对于链表还是不甚熟悉啊。。。
160 相交链表
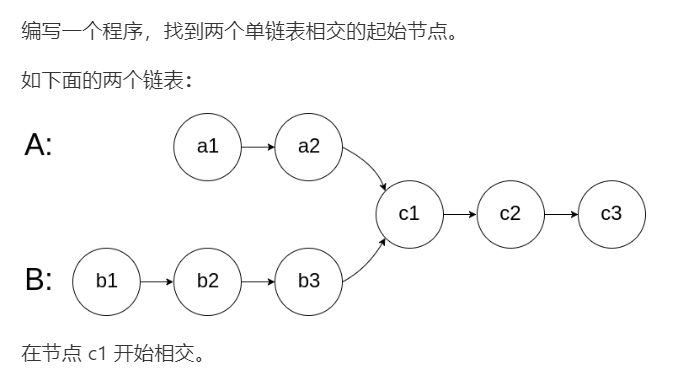
思路:
这道题自己看其实并没有什么思路。思考的时候主要的难度在于从A和B同时往前走的话,会因为离交点的距离不同“错过”C1这个交点。当然我们可以遍历一遍A链表,把每个元素记下来,再遍历B链表找匹配,这样的空间复杂度为O(n)。
好的解法则比较巧妙了(没有套路)

确实比较巧妙,把握住了L1和L2相等(两个都能找到的起点,和都以交点为终点)的特点,这样两边同时出发,就能以空间复杂度O(1)解决问题。
代码:
/** * Definition for singly-linked list. * public class ListNode { * int val; * ListNode next; * ListNode(int x) { * val = x; * next = null; * } * } */ public class Solution { public ListNode getIntersectionNode(ListNode headA, ListNode headB) { ListNode pA=headA; ListNode pB=headB; while(pA!=pB) { if(pA==null) {pA=headB;} else {pA=pA.next;} if(pB==null) {pB=headA;} else {pB=pB.next;} } return pA; } }
725分隔链表

思路:这道题一开始有点点懵,但马上就有了思路,想到了之后还觉得是不是太简单了。但由于对于链表操作层面的不熟,搞了好久都没有把正确的代码写出来(没有理解如何断开链表)
怎么分长度倒是很简单。先遍历求出链表长度len。len/k得到每段平均长度partA,len%k得到前partB段需要在partA上加一。
原来的循环想的是分两段循环,先循环partB次,再循环k-partB次。但其实是多此一举,设置一个partB--,再用三元运算符确定+1或+0.
双指针一开始还没想清楚为什么,导致老是搞错。。。其实第一个指针start是用来指下一段开头位置的(用于遍历),end指针则是用于指示start遍历时的上一个位置,最后在完成一段时用于断开前一段的链表!这个断开的操作是关键操作,如果不把上一段的末尾指向null,则会变为[[1,2,3,4],[2,3,4]...]这样。所以,链表的开头取决于这个ListNode=root的root,它的结尾取决于end.next=null的位置在哪。
如何处理null其实也挺巧妙的,因为假如到start已经为null了,那么partA已经变为了0,所以不会出现null.next的报错问题。
这张图挺好的,摘录一下:

代码:
/** * Definition for singly-linked list. * public class ListNode { * int val; * ListNode next; * ListNode(int x) { val = x; } * } */ class Solution { public static ListNode[] splitListToParts(ListNode root, int k) { int count=0; int partA,partB; ListNode countroot=root; ListNode[] listNodes=new ListNode[k]; while(countroot!=null) { count+=1; countroot=countroot.next; } partA=count/k; partB=count%k; ListNode end=null,start=root; for (int i=0;i<k;i++) { listNodes[i]=start; int len=(i<partB)?1:0; for (int j=0;j<partA+len;j++) { end=start; start=start.next; } if (end!=null) {end.next=null;} } return listNodes; } }
两道题需要注意的点:
- 第一道题的特殊解法
- 遍历使用的是p=p.next
- 链表的开头 和结尾分别由什么决定
- 如何完整遍历链表或求链表长度,判断条件是p!=null
- 三元运算符的使用
- 注意出现null.next的常见错误