基于LinkedHashMap实现一个基于LRU算法的缓存设计
1.LinkedHashMap可以认为是HashMap+LinkedList,即它既使用HashMap操作数据结构,又使用LinkedList维护插入元素的先后顺序。
2.LinkedHashMap的基本实现思想就是----多态。可以说,理解多态,再去理解LinkedHashMap原理会事半功倍;反之也是,对于LinkedHashMap原理的学习,也可以促进和加深对于多态的理解。
讲一下LinkedHashMap的实现LRU算法
3.LRU算法:内存管理的一种页面置换算法,对于在内存中但又不用的数据块(内存块)叫做LRU,操作系统会根据哪些数据属于LRU而将其移出内存而腾出空间来加载另外的数据。
package collections;
import java.util.LinkedHashMap;
/**
* 基于LinkedHashMap实现一个基于LRU算法的缓存设计
* 思考:
* 1)MyBatis中缓存的设计
* 2)Spring中的缓存设计
* 3)EhCache中缓存设计
* 4)redis中缓存设计
* 5).....................
* 自定义LruCache实现
* 1)有容量限制
* 2)容器满了要基于LRU算法移出元素
*/
class LruCache extends LinkedHashMap<String,Object>{
private static final long serialVersionUID = -1838771409260368496L;
/**设计缓存的最大容量*/
private int maxCapacity;
public LruCache(int maxCapacity) {
super(maxCapacity,0.75f, true);
this.maxCapacity=maxCapacity;
}
/**
* 方法的返回值决定了容器在满的时是否移除元素.
* true:表示要移除
* false:表示不移除
*/
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<String, Object> eldest) {
return size()>maxCapacity;
}
}
public class TestLinkedHashMap02 {
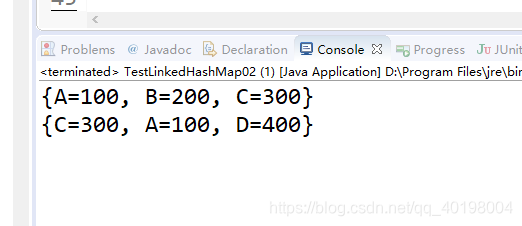
public static void main(String[] args) {
LruCache cache=new LruCache(3);
cache.put("A", 100);
cache.put("B", 200);
cache.put("C", 300);
System.out.println(cache);
cache.get("A");
cache.put("D", 400);
System.out.println(cache);//CAD
}
}
4.运行结果,LRU算法就是移除不常用的,分析,获取A,放入D,只能存放3个,所以移除B