语音识别主要分两大类:大词汇量连续语音识别技术(Large Vocabulary Continuous Speech Recognition,LVCSR)和关键词识别(keyword Spotting,KWS)。LVCSR由于对算力要求较高,一般在云端(服务器侧)做,而KWS对算力的要求相对较小,可以在终端上做。我们公司是芯片设计公司,主要设计终端上的芯片,想要在语音识别上做点事情,最可能的是做KWS,于是我们就选择KWS来实践语音识别。按距离远近,语音识别可分为近场识别和远场识别,远场的应用场景更丰富些,如智能音箱、智能家居等,如是远场的话需要用到麦克风阵列。讨论下来我们决定做远场下的关键词识别。图1是其框图:(麦克风阵列为圆阵且有四个麦克风,即有四个语音通道)
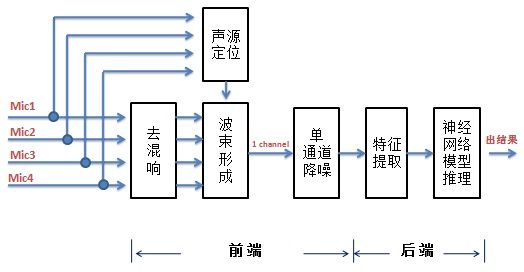
图 1
从上图可以看出,系统可以分为前端和后端两部分。前端主要包括去混响、声源定位和波速形成(beamforming)、单通道降噪四大模块。混响是指声音信号遇到墙壁、天花板、地面等障碍物形成反射声,并和直达声相叠加的现象。去混响就是去除那些叠加的声音。声源定位是利用多通道语音信号来计算目标说话人的角度和距离从而实现对目标说话人的跟踪,严格的声源定位是指同时确定说话人的角度(包括方位角、俯仰角)和距离。在消费级的麦克风阵列中,通常关心的是声源到达的方向,也就是波达方向(Direction of Arrival,DOA)。波束形成是对信号进行空域滤波,将多个通道的语音数据变成一个波束(即一个通道)的目标声源,目标声源的信干噪比(SINR)得到提升。单通道降噪是抑制单个通道上的噪声。后端主要包括特征提取和神经网络模型推理两大模块,特征提取是得到作为神经网络模型输入的语音的特征向量,神经网络模型推理是根据输入的特征向量计算出一个输出。不管是前端还是后端,对我们都是陌生的,讨论下来由于我们team人数较少就先从后端入手,有一个识别率较高的模型后再去做前端相关的。本篇先讲在后端上的一些实践,下篇讲在前端上的一些实践以及将前端和后端连起来形成一个完整的方案。
后端主要是语音识别相关的。语音识别分为训练和识别两个阶段。在训练阶段,用海量的相关的语料训练出一个识别率较高的神经网络模型。在识别阶段,采集到的语音经过前端处理后提取出特征向量再经过神经网络模型推理得到相应的输出。后端的主要工作如下:训练语料获取、语料数据增强、模型训练、模型量化、模型推理实现等。
1, 训练语料获取
训练语料一般有三种办法获得。一是用公开的语料库,中文比较出名的语料库有thchs30等,但这些公开的一般适用于LVCSR,不太适用于KWS,因为KWS是一些特定词。二是花钱买,三是自己录。花钱买的语料库一般较贵,当前我们处于起步阶段,所以我们决定自己录语料。自己录要先选定应用场景和关键词,讨论后我们选定了智能家居场景,关键词包括“打开空调”、“关闭空调”、“打开窗帘”、“拉上窗帘”等。定好关键词后就开始录音了,我们先后录过两次音。第一次录音是在做后端神经网络模型时,录的是单声道数据。找来5台安卓手机,装上录音软件easyrecord,放在一个安静的会议室里,距离说话人50CM左右处,示意如图2:
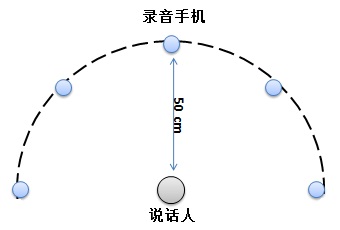
图 2
说话人先以正常语速说一遍关键词,然后以较快语速说一遍,最后以较慢语速说一遍。当时请了部门里几乎所有同学近100人参与录音,得到了一个我们自己定义的单声道关键词的语料库。由于人数较少,是一个小语料库。第二次录音是在做前端麦克风阵列中去混响、波束形成等算法时,录的是多声道数据。买来一块多声道采集的评估板放在一个大会议室里,同时评估板边上放风扇、菜场等噪声,说话人在相对远处不同的位置上说关键词,示意如图3:
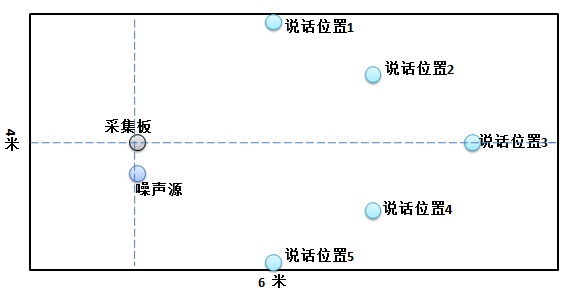
图 3
依旧是先以正常语速说一遍关键词,然后以较快语速说一遍,最后以较慢语速说一遍。这是一个带不同种类噪声的关键词多声道语料库。
2,对语料做数据增强
刚开始我们采集到语料后就开始训练模型了。由于录到的语料都是干净语音,模型训练好后干净语音识别率还可以,但是带噪语音就不行了。遇到问题就要找解决方法。调查后发现通常的做法是对语料做数据增强(augmentation)。所谓数据增强就是用一些音频处理的算法(比如加噪声)对已有的训练集里的语音(通常训练集里的语音是在安静的环境下录制的,比如录音棚里)进行一定的处理,让其变得更接近真实场景中的语音,来增加训练样本的多样性。基于神经网络的深度学习技术,通常都需要使用大量的数据来训练,语音识别也不例外。对一个语音识别系统而言,决定其识别准确率的关键因素,大致可以分为两个方面:一是模型本身的好坏;二是训练所使用的训练数据。对于训练数据而言,其与真实使用场景中的数据的匹配度越高,则语音识别的性能越好。实际应用中,语音识别的使用场景很复杂,环境噪声、人的说话方式,如音量、语速等,都会一定程度上影响语音识别系统的准确率。训练数据对这些复杂的情况覆盖得越全面,则语音识别系统的效果越好。为了构建一个强大的语音识别系统,应该广泛地搜集各种复杂的真实场景下的语音数据,来构建训练集。然而在现实条件下,想要做到这一点却很不容易,尤其对于中小厂商。因为不是每个厂商都有获取真实场景语音数据的渠道和能力,即使成功获得了真实场景的语音数据,数据标注也是一项极为费时费力费钱的工作。在训练集数据有限的情况下,可以通过数据增强的方法来扩充训练集数据,使训练集数据更多样性,来提高语音识别的准确率。我们用python开源库(nlpaug.augmenter.audio)做了数据增强,用的数据增强方法主要有如下几种:
1)Loudness:调整音频的音量(增大或减小)
2)Speed:调整音频的播放速度(加速或减速)
3)Pitch:调整音频的音高
4)Noise:加入噪声,主要有白噪声、粉红噪声、环境噪声等。
做好数据增强后语料库就增大了好多倍。用增大后的语料库去训练得到新的模型,再用带噪语音去测试模型识别率提高了好多。
3,模型训练
模型训练是个大话题,这里就简述了,主要分几块:语料库的数据预处理、模型选择和迭代训练及评估。这些都在python下实践。找一个开源的语音识别开源框架,并根据自己的需求改造。我们是在框架中基于keras来训练模型的。
1) 数据预处理
数据预处理主要包括语音的特征(feature)选取和提取以及标签(label)处理。语音识别里常用的特征是MFCC和Fbank。我们刚开始用的特征是MFCC,后来随着用的深入,发现Fbank的效果比MFCC好,就改成用Fbank了。特征提取就是把wav中的每帧PCM数据变成特征向量,作为神经网络模型的输入。标签(label)就是标注wav文件对应的内容。语音识别神经网络模型通常都是分类模型,且有不同的分类方法。可以以音素分类,分出来的音素类型有几十或者上百个,标注时就是以音素为标签(label),代码中每个音素都有一个数字ID。如果用作唤醒词识别(唤醒词识别是关键词识别的一个特例,只有一个关键词),就是一个典型的二分类问题,是唤醒词的标注为1,不是的标注为0。把这些label作为target也作为模型的输入。训练前要把语料分成训练集/验证集/测试集,通常比例是8:1:1。训练集和验证集用于训练,测试集用于评估。
2)模型训练和评估
模型训练的第一步是选择网络架构。对于语音识别,目前主流的网络架构有卷积神经网络(CNN)和循环神经网络(RNN/LSTM)等。我们根据项目的需求选择CNN作为网络架构(主要是因为CNN相对简单且有很多KWS论文里的网络模型可以参考)。网络架构确定后训练模型时最好先找一个相关论文里的成熟模型来借鉴,然后对其进行改进,最终通过训练确定CNN层数、每层的Kernel个数、Kernel Size、Stride等。训练过程就是用训练集的数据作为输入,经过网络前向传播计算出输出,再同事先设定的标签(label)进行loss计算(根据设定的损失函数计算),然后通过反向传播来更新权重后,再迭代进行前向传播、loss计算和反向传播更新权重,直至loss值达到预期效果的过程。根据应用场景我们先后训练出两个网络模型,多关键词网络模型和单关键词(即唤醒词)网络模型。多关键词网络模型是音素分类模型,以CTC为损失函数,网络模型输出是每个音素的概率值,概率最大的那个音素作为输出,后接CTC解码,得到结果。唤醒词网络模型是二分类模型,以交叉熵为损失函数,网络模型输出是唤醒词和非唤醒词的概率值,再设定一个是唤醒词概率的阈值,如果输出的唤醒词概率大于阈值,就认为是唤醒词了,反之不是。
模型训练好后要对其进行评估,看是否满足要求。KWS模型一般都是分类模型,对于分类模型,曾写过文章介绍过评价指标,具体见《深度学习分类问题中accuracy等评价指标的理解》。只有这些评价指标都符合要求了,模型训练工作才算结束。否则要分析不达标的原因,找解决方法,再重新训练,直到所有指标都达标。模型训练就是一个不断重复迭代的过程。
4,模型量化
训练好的模型中的参数都是浮点数,在识别过程中模型推理(inference)时为了降低CPU load和节省memory,需要对模型做量化处理。至于具体怎么做,请参见曾写过的文章《深度学习中神经网络模型的量化》。
5,模型推理实现
KWS模型训练是在python下完成的,但识别推理是在嵌入式系统上完成,因此要用其他语言把模型推理实现了。嵌入式系统上最常用的语言是C,我们就用C实现了模型推理。实现过程中参考了CMSIS的代码。为了节省memory,我们对实现过程做了优化,具体见曾写过的文章《嵌入式设备上卷积神经网络推理时memory的优化》。
以上就是后端的主要工作。写起来简单,其实都是需要花不少时间的,尤其在模型训练上。如果是第一次做,则需要花更多的时间,有一个摸索的过程。