之前使用PageRank提取关键结点的方法是计算每个结点的PageRank的值,然后提取top10%的结点作为关键结点。但是PageRank是从全局视角给网页排序,从而得到的每个结点的PageRank的值。
这篇文章结合复杂网络的局部特征和全局特征,通过标准化每个节点的度和中间性中心性,利用节点之间的连接强度将它们整合在一起。最后根据计算的SDB的值来表示结点的重要性。SDB值越大,结点在维护连接方面的作用变得更加重要。
文章方法的主要思路就是计算SDB的值
SDB的值的计算公式如下:
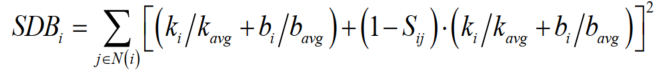
ki表示第i个结点的度,kavg表示结点度的平均数;bi表示第i个结点的介中心性,bavg表示结点的平均介中心性;Sij表示连接强度
其中ki(di)的计算如下:
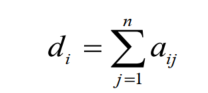
bi的计算:
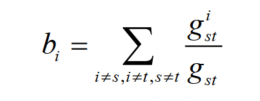
Sij的计算如下:
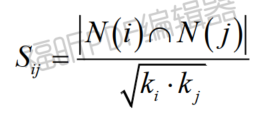
N(i)和N(j)分别表示结点i和j的邻居数,ki和kj分别表示结点i和j的度.Sij=0表示结点i和j没有公共邻居,Sij=1表示结点i和j的邻居完全相同。
实验部分的话就是主要选取几个指标进行对比的过程。下面给出复现代码:
import math import pandas as pd import utils.generate_network as gennet import networkx as nx import numpy as np import os # 1.根据图文件生成graph def gen_network(file_name): """ 根据图结点文件生成图 :param file_name: :return: """ G = gennet.gen_network(file_name) return G # 2. 计算每个结点的度ki 和所有节点的平均度 kavg def compute_degree(G): """ 计算给定图中每个结点的度和平均度 :param G: :return: """ degree_list = nx.degree(G) degree_val = [gd[1] for gd in list(degree_list)] avg_degree = np.average(degree_val) degree_dict = {} for dl in degree_list: degree_dict[dl[0]] = dl[1] return degree_dict, avg_degree # 3. 计算每个结点的介中心性 betweenness bi 和平均值 bavg def compute_betweenness(G): """ 计算给定图中每个结点的介中心性 :param G: :return: """ # 介中心性 betweenness = nx.betweenness_centrality(G, normalized=False) # 平均介中心性 avg_betweenness = np.average(list(betweenness.values())) return betweenness, avg_betweenness # 4. 计算结点i,j 的连接强度 sij def compute_connectivity(G, degree_dict): """ 计算结点间的连接强度 :param G: 图 networkx :param degree_dict: 结点度 {nodei: ki} sij = |N(i) ∩ N(j)| / √(ki * kj) :return: """ nodes_list = list(G.nodes) node_num = len(nodes_list) # 每个结点与其他结点对应的连接性 connectivity = {} for i in range(0, node_num): neighbor_i = list(G.neighbors(nodes_list[i])) ki = degree_dict.get(nodes_list[i]) conn_i = {} for j in range(0, node_num): neighbor_ni = list(G.neighbors(nodes_list[j])) k_ni = degree_dict.get(nodes_list[j]) # 邻居结点交集 intersection = [ni for ni in neighbor_i if ni in neighbor_ni] # 求sij sij = len(intersection) / math.sqrt(ki * k_ni) conn_i[nodes_list[j]] = sij connectivity[nodes_list[i]] = conn_i return connectivity # 5. 计算SDB = sum(((ki/kavg + b/ bavg) + (1-sij) * (ki/kavg + b/ bavg)平方) j∈Neighbor(i) def compute_sdb(G, out_path): """ 计算SDB :param G: 图 networkx :param out_path: 计算结果输出文件 :return: """ # 计算度 degree_dict, avg_degree = compute_degree(G) # 计算介中心性 betweenness_dict, avg_betweenness = compute_betweenness(G) # 计算连接强度 connectivity_dict = compute_connectivity(G, degree_dict) node_list = list(G.nodes) SDB = [] for node in node_list: ki = degree_dict.get(node) bi = betweenness_dict.get(node) connectivity = connectivity_dict.get(node) node_neighbor = list(G.neighbors(node)) SDBi = 0 for nn in node_neighbor: tmp = (ki / avg_degree + bi / avg_betweenness) sij = connectivity.get(nn) curr_sbd = math.pow(tmp + (1 - sij) * tmp, 2) SDBi += curr_sbd SDB.append(SDBi) sdb_value = pd.DataFrame(columns=["Node", "SDB"]) sdb_value["Node"] = node_list sdb_value["SDB"] = SDB # 按照SDB排序 sdb_value.sort_values(by="SDB", inplace=True, ascending=False) # sdb_value.to_csv(out_path, index=False, encoding="utf8") return sdb_value def get_top_10_percent(sdb_file, out_file): """ 获取sdb值最大的前10%的结点list :param out_file: :param sdb_file: :return: """ sdb_data = pd.read_csv(sdb_file) data_num = sdb_data.shape[0] top_10_percent_num = int(data_num * 0.1) top_10_percent_data = sdb_data.head(top_10_percent_num) # top_10_percent_node = top_10_percent_data["node"].values.tolist() top_10_percent_data.to_csv(out_file, index=False, encoding="utf8")