结论:1.张量与数组运算,张量必须在cpu上,产生结果为cpu上的张量,可继续与数组运算(张量必须在gpu上)
2.张量与张量运算,cpu上的张量与gpu上的张量是无法运行的,必须在相同的gpu上或cpu上,猜想不同型号的gpu因该也不行。
一.张量与数组运算,前提张量必须在cpu上(如果张量在gpu上,则会报错(我认为数组本身在cpu上,因此2个操作在cpu上,就可以默认运行)),运算结果将会转到cpu上,具体操作如下:
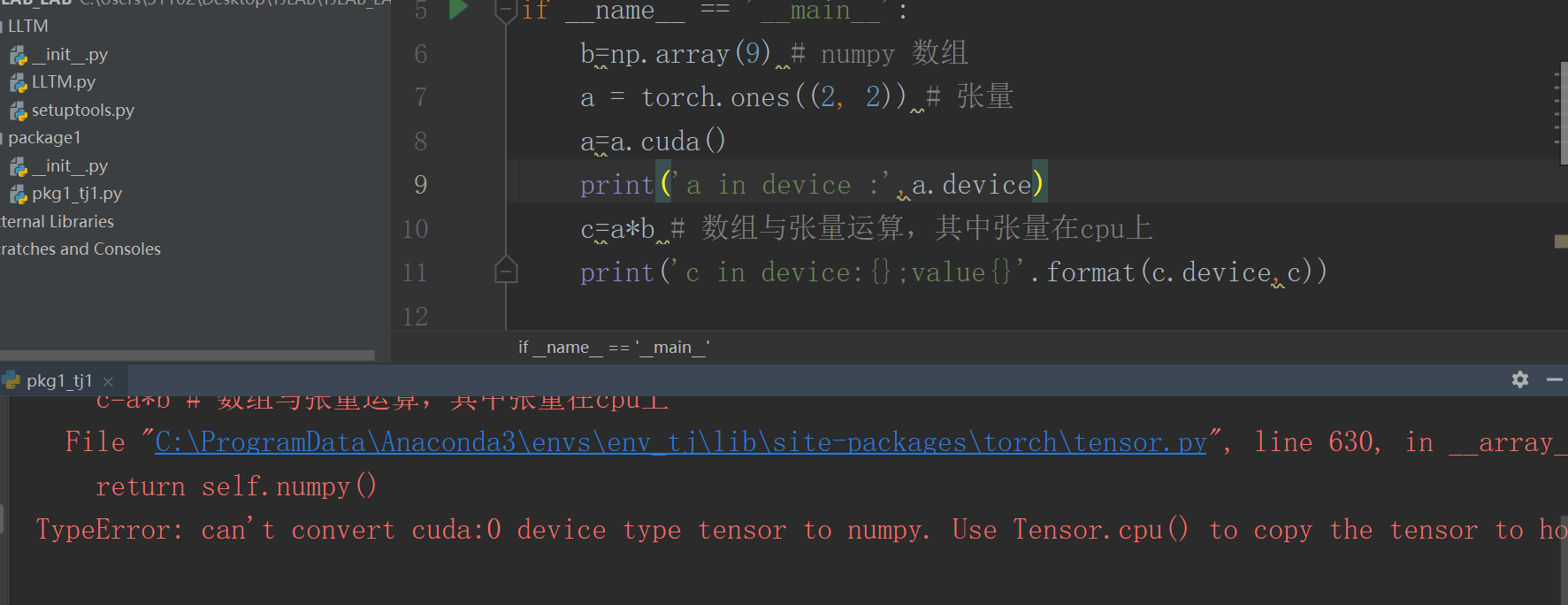
注:报错代码 TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
代码如下:
b=np.array(9) # numpy 数组
a = torch.ones((2, 2)) # 张量
print('a in device :',a.device)
c=a*b # 数组与张量运算,其中张量在cpu上
print('c in device:{};value{}'.format(c.device,c))
结果如图:

报错结果:
继续探讨张量与数组运算:
b=np.array(9) # numpy 数组
a = torch.ones((2,2)) # 张量
print('a in device :',a.device)
c=a*b # 数组与张量运算,其中张量在cpu上
print('c in device:{};value:{}'.format(c.device,c))
d=np.array(8)
e=c*d # 继续验证数组与产生的张量运算
print('e in device:{};value:{}'.format(e.device, e))
结果如图:

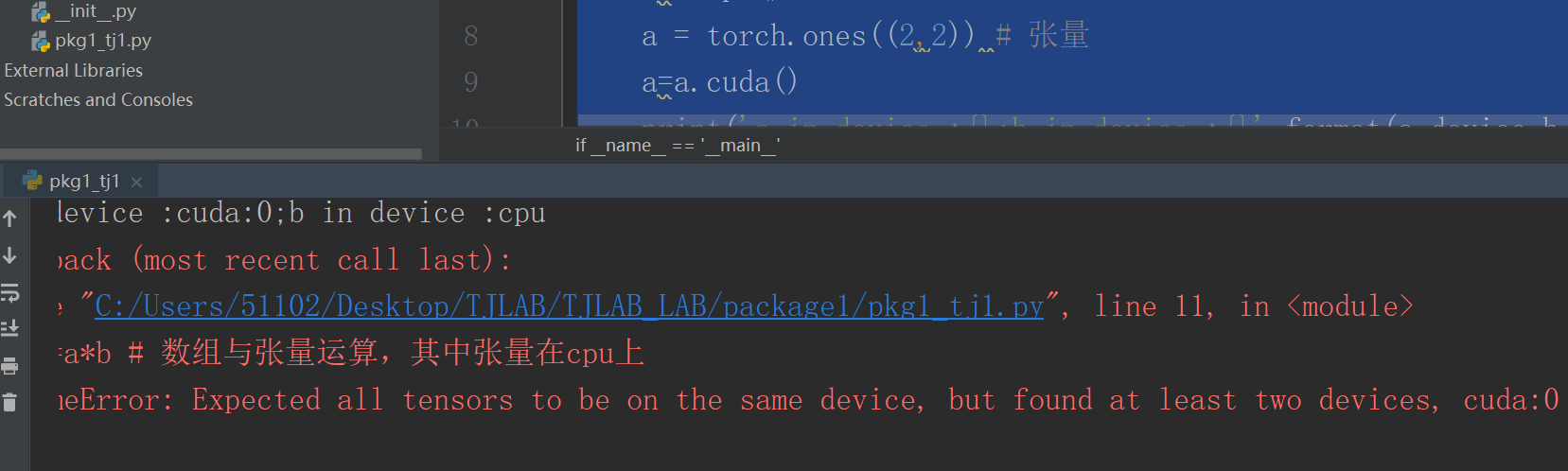
二.张量与张量运算,若在不同设备会报错,RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!,结论很清楚,而具体过程如下:
代码如下:
b=torch.ones((2,2)) # numpy 数组
b=b.cpu()
a = torch.ones((2,2)) # 张量
a=a.cuda()
print('a in device :{};b in device :{}'.format(a.device,b.device))
c=a*b # 数组与张量运算,其中张量在cpu上
print('c in device:{};value:{}'.format(c.device,c))
结果如下: