软件架构理解
1FastDFS介绍
1.1什么是FastDFS
FastDFS是用c语言编写的一款开源的分布式文件系统。FastDFS为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务。
FastDFS是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
FastDFS服务端有两个角色:跟踪器(tracker)和存储节点(storage)。跟踪器主要做调度工作,在访问上起负载均衡的作用。
存储节点存储文件,完成文件管理的所有功能:存储、同步和提供存取接口,FastDFS同时对文件的metadata进行管理。所谓文件的meta data就是文件的相关属性,以键值对(key valuepair)方式表示,如:width=1024,其中的key为width,value为1024。文件metadata是文件属性列表,可以包含多个键值对。
跟踪器和存储节点都可以由一台或多台服务器构成。跟踪器和存储节点中的服务器均可以随时增加或下线而不会影响线上服务。其中跟踪器中的所有服务器都是对等的,可以根据服务器的压力情况随时增加或减少。
为了支持大容量,存储节点(服务器)采用了分卷(或分组)的组织方式。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。
在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。
当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
FastDFS中的文件标识分为两个部分:卷名和文件名,二者缺一不可。
FastDFS file upload
上传文件交互过程:
1. client询问tracker上传到的storage,不需要附加参数;
2. tracker返回一台可用的storage;
3. client直接和storage通讯完成文件上传。
FastDFS file download
下载文件交互过程:
1. client询问tracker下载文件的storage,参数为文件标识(卷名和文件名);
2. tracker返回一台可用的storage;
3. client直接和storage通讯完成文件下载。
需要说明的是,client为使用FastDFS服务的调用方,client也应该是一台服务器,它对tracker和storage的调用均为服务器间的调用。
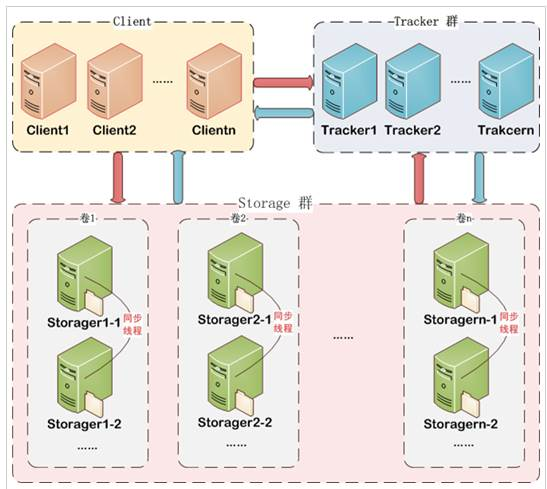
1.2FastDFS架构
FastDFS架构包括 Tracker server和Storage server。客户端请求Tracker server进行文件上传、下载,通过Tracker server调度最终由Storage server完成文件上传和下载。
Tracker server作用是负载均衡和调度,通过Tracker server在文件上传时可以根据一些策略找到Storage server提供文件上传服务。可以将tracker称为追踪服务器或调度服务器。
Storage server作用是文件存储,客户端上传的文件最终存储在Storage服务器上,Storage server没有实现自己的文件系统而是利用操作系统的文件系统来管理文件。可以将storage称为存储服务器。
如下图:
1.2.1 Tracker 集群
FastDFS集群中的Tracker server可以有多台,Tracker server之间是相互平等关系同时提供服务,Tracker server不存在单点故障。客户端请求Tracker server采用轮询方式,如果请求的tracker无法提供服务则换另一个tracker。
1.2.2 Storage集群
Storage集群采用了分组存储方式。storage集群由一个或多个组构成,集群存储总容量为集群中所有组的存储容量之和。一个组由一台或多台存储服务器组成,组内的Storage server之间是平等关系,不同组的Storage server之间不会相互通信,同组内的Storage server之间会相互连接进行文件同步,从而保证同组内每个storage上的文件完全一致的。一个组的存储容量为该组内存储服务器容量最小的那个,由此可见组内存储服务器的软硬件配置最好是一致的。
采用分组存储方式的好处是灵活、可控性较强。比如上传文件时,可以由客户端直接指定上传到的组也可以由tracker进行调度选择。一个分组的存储服务器访问压力较大时,可以在该组增加存储服务器来扩充服务能力(纵向扩容)。当系统容量不足时,可以增加组来扩充存储容量(横向扩容)。
1.2.3 Storage状态收集
Storage server会连接集群中所有的Tracker server,定时向他们报告自己的状态,包括磁盘剩余空间、文件同步状况、文件上传下载次数等统计信息。
1.2.4 文件上传流程
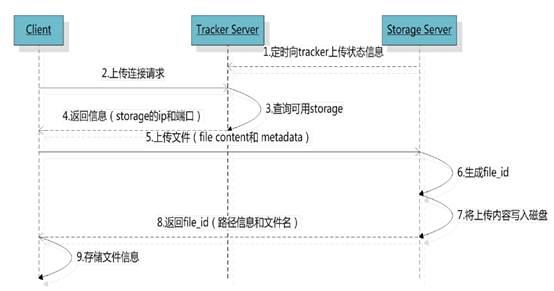
客户端上传文件后存储服务器将文件ID返回给客户端,此文件ID用于以后访问该文件的索引信息。文件索引信息包括:组名,虚拟磁盘路径,数据两级目录,文件名。
![]()
n 组名:文件上传后所在的storage组名称,在文件上传成功后有storage服务器返回,需要客户端自行保存。
n 虚拟磁盘路径:storage配置的虚拟路径,与磁盘选项store_path*对应。如果配置了store_path0则是M00,如果配置了store_path1则是M01,以此类推。
n 数据两级目录:storage服务器在每个虚拟磁盘路径下创建的两级目录,用于存储数据文件。
n 文件名:与文件上传时不同。是由存储服务器根据特定信息生成,文件名包含:源存储服务器IP地址、文件创建时间戳、文件大小、随机数和文件拓展名等信息。
1.2.5 文件下载流程

tracker根据请求的文件路径即文件ID 来快速定义文件。
比如请求下边的文件:
![]()
1.通过组名tracker能够很快的定位到客户端需要访问的存储服务器组是group1,并选择合适的存储服务器提供客户端访问。
2.存储服务器根据“文件存储虚拟磁盘路径”和“数据文件两级目录”可以很快定位到文件所在目录,并根据文件名找到客户端需要访问的文件。
2FastDFS+Nginx实现文件服务器
2.1架构
2.1.1 架构图
|

2.1.2 架构描述
出于高可用的需求tracker和storage都使用两台服务器,storage使用两个组用以说明storage可以任意扩充组实现线性扩展。
2.1.2.1client
client可以通过java client API方式进行文件上传、下载、删除。
client可以通过http方式进行文件下载。tracker通过nginx提供http下载接口。
client也可以直接访问storage进行文件上传、下载、删除,但建议client通过tracker进行文件上传、下载、删除。
2.1.2.2Tracker Server
每个tracker server互相平等,tracker server上部署nginx是为了对外提供http文件下载接口,tracker上nginx只是起到负载均衡的作用。tracker的nginx会代理转发至storage上的nginx。
tracker上的两个nginx可以采用主备方式实现高可用。nginx高可用参数nginx文档。
2.1.2.3Storage Server
每台storage上也部署nginx,storage上的nginx与tracker上的nginx有区别,storage上的nginx需要安装FastDSF-nginx模块,此模块的作用是使用FastDFS和nginx进行整合,nginx对外提供http文件下载接口,注意:nginx只提供文件下载接口不提供上传接口。文件上传仍然通过java client API进行。
#只需要修改几个地方base_path=/home/yuqing/FastDFS改为:base_path=/home/FastDFS配置http端口:http.server_port=80
group_name=group1base_path=/home/yuqing/FastDFS改为:base_path=/home/FastDFSstore_path0=/home/yuqing/FastDFS改为:store_path0=/home/FastDFS/fdfs_storage#如果有多个挂载磁盘则定义多个store_path,如下#store_path1=.....#store_path2=......#配置tracker服务器:IPtracker_server=192.168.1.20:22122#如果有多个则配置多个tracker...tracker_server=192.168.1.21:22122#配置http端口http.server_port=80
base_path=/home/FastDFS#可以配置多个trackertracker_server=192.168.1.20:22122#tracker_server=192.168.1.21:22122
ngx_addon_name=ngx_http_fastdfs_moduleHTTP_MODULES="$HTTP_MODULES ngx_http_fastdfs_module"NGX_ADDON_SRCS="$NGX_ADDON_SRCS $ngx_addon_dir/ngx_http_fastdfs_module.c"CORE_INCS="$CORE_INCS /usr/include/fastdfs /usr/include/fastcommon/"CORE_LIBS="$CORE_LIBS -L/usr/lib -lfastcommon -lfdfsclient"CFLAGS="$CFLAGS -D_FILE_OFFSET_BITS=64 -DFDFS_OUTPUT_CHUNK_SIZE='256*1024' -DFDFS_MOD_CONF_FILENAME='"/etc/fdfs/mod_fastdfs.conf"'"
tracker_server=192.168.2.215:22122 url_have_group_name = true store_path_count=1 store_path0=/opt/fastDfsData/fdfs_storage group_count = 1 [group1] group_name=group1 storage_server_port=23000 store_path_count=1 store_path0=/opt/fastDfsData/fdfs_storage
location /group1/M00{root /home/FastDFS/fdfs_storage/data;ngx_fastdfs_module;}
{kind=link}
{kind=link}

#################################进阶,配置理解#####################
1 附录
1.1tracker.conf
1 基本配置
disable
#func:配置是否生效
#valu:true、false
disable=false
bind_addr
#func:绑定IP
#valu:IP地址
bind_addr=192.168.6.102
port
#func:服务端口
#valu:端口整数值
port=22122
connect_timeout
#func:连接超时
#valu:秒单位正整数值
connect_timeout=30
network_timeout
#func:网络超时
#valu:秒单位正整数值
network_timeout=60
base_path
#func:Tracker数据/日志目录地址
#valu:路径
base_path=/home/michael/fdfs/base4tracker
max_connections
#func:最大连接数
#valu:正整数值
max_connections=256
work_threads
#func:线程数,通常设置CPU数
#valu:正整数值
work_threads=4
store_lookup
#func:上传文件的选组方式。
#valu:0、1或2。
# 0:表示轮询
# 1:表示指定组
# 2:表示存储负载均衡(选择剩余空间最大的组)
store_lookup=2
store_group
#func:指定上传的组,如果在应用层指定了具体的组,那么这个参数将不会起效。另外如果store_lookup如果是0或2,则此参数无效。
#valu:group1等
store_group=group1
store_server
#func:上传服务器的选择方式。(一个文件被上传后,这个storage server就相当于这个文件的storage server源,会对同组的storage server推送这个文件达到同步效果)
#valu:0、1或2
# 0: 轮询方式(默认)
# 1: 根据ip 地址进行排序选择第一个服务器(IP地址最小者)
# 2: 根据优先级进行排序(上传优先级由storage server来设置,参数名为upload_priority),优先级值越小优先级越高。
store_server=0
store_path
#func:上传路径的选择方式。storage server可以有多个存放文件的base path(可以理解为多个磁盘)。
#valu:
# 0: 轮流方式,多个目录依次存放文件
# 2: 存储负载均衡。选择剩余空间最大的目录存放文件(注意:剩余磁盘空间是动态的,因此存储到的目录或磁盘可能也是变化的)
store_path=0
download_server
#func:下载服务器的选择方式。
#valu:
# 0:轮询(默认)
# 1:IP最小者
# 2:优先级排序(值最小的,优先级最高。)
download_server=0
reserved_storage_space
#func:保留空间值。如果某个组中的某个服务器的剩余自由空间小于设定值,则文件不会被上传到这个组。
#valu:
# G or g for gigabyte
# M or m for megabyte
# K or k for kilobyte
reserved_storage_space=1GB
log_level
#func:日志级别
#valu:
# emerg for emergency
# alert
# crit for critical
# error
# warn for warning
# notice
# info for information
# debug for debugging
log_level=info
run_by_group / run_by_user
#func:指定运行该程序的用户组
#valu:用户组名或空
run_by_group=
#func:
#valu:
run_by_user=
allow_hosts
#func:可以连接到tracker server的ip范围。可设定多个值。
#valu
allow_hosts=
check_active_interval
#func:检测 storage server 存活的时间隔,单位为秒。
#storage server定期向tracker server 发心跳,
#如果tracker server在一个check_active_interval内还没有收到storage server的一次心跳,
#那边将认为该storage server已经下线。所以本参数值必须大于storage server配置的心跳时间间隔。
#通常配置为storage server心跳时间间隔的2倍或3倍。
check_active_interval=120
thread_stack_size
#func:设定线程栈的大小。 线程栈越大,一个线程占用的系统资源就越多。
#如果要启动更多的线程(V1.x对应的参数为max_connections,V2.0为work_threads),可以适当降低本参数值。
#valu:如64KB,默认值为64,tracker server线程栈不应小于64KB
thread_stack_size=64KB
storage_ip_changed_auto_adjust
#func:这个参数控制当storage server IP地址改变时,集群是否自动调整。注:只有在storage server进程重启时才完成自动调整。
#valu:true或false
storage_ip_changed_auto_adjust=true
2 同步
storage_sync_file_max_delay
#func:同组storage服务器之间同步的最大延迟时间。存储服务器之间同步文件的最大延迟时间,根据实际情况进行调整
#valu:秒为单位,默认值为1天(24*3600)
#sinc:v2.0
storage_sync_file_max_delay=86400
storage_sync_file_max_time
#func:存储服务器同步一个文件需要消耗的最大时间,缺省为300s,即5分钟。
#sinc:v2.0
storage_sync_file_max_time=300
sync_log_buff_interval
#func:同步或刷新日志信息到硬盘的时间间隔。注意:tracker server 的日志不是时时写硬盘的,而是先写内存。
#valu:以秒为单位
sync_log_buff_interval=10
3 trunk 和 slot
#func:是否使用trunk文件来存储几个小文件
#valu:true或false
#sinc:v3.0
use_trunk_file=false
#func:最小slot大小
#valu:<= 4KB,默认为256字节
#sinc:v3.0
slot_min_size=256
#func:最大slot大小
#valu:>= slot_min_size,当小于这个值的时候就存储到trunk file中。默认为16MB。
#sinc:v3.0
slot_max_size=16MB
#func:trunk file的size
#valu:>= 4MB,默认为64MB
#sinc:v3.0
trunk_file_size=64MB
4 HTTP 相关
是否启用 HTTP
#func:HTTP是否生效
#valu:true或false
http.disabled=false
HTTP 服务器端口号
#func:tracker server上的http port
#valu:
#note:只有http.disabled=false时才生效
http.server_port=7271
检查Storage存活状态的间隔时间(心跳检测)
#func:检查storage http server存活的间隔时间
#valu:单位为秒
#note:只有http.disabled=false时才生效
http.check_alive_interval=30
心跳检测使用的协议方式
#func:检查storage http server存活的方式
#valu:
# tcp:连接到storage server的http端口,不进行request和response。
# http:storage check alive url must return http status 200.
#note:只有http.disabled=false时才生效
http.check_alive_type=tcp
检查 Storage 状态的 URI
#func:检查storage http server是否alive的uri/url
#note:只有http.disabled=false时才生效
http.check_alive_uri=/status.html