jvm是什么:
java virtual machine,程序在编译时,通过jvm编译为字节码(class文件),这样可以跨平台执行,在执行时是由jvm解释执行的。
jvm体系图:



类加载器:
运行时,.class文件由类加载器加载到内存中成为Class类的一个实例,每个这样的实例用来表示一个 Java 类。通过此实例的 newInstance()方法就可以创建出该类的一个对象。
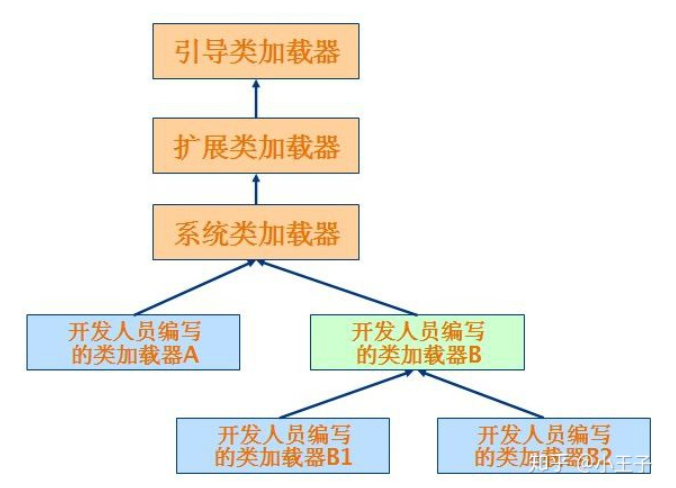
有三种类加载器,他们之间有继承关系,加载的类的范围也不一样。

这是继承关系:
以下代码可以用来测试一下类加载器
public class TestClass { public static void main(String[] args) { Car car = new Car(); System.out.println(car.getClass()); System.out.println(car.getClass().getClassLoader()); System.out.println(car.getClass().getClassLoader().getParent()); String a="dfsf"; System.out.println(a.getClass().getClassLoader()); } }
双亲委派机制:
- 如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成。
- 每一个层次的类加载器都是如此。因此,所有的加载请求最终都应该传送到顶层的启动类加载器中。
- 只有当父加载器反馈自己无法完成这个加载请求时(搜索范围中没有找到所需的类),子加载器才会尝试自己去加载。
- 为了保护安全,不能用户自己随便写一个String类,结果就加载了这个类。
Native方法


这种start0方法就进了本地方法栈---本地方法接口--本地方法库
JNI java native interface
PC寄存器

方法区
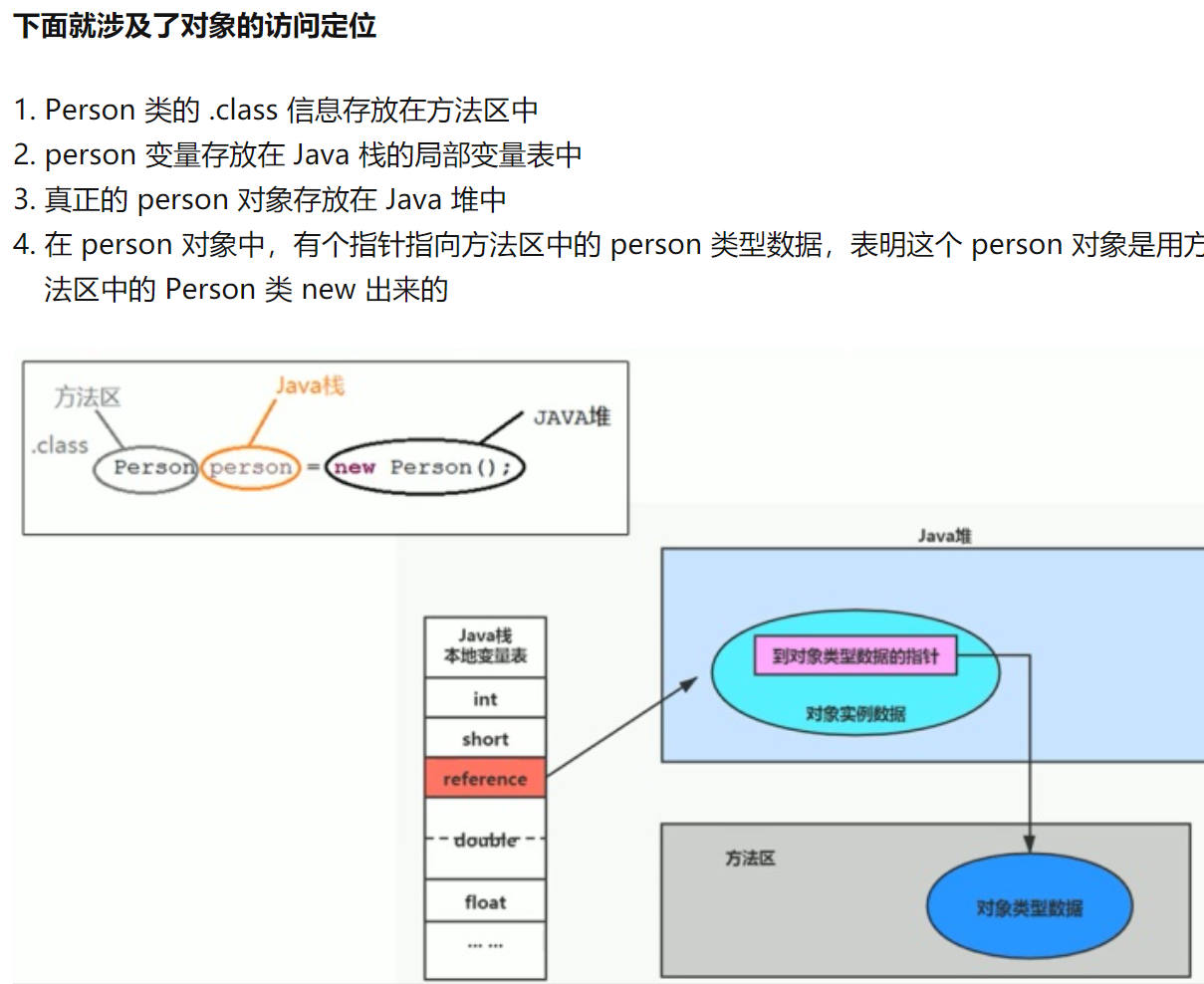
对象的加载过程
public class Person{ int age; String name; public void walk() { System.out.println("我正在走路。。。。"); } }
然后我们测试一下:
public class Test { public static void main(String[] args) { Person person = new Person(); person.name = "java的架构师技术栈"; person.age = 18; person.walk(); } }
我们分析一下这个过程
第一步,JVM去方法区寻找Test类的代码信息,如果有直接调用,没有的话使用类的加载机制把类加载进来。同时把静态变量、静态方法、常量加载进来。这里加载的是(“冯冬冬的IT技术栈”,“冯XX”);这是因为字符串是常量,age中的18是基本类型。
第二步,jvm进入main方法,看到Person person=new Person()。首先分析Person这个类,同样的寻找Person类的代码信息,有就加载,没有的话类加载机制加载进来。同时也加载静态变量、静态方法、常量(“我正在走路。。。”)
第三步,jvm接下来看到了person,person在main方法内部,因而是局部变量,存放在栈空间中。
第四步,jvm接下来看到了new Person()。new出的对象(实例),存放在堆空间中。
第五步,jvm接下来看到了“=”,把new Person的地址告诉person变量,person通过四字节的地址(十六进制),引用该实例。 是不是有点晕,别着急,画个图看一下。
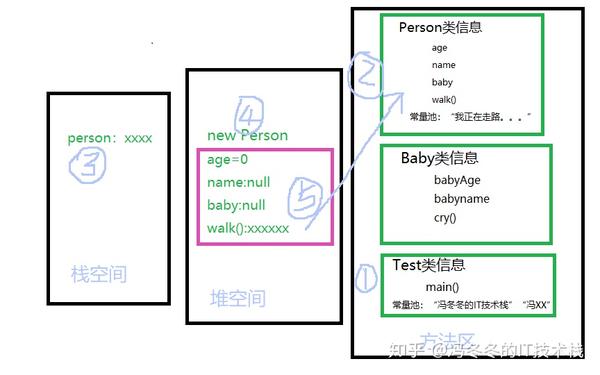
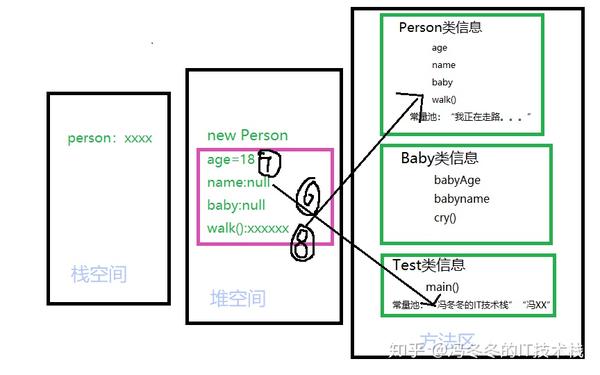
第六步,jvm看到person.name = “冯冬冬的IT技术栈”;person通过引用new Person实例的name属性,该name属性通过地址指向常量池的"冯冬冬的IT技术栈"。
第七步,jvm看到person.age = 18; person的age属性是基本数据类型,直接赋值。
第八步,jvm看到person.walk(); 调用实例的方法时,并不会在实例对象中生成一个新的方法,而是通过地址指向方法区中类信息的方法。走到这一步再看看图怎么变化的
虚拟机栈
栈和队列原来老是有点弄得晕,现在看这个比喻挺好的。
栈就是桶,先放进去当然后面才能拿出来。
队列就是先进先出了FIFO(first in first out)。
栈是跟线程的,生命周期和线程同步。每个线程对应一个独立的stack。线程结束,栈内存就释放,对于栈不存在垃圾回收问题。
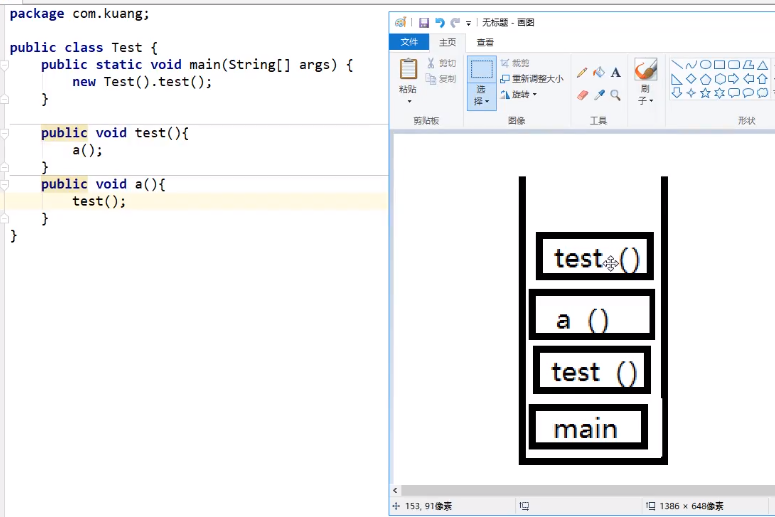
这个栈的过程,栈走完之后会弹出栈。
栈是由这些栈帧组成的,一个方法对应一个栈帧。

方法中的基本类型变量是放在这个本地变量表中的,非基本类型会在这放一个引用(指向内存地址)。
JVM堆中存的是对象。JVM栈中存的是基本数据类型和JVM堆中对象的引用。一个对象的大小是不可估计的,或者说是可以动态变化的,但是在JVM栈中,一个对象只对应了一个4btye的引用(JVM堆JVM栈分离的好处:))。
为什么不把基本类型放JVM堆中呢?因为其占用的空间一般是1~8个字节——需要空间比较少,而且因为是基本类型,所以不会出现动态增长的情况—— 长度固定,因此JVM栈中存储就够了,如果把他存在JVM堆中是没有什么意义的(还会浪费空间,后面说明)。可以这么说,基本类型和对象的引用都是存放在 JVM栈中,而且都是几个字节的一个数,因此在程序运行时,他们的处理方式是统一的。但是基本类型、对象引用和对象本身就有所区别了,因为一个是JVM栈 中的数据一个是JVM堆中的数据。最常见的一个问题就是,Java中参数传递时的问题。
StackOverflow,栈溢出错误。如果你无限压栈就会,例如递归调用方法层数太多。