C#中数据流的功能非常的多,在文件夹目录浏览,读入写出文件,异步IO,异步网络编程等都可以用到
1. 递归显示目录
1 using System; 2 using System.Collections.Generic; 3 using System.IO; 4 using System.Text; 5 6 namespace StreamTester 7 { 8 class Tester 9 { 10 static int dirCounter = 1; 11 static int indentLevel = -1; 12 13 public static void Main() 14 { 15 Tester t = new Tester(); 16 17 // 选择根目录 18 string theDirectory = 19 Environment.GetEnvironmentVariable("SystemRoot"); 20 // 如果是在unix linux 等其他系统下,要加下面一句话 21 //string theDirectory = "/tmp"; 22 23 //下面调用方法来浏览该目录,显示数据及子目录 24 25 DirectoryInfo dir = new DirectoryInfo(theDirectory); 26 27 t.ExploreDirectory(dir); 28 29 Console.WriteLine( 30 " {0} directories found. ", 31 dirCounter); 32 } 33 34 // 只要找到一个目录就递归的递归的调用自己 35 36 private void ExploreDirectory(DirectoryInfo dir) 37 { 38 indentLevel++; // 目录层次++ 39 40 for (int i = 0; i < indentLevel; i++) 41 Console.Write(" "); 42 43 Console.WriteLine("[{0}] {1} [{2}] ", 44 indentLevel, dir.Name, dir.LastAccessTime); 45 46 // 得到dir下的所有子目录存入directories[]中 47 DirectoryInfo[] directories = dir.GetDirectories(); 48 foreach (DirectoryInfo newDir in directories) 49 { 50 dirCounter++; 51 ExploreDirectory(newDir); // 递归调用 52 } 53 indentLevel--; //目录层次-- 54 } 55 } 56 }
结果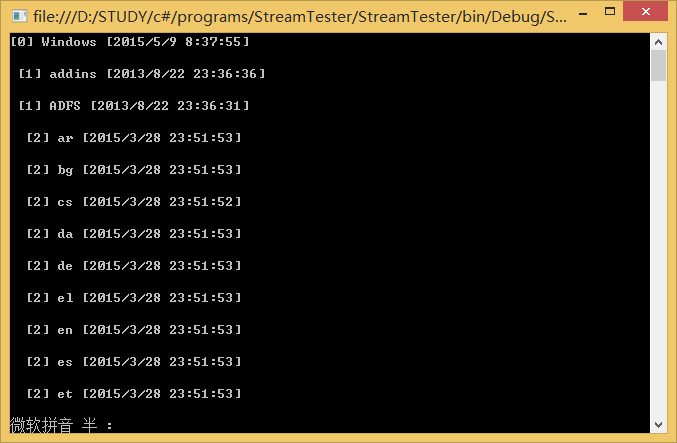

上面结果中,放括号中就是目录的层级。在代码中是通过indentLevel来实现的。
注意,真正使用时,应该使用try,catch。原因是,这里有一个可预测/难以避免的问题:对文件夹的访问权限。不加try运行的话,遇到无法访问的文件夹时,会出现exception停止运行。
2.对文件进行读写操作
1 private void Run() 2 { 3 // 打开文件 4 FileInfo theSourceFile = new FileInfo( 5 @"C:UsersshanyuwangDesktop est.txt"); 6 7 // 创建text reader 8 StreamReader reader = theSourceFile.OpenText(); 9 10 // 创建text writer 11 StreamWriter writer = new StreamWriter( 12 @"C:UsersshanyuwangDesktop est2.txt", false); 13 14 string text; 15 16 // 每次读入一行并写入text,writer 17 do 18 { 19 text = reader.ReadLine(); 20 writer.WriteLine(text); 21 Console.WriteLine(text); 22 } while (text != null); 23 24 // 关闭文件。建议养成的好习惯,避免在后续程序中对文件误操作 25 reader.Close(); 26 writer.Close(); 27 }
结果 test2.txt中内容与test.txt中相同。
同样要注意,reader和writer的路径是否有效
3.读入网页内容
1 public class Client 2 { 3 static public void Main(string[] Args) 4 { 5 // http request请求 6 HttpWebRequest webRequest = 7 (HttpWebRequest)WebRequest.Create 8 ("http://www.baidu.com/"); 9 10 // httq response 11 HttpWebResponse webResponse = 12 (HttpWebResponse)webRequest.GetResponse(); 13 14 // 对response的返回内容读入 15 StreamReader streamReader = new StreamReader( 16 webResponse.GetResponseStream(), Encoding.ASCII); 17 18 try 19 { 20 string outputString; 21 outputString = streamReader.ReadToEnd(); 22 Console.WriteLine(outputString); 23 } 24 catch 25 { 26 Console.WriteLine("Exception reading from web page"); 27 } 28 streamReader.Close(); 29 Console.ReadKey(); 30 } 31 }

可以发现返回的结果是html文件。
注意的还是request的网址是否有效或内否达到(youtube等会有exception)
从上面的例子中可以非常容易地看出,要常注意指向路径是否有效,常用try catch