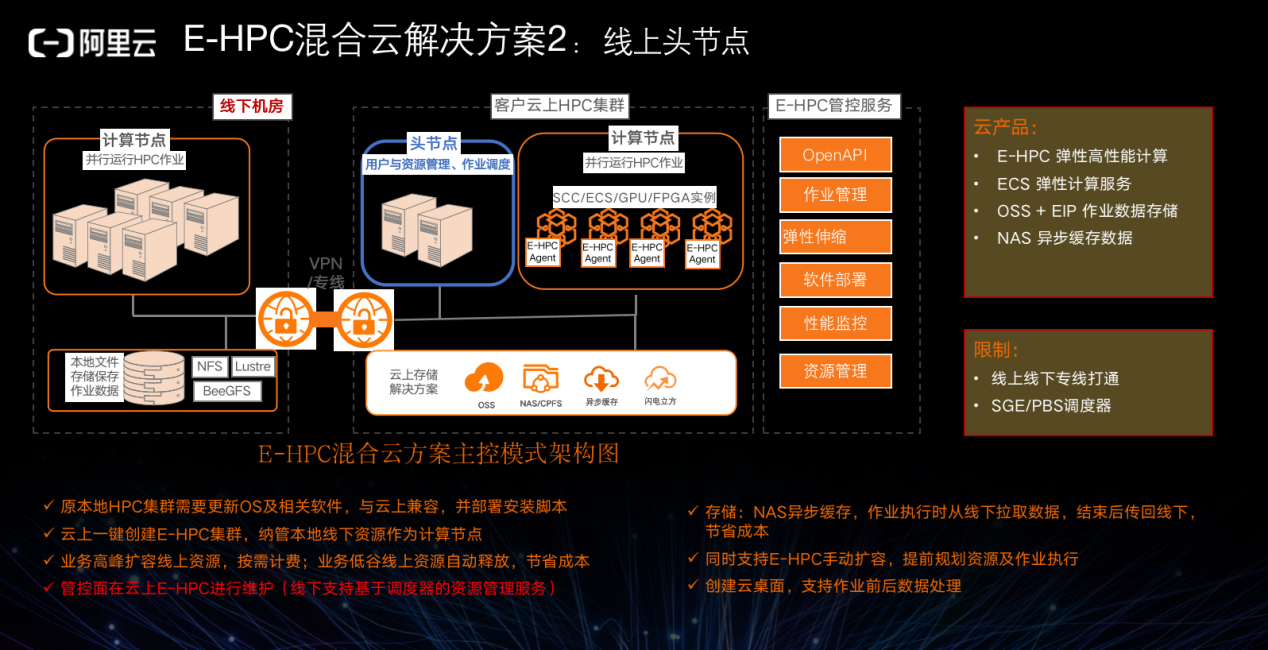
另外,也可以将计算的管理埋在头节点,即使用 E-HPC 作为管控,自己的管控通过在云下接收 agent 进行计算来实现。
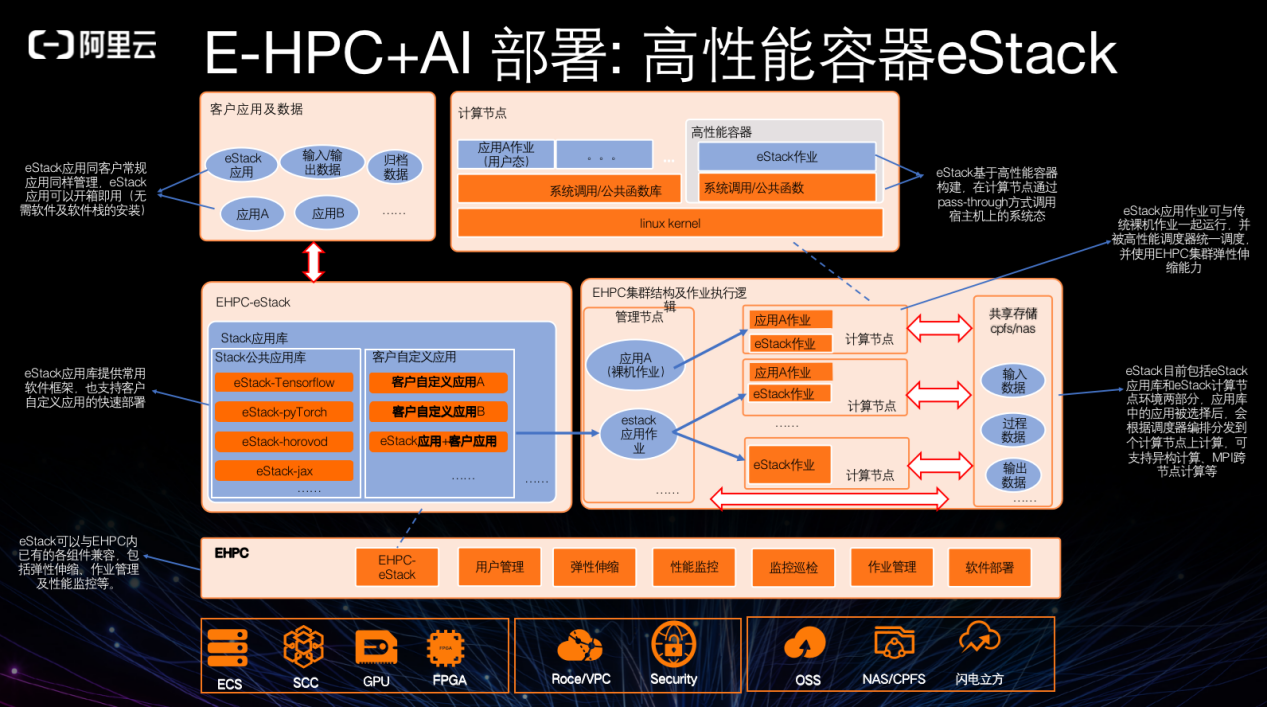
E-HPC+AI 是当前的热门趋势。各种 AI framework 最初的目的不是为了解决科学机理性的问题,而是为了解决搜索、推广、广告等与群体思维有关但缺乏机理模型的问题。而如今,我们将高性能计算容器做成镜像,在部署和计算过程中快速展开,使其也能用于科学研究,比如在拥有大量数据的情况下,将人的经验作为模型注入 AI,然后通过机器将问题空间降低。
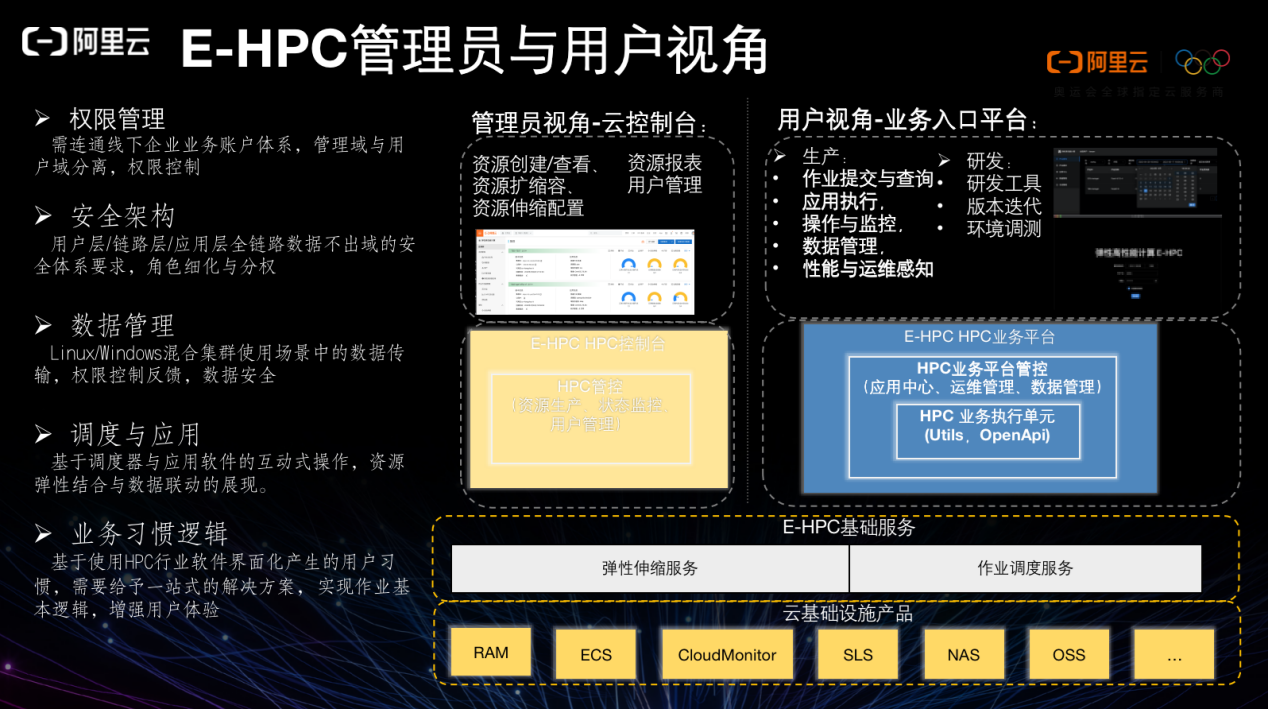
此外,为了方便科研人员的使用,我们增加了 E-HPC 用户入口。整个开发和业务流程都可以从用户视角进行查看。
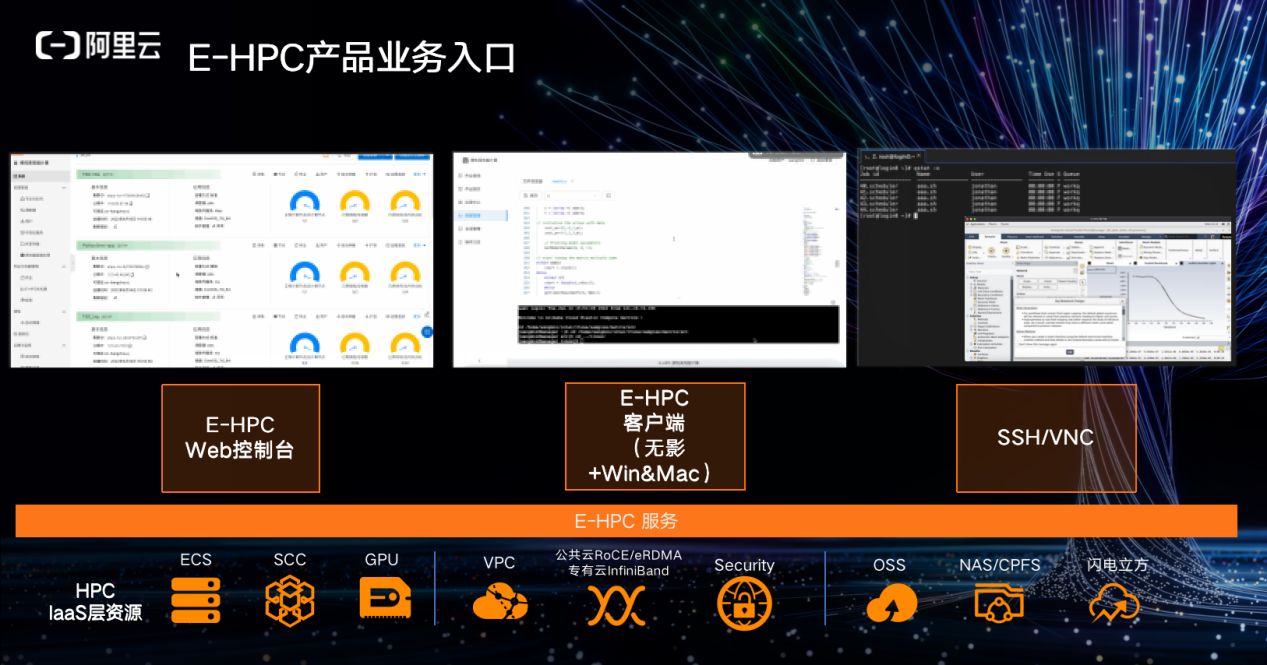
平台集成了众多可视化软件,科研人员可以通过客户端(无影+Win&Mac)直接进入,底层提供了所有服务。

无影是软件定义的云原生电脑,相当于一个入口,它可以是任何设备或屏幕。云上数据中心的规模远小于端的规模,而端侧受限于 CPU 的能力往往无法实现太多能力。但是如果通过 VID 或自己的协议,能够将云上的可视化部分利用起来,则可以实现非常多的访问。
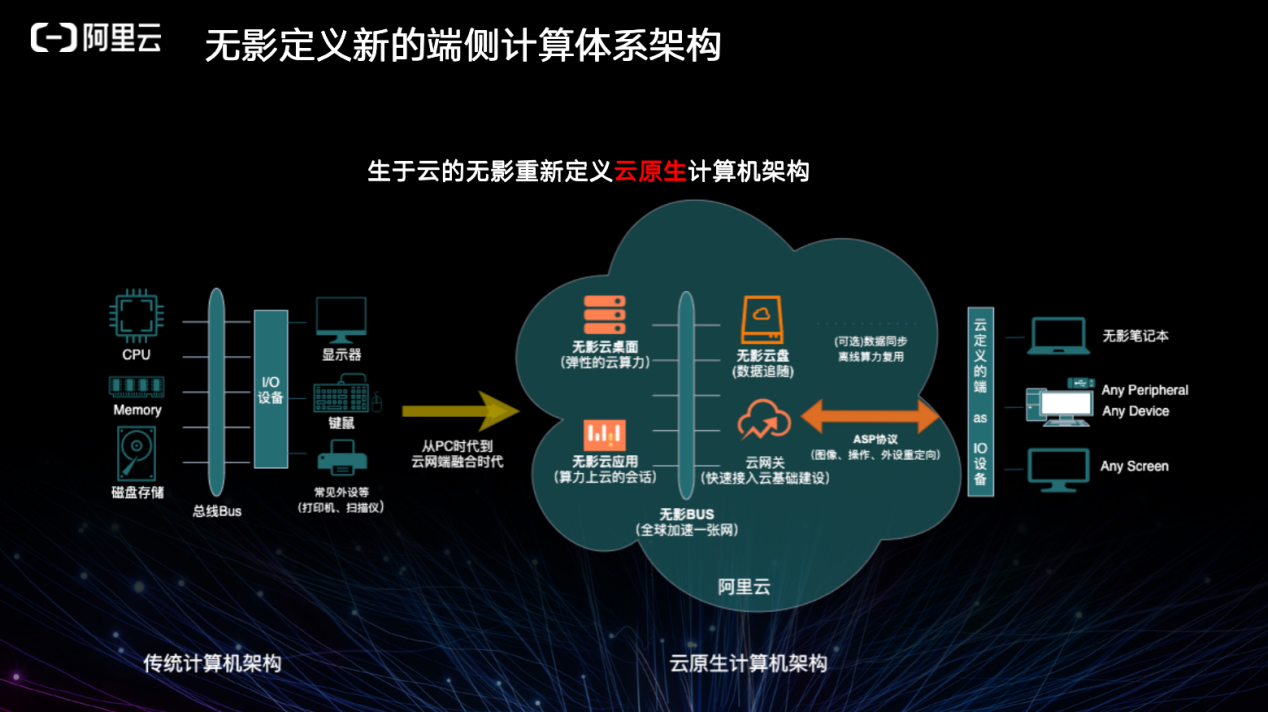
过去传统的计算结构的交互为显示器、键盘鼠标、打印机等与一台计算存储网络。而未来,只需要通过无影,它可能是一个盒子,可能是一个电脑上的应用入口,即可访问所有云上的可视化软件以及计算资源。无影很可能成为将来元宇宙的入口,因为所有 GPU、DPU、XPU 将来都是通过服务的模式进入数字世界。
此外,用户完全可以控制信息不被泄露。过去,我们通过一台全功能的机器上网,病毒可以通过机器入侵电脑。而无影可以配置为是单向的,避免了病毒入侵。
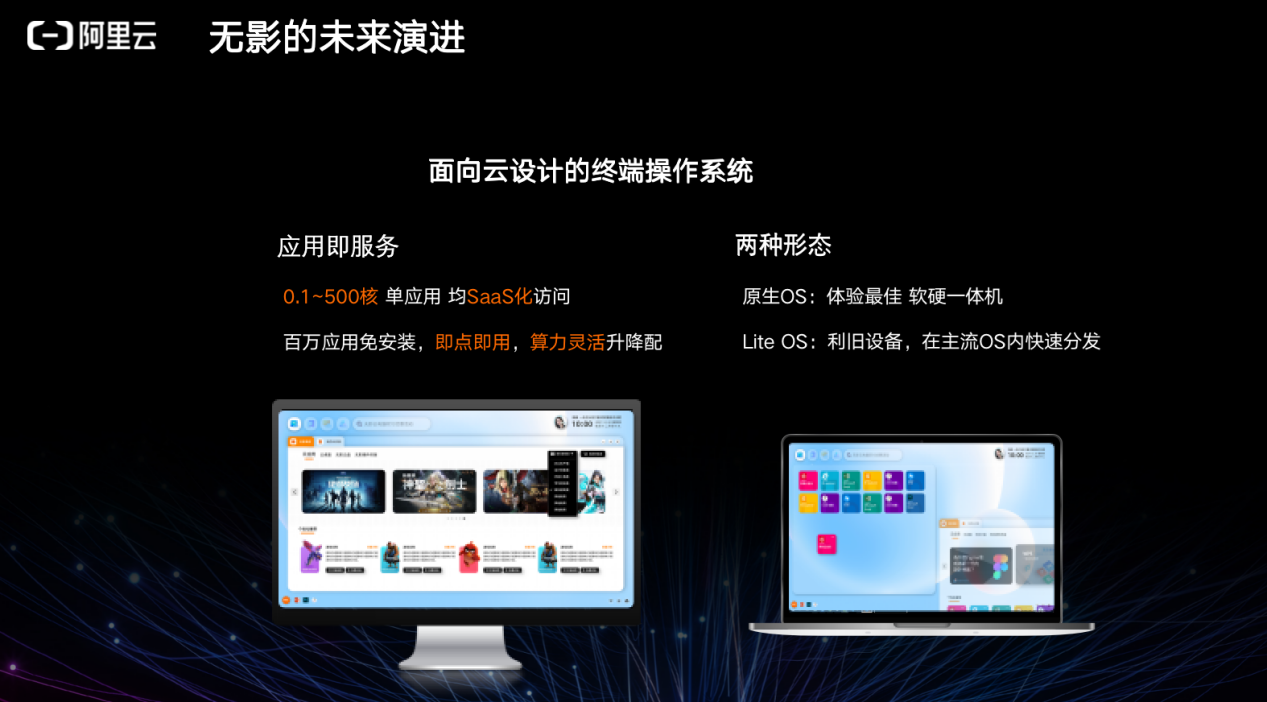
无影可以作为云产品放在任何机器上,比如过时的手机,随时随地用云电脑办公。
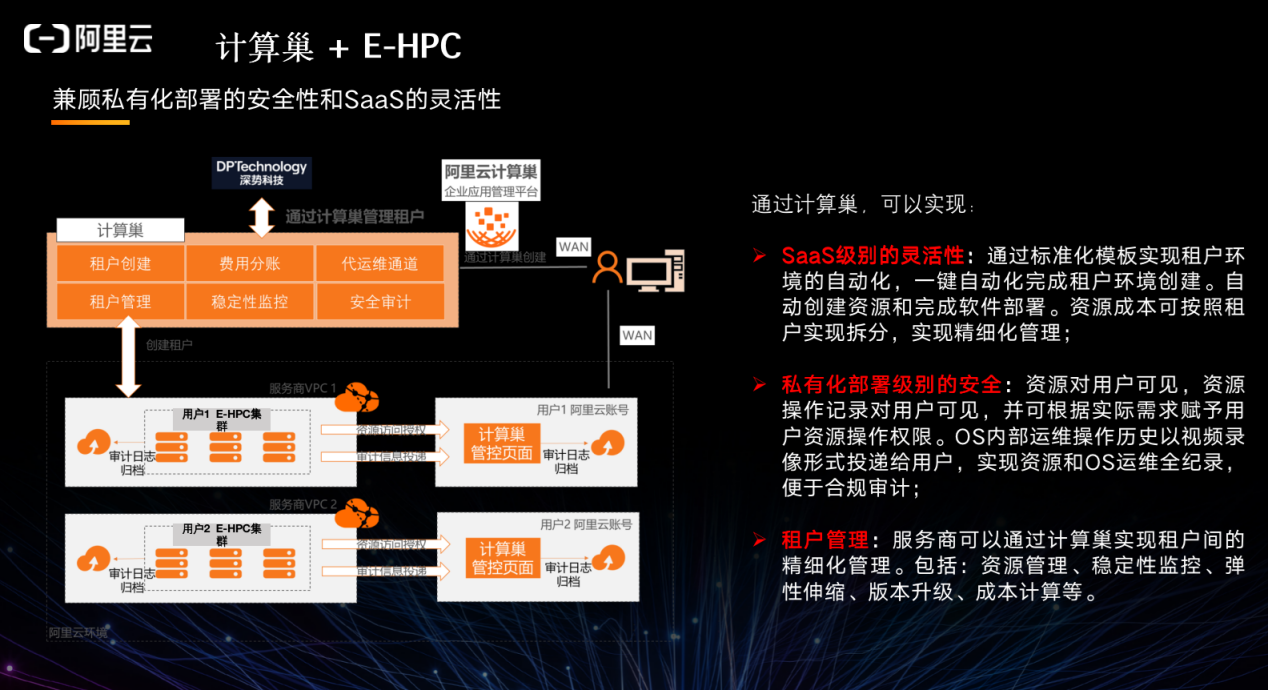
如今很多科研产品是软件,需要更多地服务广大科研工作者。而在自己的机器安装和使用,运维和 OPEX 都非常高,也难以调用更多资源。
因此,我们推出了计算巢,可以通过它快速将云计算本身的运维、资源调度、资源计费等所有资源管理透明地开放给用户,用户只需考虑安装类工作,剩下的都可以交由计算巢来完成。

阿里云今天发布生命科学行业云上解决方案与最佳实践白皮书,主要包含三部分:云能解决生命科学领域的哪些问题、五大解决方案以及三大最佳实践。高性能计算本质上希望能够帮助科研人员将精力集中于专业领域,而无需耗费精力在处理器结构等非专业领域的问题上。
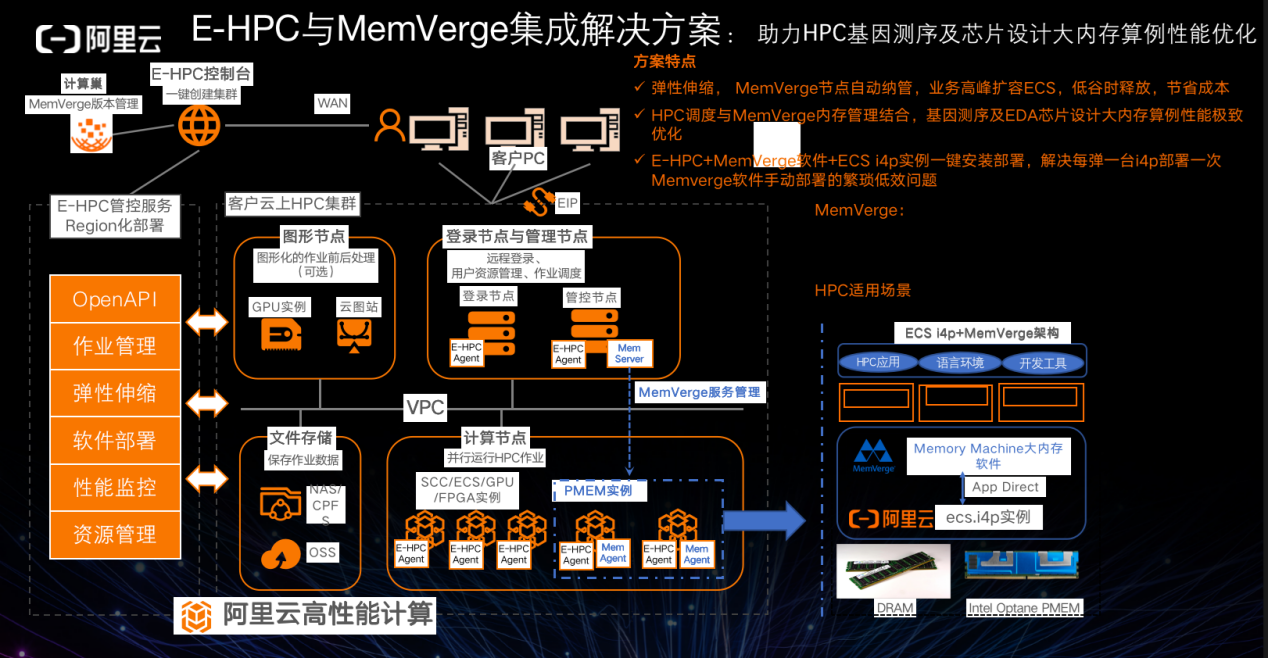
E-HPC 与 MemVerge 的集成解决方案主要助力于 HPC 基因测序及芯片设计大内存算例的性能优化,可以将常规内存与持久性内存全部虚拟化成一个大池,根据具体需求进行伸缩。
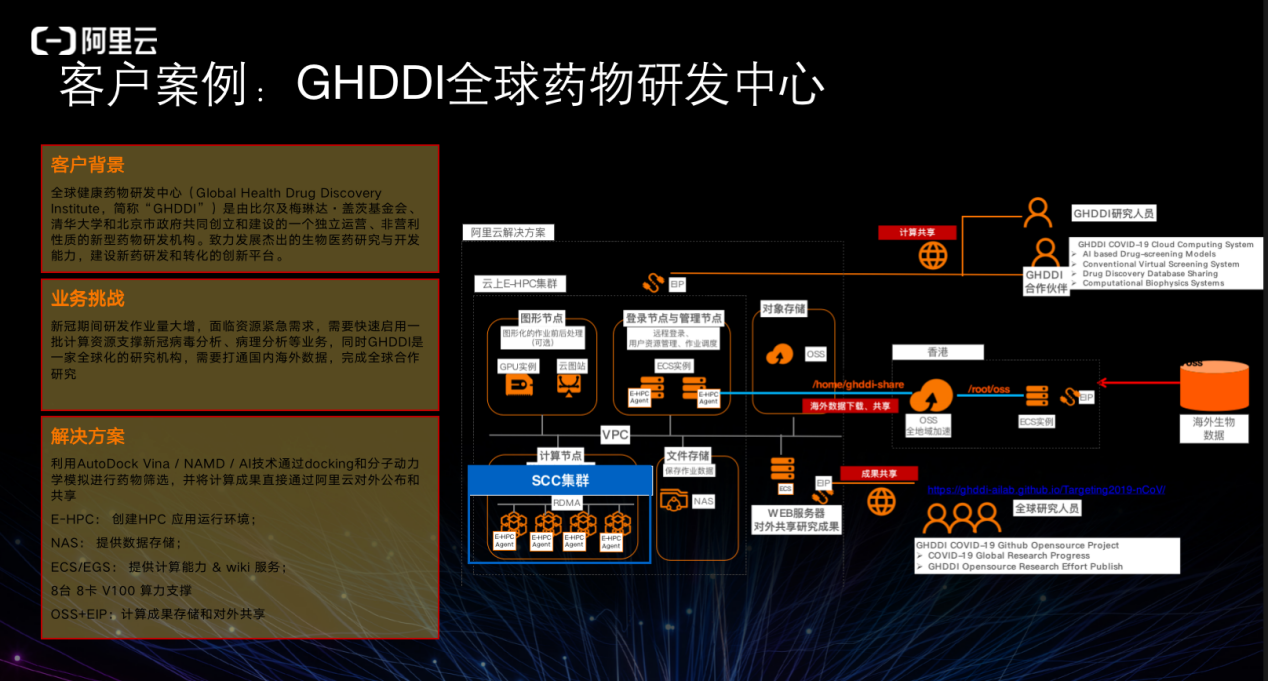
GHDDI 在新冠期间研发作业量大增,面临资源紧急需求,需要快速启用一批计算资源支撑新冠病毒分析、病理分析等业务,同时 GHDDI 是一家全球化的研究机构,需要打通国内海外数据,完成全球合作研究。比如会有 web service ,需要通过 OSS 将数据拉上来,另外需要能够实现异步的数据拉取以及异步缓存。
我们为其提供的解决方案如下:
◾ 利用 AutoDock Vina / NAMD / AI 技术通过 docking 和分子动力学模拟进行药物筛选,并将计算成果直接通过阿里云对外公布和共享;
◾ E-HPC:创建 HPC 应用运行环境;
◾ NAS:提供数据存储;
◾ ECS/EGS:提供计算能力 & wiki 服务;
◾ 8 台 8 卡 A100 算力支撑;
◾ OSS+EIP:计算成果存储和对外共享。
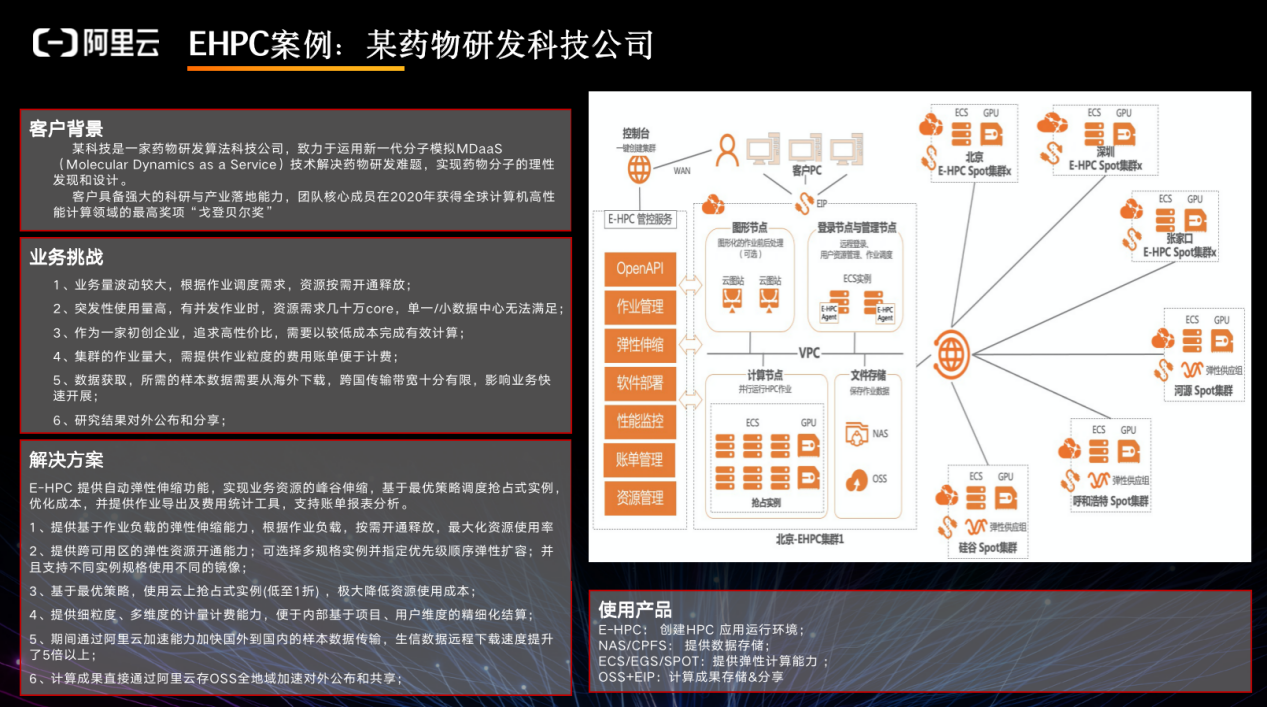
药物研究企业的需求往往是低成本、弹性伸缩,能够很清楚地跟踪每一个 workload 。我们针对某药企的需求,开发了抢占式实例,抢占到实例后存在限定的时间,超时后不做任何清理则对资源进行释放,极大降低了成本。
逆转录的研究需要将数据库与海外的数据库通过阿里的高速网络打通,实现异步复制和高通量的计算。
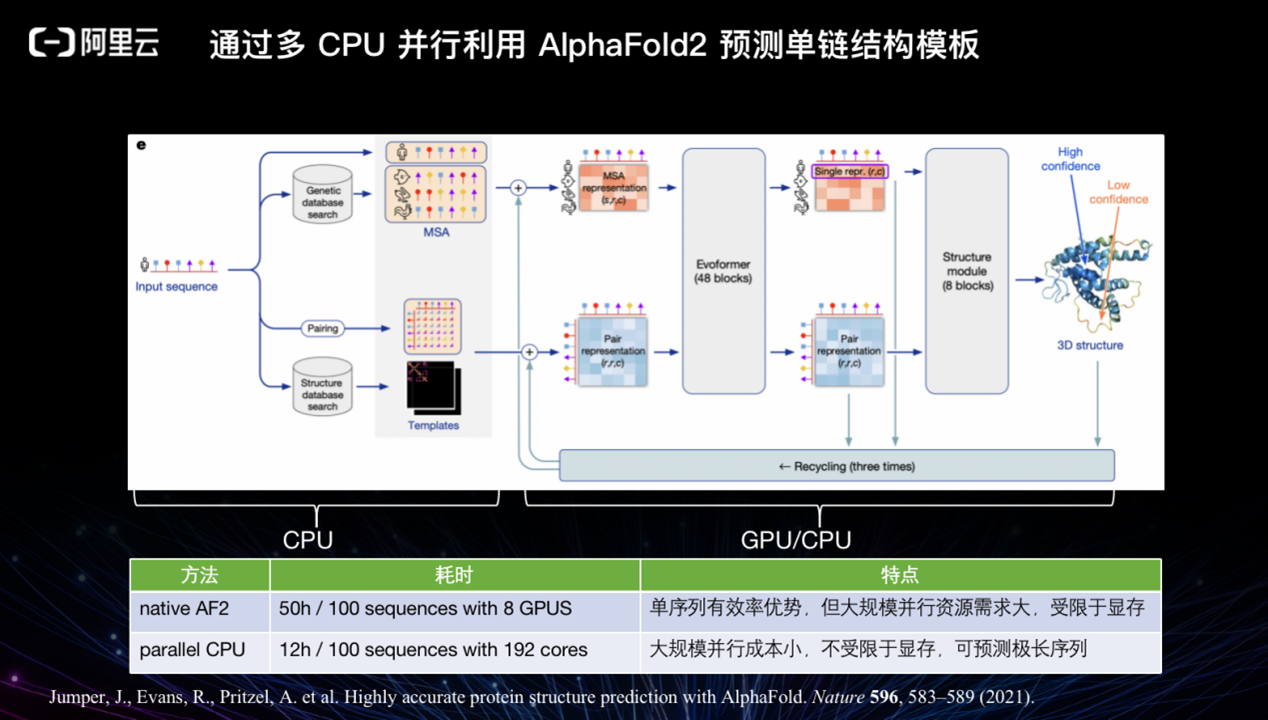
通过多 CPU 并行利用 AlphaFold2 可以预测单链结构模板。我们希望能够在云上开放 AlphaFold2 服务,为院校的日常课程、培训提供更大的支持。
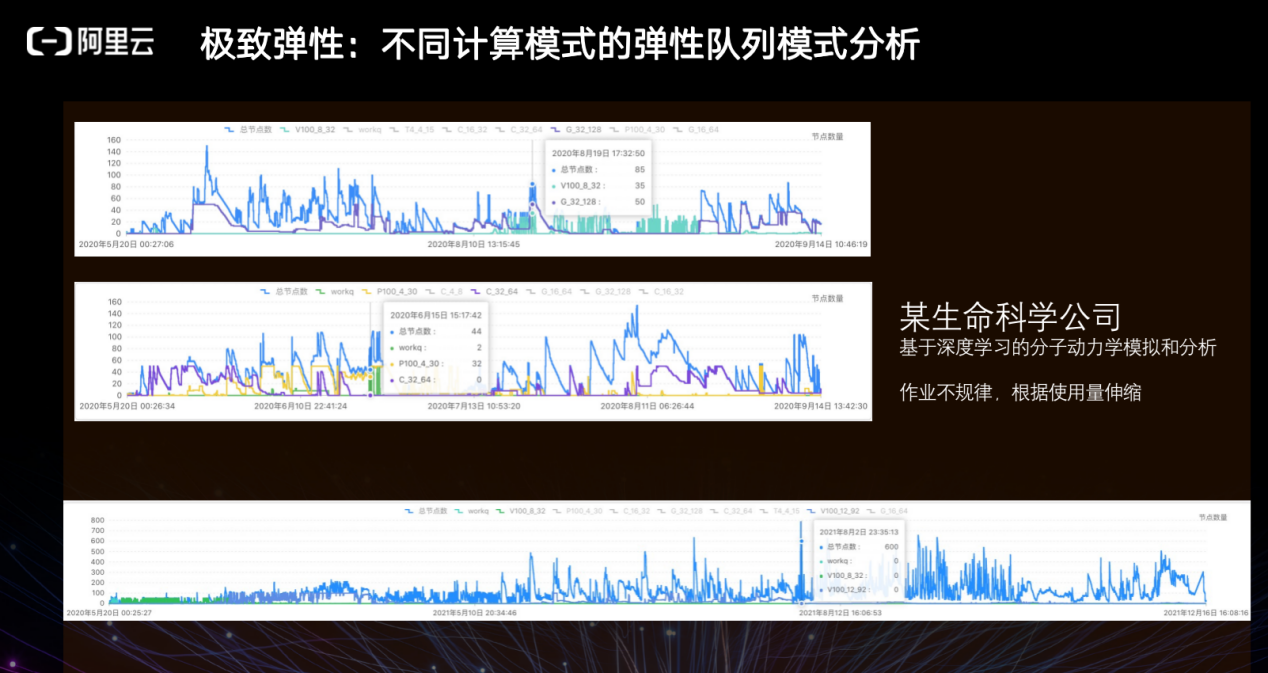
科研类单位、制药企业的业务存在极大的随机性,因此对于资源的利用率需要更精细化的管理。
阿里云高性能计算的目标是为科研行业提供更高的算力和更高的资源利用率,服务更多科研人员,让科学家们将更多的精力投入于专业领域当中,为科研行业助力!
点击这里,观看嘉宾在本次峰会的精彩演讲视频 。