1. 概述
在情感分析的应用领域,例如判断某一句话是positive或者是negative的案例中,咱们可以通过传统的standard neuro network来作为解决方案,但是传统的神经网络在应用的时候是不能获取前后文字之间的关系的,不能获取到整个句子的一个整体的意思,只能通过每一个词的意思来最终决定一句话的情感,这显然是不合理的,导致的结果就是训练出来的模型质量可能不是很高。那么这里就需要用到LSTM来解决这个问题了,LSTM能够很好的表达出句子中词的关系,能将句子当做一个整体来看待,而不是一个个单独的词。所以这一节主要讲一下如何应用LSTM来做句子的情感分析的应用,这里主要包括2部分内容,第一部分是设计整个LSTM的网络结构,第二步是用代码是实现这个网络。
2. 结构设计
首先咱们知道应用的目的是根据句子的内容来判断情感的,那么咱们就可以很明确的知道这是一个Sequence model, 其次这个Sequence Model还是一个Many-To-One的结构。那么这里我为了提高咱们应用的复杂度,我选用了一个2层的LSTM layer, 就是将第一层的每一个LSTM cell 的输出作为第二层的每一个相应的LSTM cell的输入。听起来挺抽象的,实际咱们通过下面的图可以很清楚的看出它的整体结构(注意:下面的图,我省略了LSTM的memory cell,没有画出来)。实际的应用中,咱们很少会有大于3层的LSTM layer,因为它计算所需要的资源是非常大的。其实在这个例子中,一层的LSTM layer其实是足够的,我这里只是为了演示2层layer,所以故意这样处理的,下面咱们看一下结构图吧
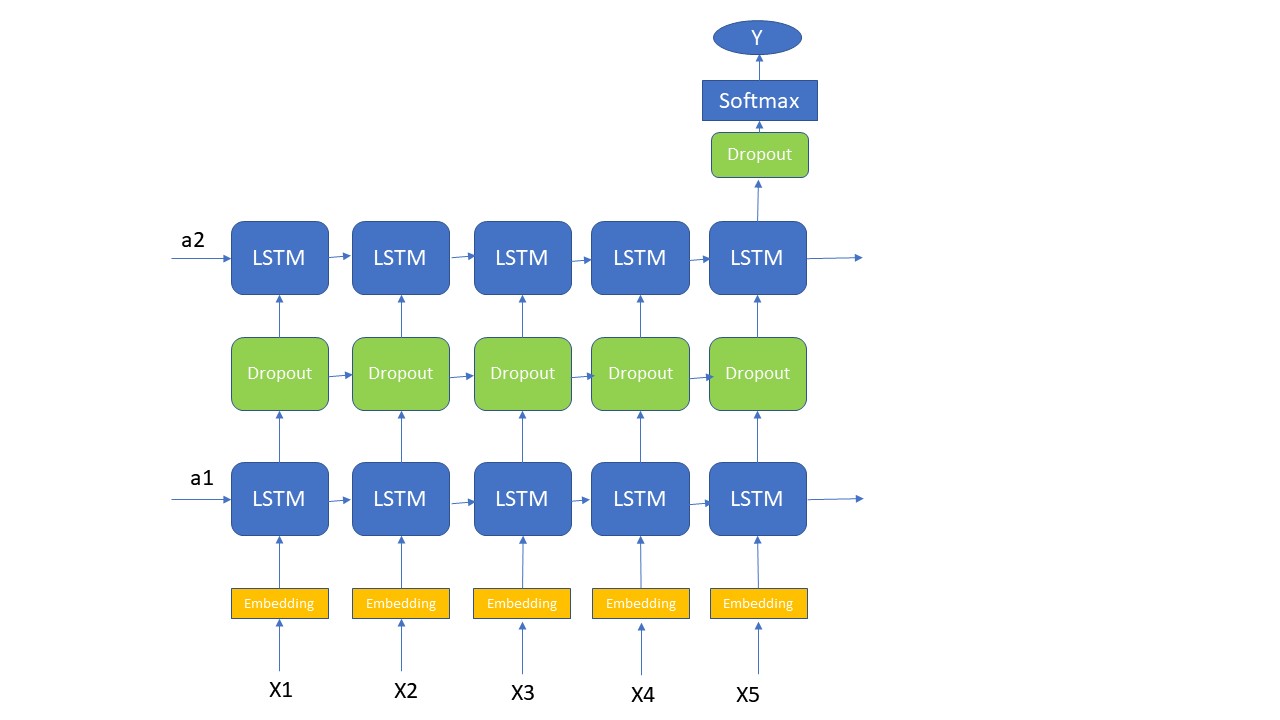
首先第一步还是要将所有的Word经过embedding layer, 然后再将这些features带入到LSTM layer中。第一层的LSTM layer每一个time step的输出都需要作为第二步的输入,所以在下面的代码中,第一层的LSTM的return_sequences需要设置成true;而第二层中只需要最后一个time step的输出,所以return_sequences设置成false。因为咱们这是的a, c设置的dimension都比较大,所以每一步都经过一个dropout layer让它按照一定的比例丢弃一部分信息,否则咱们的计算成本太高了。既然它的结构咱们已经设计出来了,那接下来咱们看看它的代码实现过程吧。
3.神经网络结构的代码实现
上面的代码咱们已经设计出来咱们对于这个应用的网络结构,接下来就是代码实现的过程,这里咱们应用了Keras的Functional API来搭建网络结构,咱们直接看一下代码吧,这里我只展示这个神经网络的构建代码:
def Sentiment_Model(input_shape): """ Function creating the Emojify-v2 model's graph. Arguments: input_shape -- shape of the input, usually (max_len,) Returns: model -- a model instance in Keras """ # Define sentence_indices as the input of the graph. # It should be of shape input_shape and dtype 'int32' (as it contains indices, which are integers). sentence_sequences = Input(input_shape, dtype='int32') # Propagate sentence_indices through your embedding layer # (See additional hints in the instructions). embeddings = Keras.Embedding(sentence_sequences) # Propagate the embeddings through an LSTM layer with 128-dimensional hidden state # The returned output should be a batch of sequences. X = LSTM(128, return_sequences = True)(embeddings) # Add dropout with a probability of 0.5 X = Dropout(0.5)(X) # Propagate X trough another LSTM layer with 128-dimensional hidden state # The returned output should be a single hidden state, not a batch of sequences. X = LSTM(128, return_sequences=False)(X) # Add dropout with a probability of 0.5 X = Dropout(0.5)(X) # Propagate X through a Dense layer with 5 units X = Dense(5)(X) # Add a softmax activation X = Activation('softmax')(X) # Create Model instance which converts sentence_indices into X. model = Model(inputs=sentence_sequences, outputs=X) return model
首先第一步上面的model要定义一个Input, 它的shape就是一句话的长度;后面的embedding layer, Dropout layer和LSTM layer都是按照上面的结构来实现的。具体里面的细节,我在代码中的注释已经写得非常清楚了。主要有几个细节部分需要注意一下,第一个是hidden state的dimension;第二个是return_sequence的参数,如果大家对return_sequence和return_state的参数不理解,有疑问,我推荐大家看一下这个博客,解释的非常到位, https://machinelearningmastery.com/return-sequences-and-return-states-for-lstms-in-keras/;第三个就是上面的Input_shape是省略batch_size参数的;至于这个model的fitting, evaluation等其他过程和其他的model都是一样的,这里我就不展开来说了,最核心的就是上面的这个结构的构建。
4. 总结
这里主要讲述了一个Many-to-One结构的LSTM的一般应用,这里主要是用一个情感分析的例子来演示,但是它的应用非常广泛的。这里的重点是对LSTM 的Many-to-One结构的理解,其次是对于多层LSTM layer的应用和理解。至于用TensorFlow来实现这个神经网络的部分,主要是对LSTM 中的一些参数的设置要理解就行了,其他的都很简单。