1.尽量控制图片大小在1024以内,不然显存会爆炸。
2.尽量使用多GPU并行工作,训练下降速度快。
3.当需要被检测的单张图片里物体太多时,记得修改Region_proposals的个数
4.测试的时候单张图片里物体过多记得修改
vis_util.visualize_boxes_and_labels_on_image_array函数里面的
max_boxes_to_draw,这个默认是20。
5.训练的样本,自己造的数据集不要与原始数据集量级差异过大,自己造的数据集过多的话,容易导致模型偏向自己造成的数据集,产生对自己造的数据集产生过拟合。
6.tensorflow object detection API 怎么改GPU资源的限制,使其不全部占有gpu资源

7.切割完图片一定要记得设置xml里面的图片大小为真实图片大小。不然会导致总体loss下降了,但是Faster R-CNN最后一层分类loss始终接近于0
8.
分享一个我使用一机多卡即同一台机器使用不同的GPU的办法:
window下使用批处理命令:
set CUDA_VISIBLE_DEVICES=0
set PYTHONPATH=models/research;models/research/slim
python3 train.py
--logtostderr
--pipeline_config_path=faster_rcnn_inception_resnet_v2_atrous_coco.config
--train_dir=train
--num_clones=1
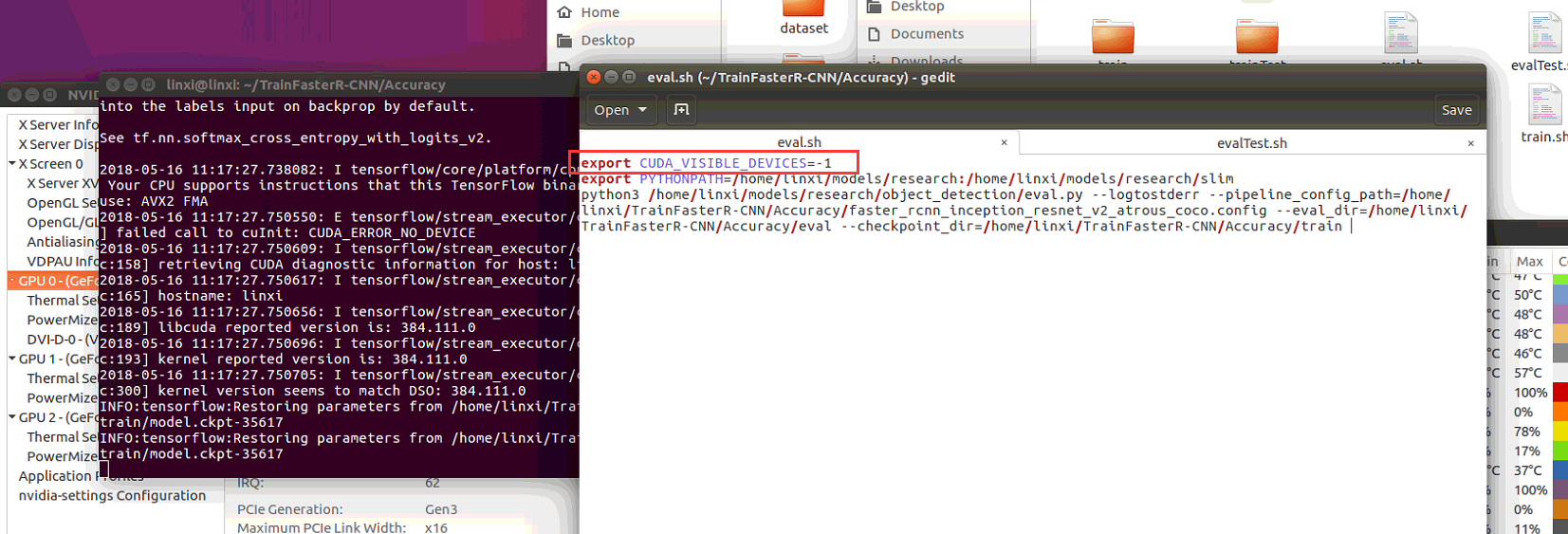
linux使用.sh文件:
export CUDA_VISIBLE_DEVICES=0
export PYTHONPATH=models/research:models/research/slim
python3 train.py
--logtostderr
--pipeline_config_path=faster_rcnn_inception_resnet_v2_atrous_coco.config
--train_dir=train
--num_clones=1
注:CUDA_VISIBLE_DEVICES=? “?”就是GPU的编号,window下set PYTHONPATH中间是分号";",linux下是冒号":"
9.sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True))可以在使用GPU不能训练时,切换到CPU,并打印出来
10.
pip安装某个版本tensorflow-gpu例如:pip install tensorflow-gpu==1.4.011.tensorflow禁用GPU,使用CPU:
12.用大的bitch size去榨干GPU的资源,提高GPU利用率,更快地到底收敛以及一定程度防止过拟合