获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
有一个员工明细表employees如下:

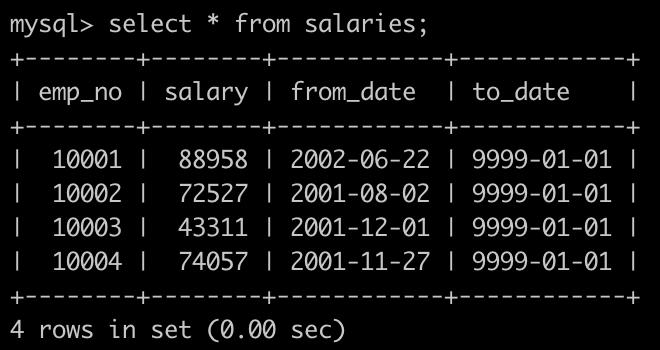
员工对应的薪水表
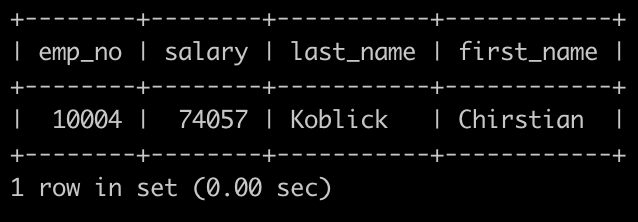
请你查找薪水排名第二多的员工编号(emp_no)、薪水(salary)、last_name以及first_name,
不能使用order by
输出结果:
解题思路:1. 使用 max函数
获取薪水第二多的员工,又不能使用order by语句,则必须用到 max 函数,找到 salary最大值,再找到 {所有小于最大值的值} 中的最大值(重复利用max)
首先找到 salary 的最大值
① select max(salary) from salaries
根据最大值找到salary的第二大值
② SELECT max(salary) FROM salaries
WHERE salary <(①)
根据salary第二大值,联结两表,找到该值对应的员工编码
select e.emp_no, salary, last_name, first_name
from employees as e left join salaries as s
on e.emp_no = s.emp_no
where salary =( ②)
最终的结果即为:
select e.emp_no, salary, last_name, first_name
from employees as e left join salaries as s
on e.emp_no = s.emp_no
where salary = (SELECT max(salary) FROM salaries
WHERE salary <(select max(salary) from salaries))
解题思路: 2 获得salary排名
利用一个算法算出各个数值的排名,选择排名第二的即可
排名算法:
假设共X个数字,则 ≤ 最大值的数共有 X个,≤ 第二大值 的数有X-1个
只需算出每个值 Xi 比Xi 小的数有几个即可知道其排名
可以利用salary表的自链接,来统计比每个值小的值的数量,
① select s1.salary,count(*) as c from
salaries as s1 join salaries as s2
on s1.salary <= s2.salary --(这里用< 或 > 均可, 不同符号的排序不一样,刚好相反)
group by s1.salary
选择①中salary排名第二的
②select salary from (①) where c = 2
再将employees和salary链接,选择salary=① 中排名第二的即可
③select e.emp_no, salary, last_name, first_name
from employees as e left join salaries as s
on e.emp_no = s.emp_no
where salary = (②) as temp
思路2优化
上述方法思路正确,但是嵌套太多子查询,
进一步优化,减少子查询次数:使用一次查询便获得排名第二的salary数值
① select s1.salary from
salaries s1 join salaries s2 on s1.salary <= s2.salary
group by s1.salary
having count(s1.salary) = 2
② select e.emp_no, salary, last_name, first_name
from employees as e left join salaries as s
on e.emp_no = s.emp_no
where salary = (①)
注:
-
- 在①中,要保证 select 的列 和 group by 的列是一致的;
-
- count()中可以放任意列均可,放“ * ”也可以
-
- on 语句中,比较 s1.salary 和 s2.salary 必须带 = , 只有< 或 > 时会导致最大或最小值的出现次数为0,加上 = 可以保证每个值至少出现一次。
-
- " < " 和" > "符号 和排序的关系: 在“大于”(>的左侧或<的右侧)侧的列,数值越大,它的出现次数越多(count(*)的值越大);在“小于”一侧的列,数值越大出现次数越少。 又因为我们将数值的出现次数作为其在列中的排名,所以,在“大于”侧,数值升序排列;在“小于”侧,数值降序排列。
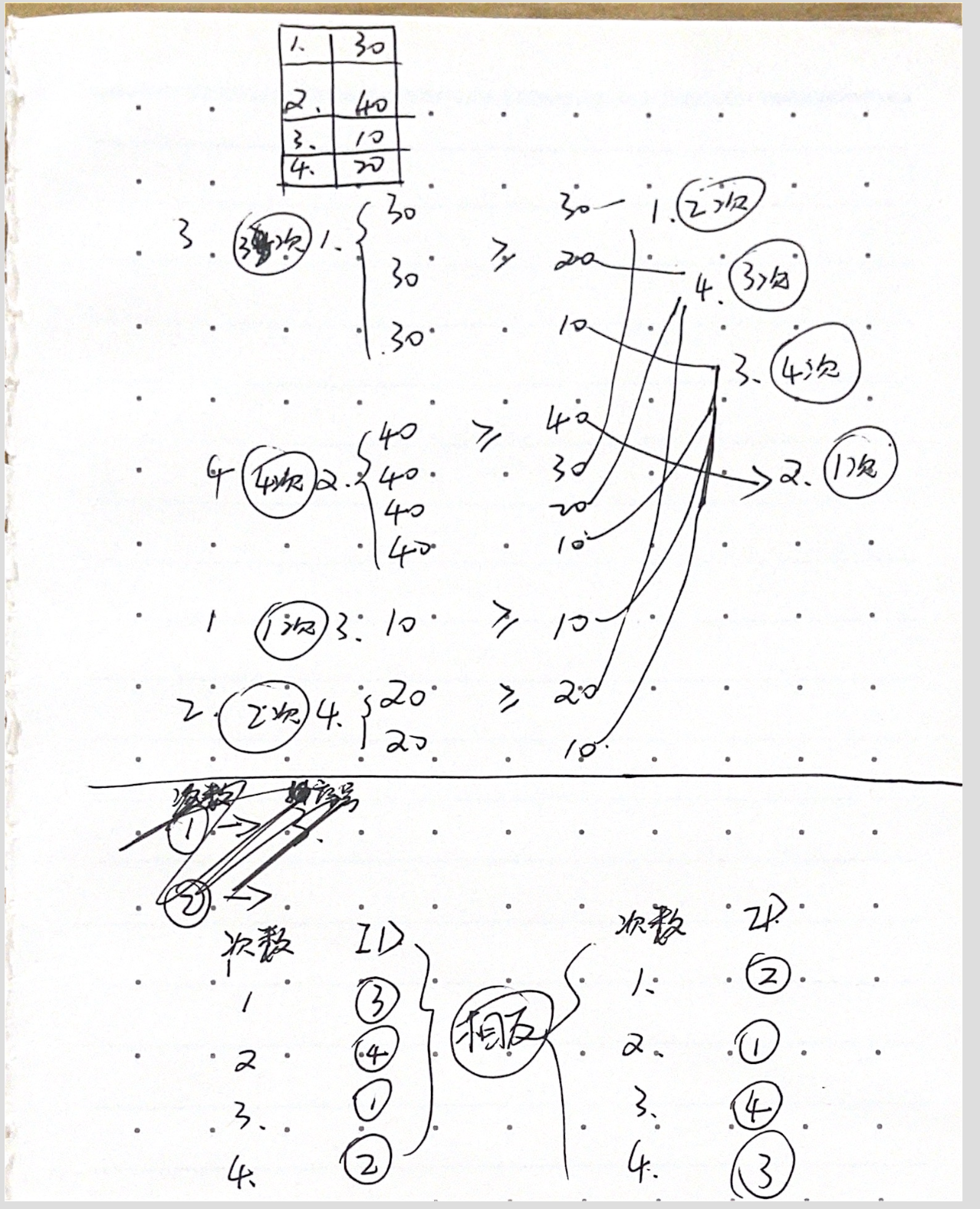
- " < " 和" > "符号 和排序的关系: 在“大于”(>的左侧或<的右侧)侧的列,数值越大,它的出现次数越多(count(*)的值越大);在“小于”一侧的列,数值越大出现次数越少。 又因为我们将数值的出现次数作为其在列中的排名,所以,在“大于”侧,数值升序排列;在“小于”侧,数值降序排列。
建表语句:
drop table if exists employees ;
drop table if exists salaries ;
CREATE TABLE employees (
emp_no int(11) NOT NULL,
birth_date date NOT NULL,
first_name varchar(14) NOT NULL,
last_name varchar(16) NOT NULL,
gender char(1) NOT NULL,
hire_date date NOT NULL,
PRIMARY KEY (emp_no));
CREATE TABLE salaries (
emp_no int(11) NOT NULL,
salary int(11) NOT NULL,
from_date date NOT NULL,
to_date date NOT NULL,
PRIMARY KEY (emp_no,from_date));
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'2001-08-02','9999-01-01');
INSERT INTO salaries VALUES(10003,43311,'2001-12-01','9999-01-01');
INSERT INTO salaries VALUES(10004,74057,'2001-11-27','9999-01-01');
总结,通过表的内链接,并使用 合适的字段的比较 作为链接条件,可以间接获得表中某字段的值的排名
通过合理安排子查询的字段和字段个数,可以减少子查询的嵌套层数。
第一种子查询,得到有 salary和cout(*)两个字段的子表,要想获得salary的值,需要再次查询此表
而第二种,直接得到一个只有salary一个字段的子表,同时通过后面的having条件,限制cout(*)的数值,直接得到排名第二的salary数值。
(可以看出,即使select后面没有直接跟count(*),也可以在最后面用 having count(*) 做筛选条件对结果进行筛选)