
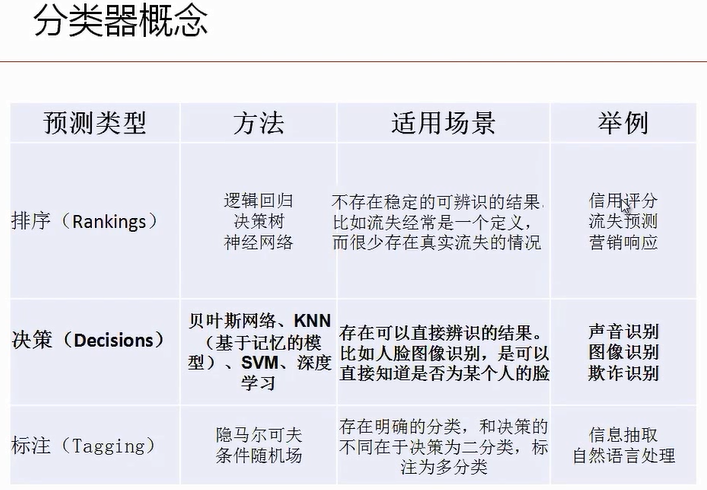
先来看看分类器的概念:
knn算法
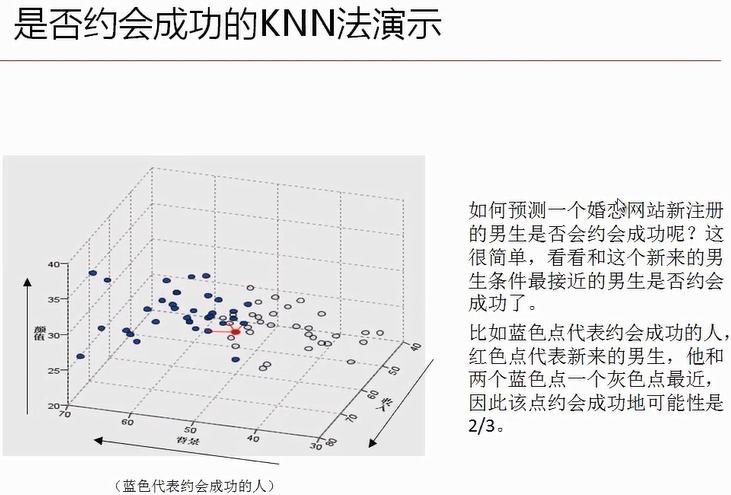
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。


标准化处理,消除量纲的影响!

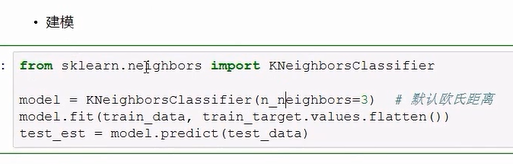
python的实现:
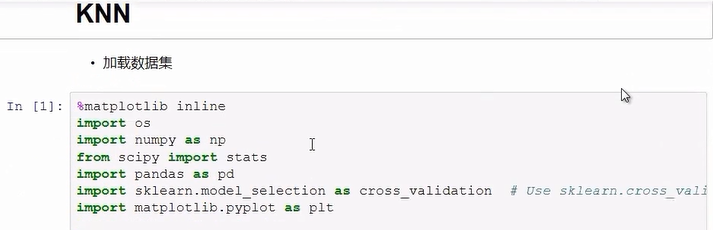
导入所需的包:
读取数据和统计描述
这是婚恋网站注册用户的一些信息,包括输入,资产,教育==
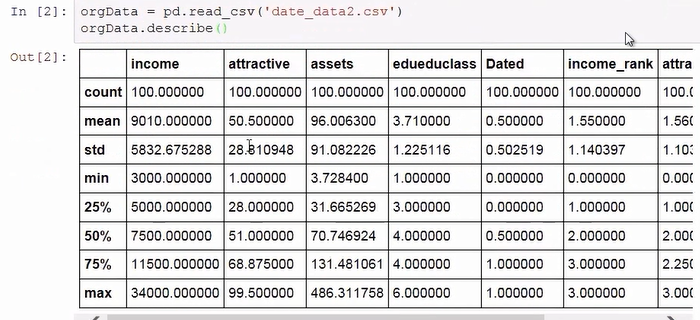
多出这几个是排名,为了让结果准确性提高些
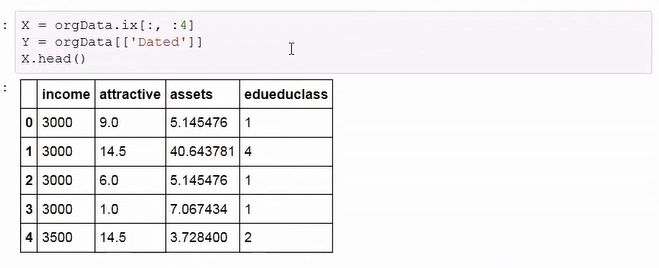
选取自变量
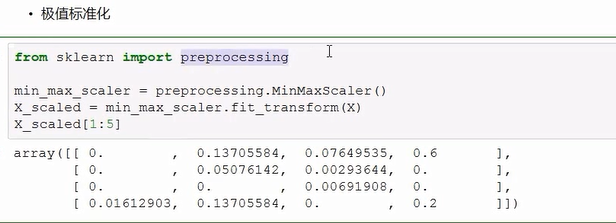

这里步骤不太好,应该先划分训练集和测试集较好。在进行标准化。

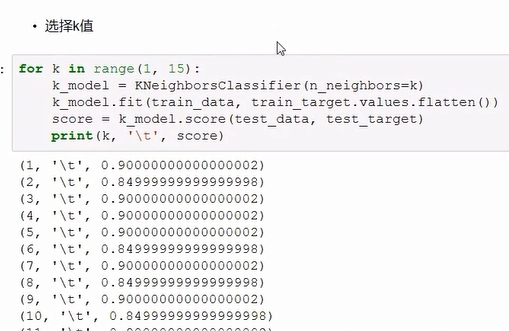
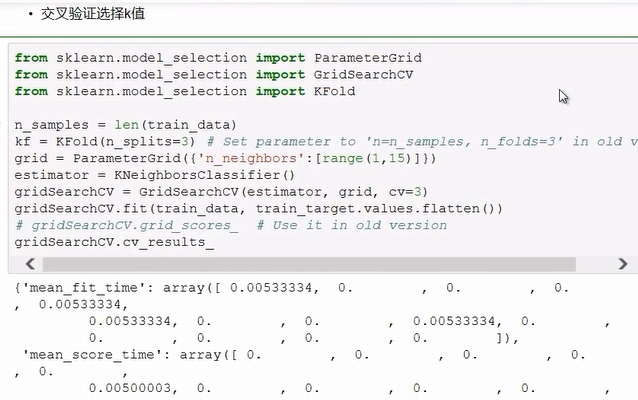
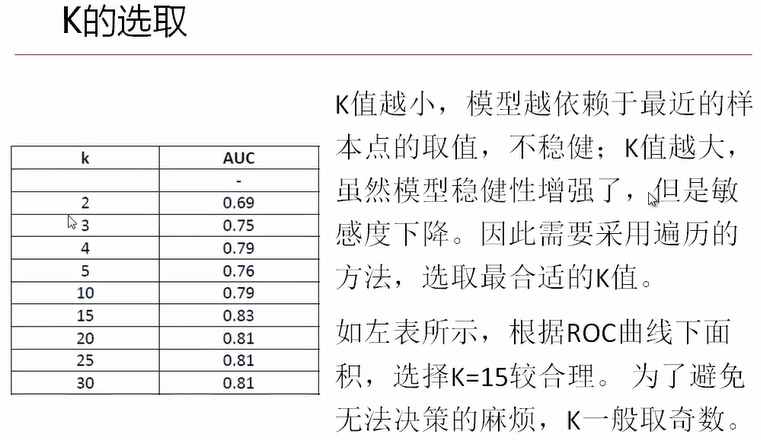
看了多数据,直接用这个函数就可以告诉你k值取那个最适合,这里是5!
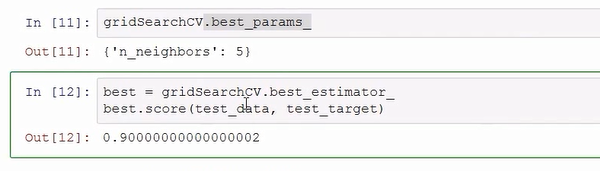
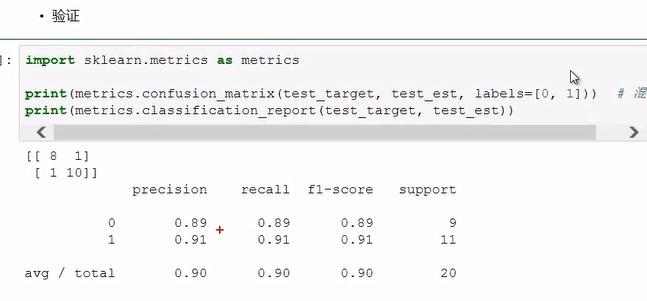
那么就得到结果了。这个准确性挺高。