前面的几篇文章讲了webRTC中的语音降噪。最近又用到了基于MCRA-OMLSA的语音降噪,就学习了原理并且软件实现了它。MCRA主要用于噪声估计,OMLSA是基于估计出来的噪声去做降噪。类比于webRTC中的降噪方法,也有噪声估计(分位数噪声估计法)和基于估计出来的噪声降噪(维纳滤波),MCRA就相当于分位数噪声估计法,OMLSA就相当于维纳滤波。本文先讲讲怎么用MCRA和OMLSA来做语音降噪的原理,后续会讲怎么来做软件实现。
一, MCRA
MCRA的全称是Minima Controlled Recursive Averaging(最小值控制的递归平均),是cohen提出的一种常用的噪声估计方法,具体见论文《Noise Estimation by Minima Controlled Recursive Averaging for Robust Speech Enhancement》。 从名字就可看出这个方法主要包括两部分,最小值控制和递归平均。 最小值控制用来算语音存在概率,递归平均用来做噪声估计,即基于语音存在概率做噪声估计。先定义一些名称,然后分别看这两部分。用l表示第l帧,k表示第k个频点,Y(k, l)表示带噪语音第l帧的第k个频点的幅度谱,N(k, l)表示噪声第l帧的第k个频点的幅度谱,S(k, l)表示干净语音第l帧的第k个频点的幅度谱,H0(k, l)表示第l帧的第k个频点上只有噪声,H1(k, l)表示第l帧的第k个频点上有语音。P(H1(k, l) | Y(k, l)) 表示第l帧的第k个频点上是语音的概率,P(H0(k, l) | Y(k, l)) 表示第l帧的第k个频点上是噪声的概率,显然P(H0(k, l) | Y(k, l)) + P(H1(k, l) | Y(k, l)) = 1。
1, 用最小值控制来算语音存在概率
前面的文章( webRTC中语音降噪模块ANS细节详解(四) )讲过webRTC的ANS是基于似然比等来算语音存在概率。而这里是用最小值控制来算语音存在概率,即基于当前带噪语音的能量谱与指定长度帧内带噪语音的能量谱的最小值的比值来计算,具体如下:
1) 对带噪语音的能量谱做频域平滑和时域平滑
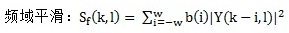
从上式可见,平滑窗的长度是奇数(2w + 1),系数是b(i)。
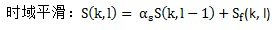
其中,αs (0 < αs < 1)是平滑因子。
2) 搜索能量谱最小值
定义Smin(k, l)和Stmp(k, l),并对它们初始化如下:

然后按频点从第一帧开始逐帧比较:
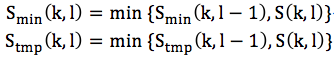
当到第L帧后:
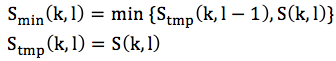
后面以L帧为一个周期,重复上面两步,得到这个周期内的Smin(k, l)和Stmp(k, l)。搜索窗的帧长度L会影响到噪声的跟踪速度,一般按照经验选0.5s~1.5s左右。
3) 计算语音存在概率
定义Sr(k, l)为当前帧相应频点的能量谱与最小值的比值,即
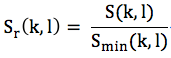
再定义二值I (k, l)如下:
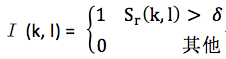
最终语音存在概率通过下式得到:
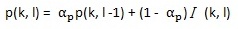
其中,αp (0 < αp < 1)是平滑因子。此处的p(k, l)就是P(H1(k, l) | Y(k, l))。为书写方便,下文用p表示P(H1(k, l) | Y(k, l)),用1-p表示P(H0(k, l) | Y(k, l))。
2, 用递归平均来估计噪声
通常认为噪声都是加性噪声,所以有下式:
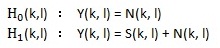
定义σ(k, l)表示第l帧的第k个频点上的噪声能量谱。这里噪声更新的思路如下:当语音不存在时更新噪声的估计,当语言存在时用前一帧的噪声估计值作为当前噪声的估计值,表示如下式:
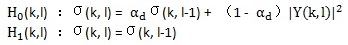
其中,αd (0 < αd < 1)是平滑因子。
所以噪声能量谱的估计如下式(p = P(H1(k, l) | Y(k, l)),为语音存在概率):
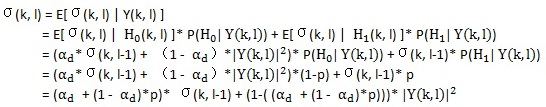
αd是tuning出来的,每个频点上的语音存在概率是上面基于最小控制的方法算出来的,上一帧估计出来的噪声能量谱σ(k, l-1)和当前帧的带噪语音的能量谱均已知,这样当前帧的估计出来的噪声的能量谱就可求出了。
通常令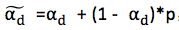 ,这样上式就可写成下式:
,这样上式就可写成下式:
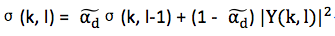
这就是噪声估计的数学表达式。
二, OMLSA
噪声估计出来后就要基于它做降噪了。这里用的是OMLSA(Optimally Modified Log-Spectral Amplitude Estimator,最优修正的对数幅度谱估计),依旧是cohen提出来的,论文是《Optimal Speech Enhancement Under Signal Presence Uncertainty Using Log-Spectral Amplitude Estimator》。OMLSA是MMSE-LSA的改进算法,目的是得到增益gain。算法推导有些复杂,这里只给出gain的表达式,如下:
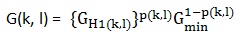
其中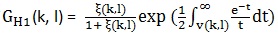 ,Gmin为预先设定的值,p(k, l)是语音存在概率。这里
,Gmin为预先设定的值,p(k, l)是语音存在概率。这里 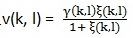 , ξ(k, l)是先验性噪比,γ(k, l)是后验性噪比。先验性噪比和后验性噪比在文章(webRTC中语音降噪模块ANS细节详解(一) )中讲过。后验性噪比的计算基于上面用MCRA估计出来的噪声,
, ξ(k, l)是先验性噪比,γ(k, l)是后验性噪比。先验性噪比和后验性噪比在文章(webRTC中语音降噪模块ANS细节详解(一) )中讲过。后验性噪比的计算基于上面用MCRA估计出来的噪声, , 先验性噪比计算依旧用文章( webRTC中语音降噪模块ANS细节详解(三) )中提到的DD方法,表达式如下:
, 先验性噪比计算依旧用文章( webRTC中语音降噪模块ANS细节详解(三) )中提到的DD方法,表达式如下:
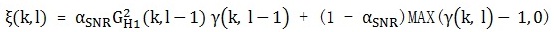
其中,αSNR (0 < αSNR < 1)是平滑因子。
G(k, l)得到后,降噪后干净语音的每个频点的幅度谱可通过下式得到:
S(k, l) = G(K, l)Y(k, l)
以上就是基于MCRA-OMLSA的语音降噪原理。这里需要指出的是噪声估计和语音降噪相对独立,有不同的组合方式来降噪,比如MCRA也可以和维纳滤波结合来降噪。