一、安装必要插件
测试环境:Windows 10 + Python 3.7.0
(1)安装Selenium
pip install selenium
(2)安装Requests
pip install requests
(3)Chrome WebDriver下载
每个版本支持的 Chrome版本是不一样的,必须要对应的版本才能驱动浏览器。
官方网站被墙,可以下载全版本的:http://npm.taobao.org/mirrors/chromedriver
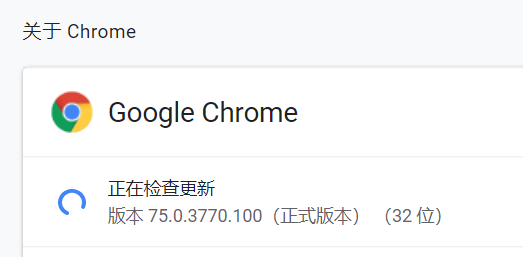
比如我的Chrome浏览器和Webdriver版本对应都用V75的:

(4)Chrome WebDriver安装
1. Windows 安装方法:
下载压缩包解压,chromedriver.exe 和python.exe 都放到python根目录下即可。
2. Linux 安装方法:
把解压的文件放到 /usr/bin 目录下,并且修改好权限。
二、代码模板
目标:使用代码控制浏览器访问指定的链接,并且每次访问使用不同的代理。
代理:使用的是大象代理的api接口提取代理IP。
这段代码稳定性还不错,超时等错误就会重启脚本继续获取新的代理IP,保证脚本能够长时间运行。
import random import requests import time from selenium import webdriver import sys import os # 随机获取浏览器标识 def get_UA(): UA_list = [ "Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19", "Mozilla/5.0 (Linux; U; Android 4.0.4; en-gb; GT-I9300 Build/IMM76D) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30", "Mozilla/5.0 (Linux; U; Android 2.2; en-gb; GT-P1000 Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1", "Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0", "Mozilla/5.0 (Android; Mobile; rv:14.0) Gecko/14.0 Firefox/14.0", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36" ] randnum = random.randint(0, len(UA_list)-1) h_list = UA_list[randnum] return h_list # 获取代理IP def get_ip(): # 这里填写大象代理api地址,num参数必须为1,每次只请求一个IP地址 url = 'http://www.baidu.com' response = requests.get(url) response.close() ip = response.text print(ip) return ip if __name__ == '__main__': url = "https://www.hao123.com/" # 无限循环,每次都要打开一个浏览器窗口,不是标签 while 1: # 调用函数获取浏览器标识, 字符串 headers = get_UA() # 调用函数获取IP代理地址,这里获取是字符串,而不是像前两个教程获得的是数组 proxy = get_ip() # 使用chrome自定义 chrome_options = webdriver.ChromeOptions() # 设置代理 chrome_options.add_argument('--proxy-server=http://'+proxy) # 设置UA chrome_options.add_argument('--user-agent="'+headers+'"') # 使用设置初始化webdriver driver = webdriver.Chrome(chrome_options=chrome_options) try: # 访问超时30秒 driver.set_page_load_timeout(30) # 访问网页 driver.get(url) # 退出当前浏览器 driver.close() # 延迟1~3秒继续 time_delay = random.randint(1, 3) while time_delay > 0: print(str(time_delay) + " seconds left!!") time.sleep(1) time_delay = time_delay - 1 pass except: print("timeout") # 退出浏览器 driver.quit() time.sleep(1) # 重启脚本, 之所以选择重启脚本是因为,长时间运行该脚本会出现一些莫名其妙的问题,不如重启解决 python = sys.executable os.execl(python, python, *sys.argv) finally: pass