之前我们在Linux上安装了dlib(http://www.cnblogs.com/take-fetter/p/8318602.html),也成功的完成了之前的人脸检测程序,
今天我们来一起学习怎样使用dlib创建属于自己的简单的物体识别器(这里以手的检测为例,特别感谢https://handmap.github.io/dlib-classifier-for-object-detection/)
- imglab的介绍与安装
imglab是dlib提供的个工具,位于github dlib开源项目的tools目录下.imglab是一个简单的图形工具,用对象边界来标注图像盒子和可选的零件位置。 一般来说,你可以在需要时使用它
以训练物体检测器(例如脸部检测器),因为它允许你轻松创建所需的训练数据集。
(源码位于https://github.com/davisking/dlib/tree/master/tools/imglab 如果有兴趣使用的话建议先下载整个dlib项目并安装dlib后再对本工具进行编译)
编译依次使用
cd dlib/tools/imglab
mkdir build
cd build
cmake ..
cmake --build . --config Release
不建议使用readme.txt中关于sudo make install的命令,因为我使用之后出现了无法显示图像的错误
- 训练自己的手检测器(关于手的图片的dataset可以参考Hand Images Databases - https://www.mutah.edu.jo/biometrix/hand-images-databases.html提供的数据集
或http://www.robots.ox.ac.uk/~vgg/data/hands/的相关数据集)
使用cmake后的build文件目录下(windows则位于release目录中)完成如下操作
使用
./imglab -c mydataset.xml 图片目录
创建mydataset.xml完成创建mydataset.xml 和image_metadata_stylesheet.xsl的样式表
使用
./imglab mydataset.xml
会打开一个窗口,这里就需要对每张图片进行位置的框选,在Next Label中输入框选信息,并对每张图片进行框选(按住shift并鼠标左键点击拖动画框)
在将对图片全标注后,在files选项中点击save,我们便可以关闭窗口,此时打开mydataset.xml可以看到其中包含了图片信息,如图
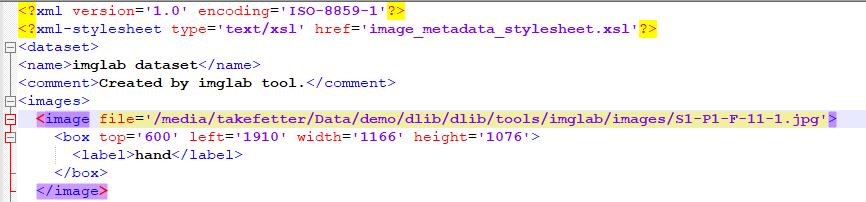
之后将mydataset.xml 和image_metadata_stylesheet.xsl放入图片目录中,运行如下代码进行训练(可能会出现图片目录出错的情况,这里需要对mydataset.xml中的图片位置进行确认)
代码改自dlib的python_examples,如果要自己尝试,建议先认真看下github中的代码(https://github.com/davisking/dlib/blob/master/python_examples/train_object_detector.py)
运行程序需使用scikit-image使用pip install scikit-image 安装
import os import sys import glob import dlib from skimage import io # In this example we are going to train a face detector based on the small # faces dataset in the examples/faces directory. This means you need to supply # the path to this faces folder as a command line argument so we will know # where it is. if len(sys.argv) != 2: print( "Give the path to the examples/faces directory as the argument to this " "program. For example, if you are in the python_examples folder then " "execute this program by running: " " ./train_object_detector.py ../examples/faces") exit() faces_folder = sys.argv[1] # Now let's do the training. The train_simple_object_detector() function has a # bunch of options, all of which come with reasonable default values. The next # few lines goes over some of these options. options = dlib.simple_object_detector_training_options() # Since faces are left/right symmetric we can tell the trainer to train a # symmetric detector. This helps it get the most value out of the training # data. options.add_left_right_image_flips = True # The trainer is a kind of support vector machine and therefore has the usual # SVM C parameter. In general, a bigger C encourages it to fit the training # data better but might lead to overfitting. You must find the best C value # empirically by checking how well the trained detector works on a test set of # images you haven't trained on. Don't just leave the value set at 5. Try a # few different C values and see what works best for your data. options.C = 5 # Tell the code how many CPU cores your computer has for the fastest training. options.num_threads = 4 options.be_verbose = True training_xml_path = os.path.join(faces_folder, "palm-landmarks.xml") testing_xml_path = os.path.join(faces_folder, "testing.xml") # This function does the actual training. It will save the final detector to # detector.svm. The input is an XML file that lists the images in the training # dataset and also contains the positions of the face boxes. To create your # own XML files you can use the imglab tool which can be found in the # tools/imglab folder. It is a simple graphical tool for labeling objects in # images with boxes. To see how to use it read the tools/imglab/README.txt # file. But for this example, we just use the training.xml file included with # dlib. dlib.train_simple_object_detector(training_xml_path, "detector.svm", options)
接下来就是等待训练完成(当然在这里说下,数据集不宜过大,会导致内存不足而OS自动杀死线程/进程的情况),options中的参数很多需要自行根据情况调节的
训练完成后会生成detector.svm文件,使用如下程序进行一个简单的测试:
import imutils import dlib import cv2 import time detector = dlib.simple_object_detector("detector_from_author.svm") image = cv2.imread('test0.jpg') image = imutils.resize(image, width=500) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) rects = detector(gray, 1) #win_det = dlib.image_window() #win_det.set_image(detector) #win = dlib.image_window() for (k, d) in enumerate(rects): print("Detection {}: Left: {} Top: {} Right: {} Bottom: {}".format( k, d.left(), d.top(), d.right(), d.bottom())) cv2.rectangle(image, (d.left(), d.top()), (d.right(), d.bottom()), (0, 255, 0), 2) #win.add_overlay(rects) cv2.imshow("Output", image) cv2.waitKey(0)
运行结果

可以看到完成了手的检测。
后记:
- 训练时间很长,希望能耐心等待
- 再次特别感谢Nathan Glover以及他的教程https://handmap.github.io/dlib-classifier-for-object-detection/
- 如果要制作精度很高的检测器,并不建议使用本方法,因为我们最终生成的svm文件相比于dlib作者的人脸识别检测器而言相差甚远。
- 我认为dlib提供的imglab功能很少,不适用于大规模的需要高精度的识别情况(不过人脸识别还是很不错的)
- 对于需要高精度高准确率的物体识别,使用Tensorflow Object Detection API应该更为合适(https://github.com/tensorflow/models/tree/master/research/object_detection)