解决数据库级(SQL)工作上的问题,应该采用的是SET方法(整体的)而不是过程式的方法。下面来看看作者为什么这么说。
编写有效的SQL查询是企业软件世界中最大的难题之一。
每个公司在数据库开发项目中所面临的最根本的问题,在于开发环境中实现的性能不能在生产环境中实现。一般来说,存在性能损失是因为生产环境中的数据量要大得多。
这些问题(运行缓慢的数据库操作)可能有各种各样的原因。本文将解释如何在编写查询时进行思考,如何思考是最基本的问题,也是解决此类问题的起点。
观察发现SQL开发人员常使用过程方法编写查询。事实上,这是很自然的,因为用程序方法解决问题是最方便的人类逻辑解决方案。另一个方面,几乎所有的SQL开发人员都在同时编写Java、c#或其他编程语言的代码。Java、C#等可以用来训练开发人员以一种程序化的方式来培养他们的思维方式,因为当使用这些语言开发应用程序时,会使用很多类似的东西,比如IF .. THEN .. ELSE,FOR .. LOOP,WHILE .. DO, CASE .. WHEN。当然,在这种情况下,当将业务规则应用到一组数据时,意味着每个记录都是单独处理的(逐行处理)。这个过程方法在Java、c#等语言中使用。虽然使用语言开发软件是一种正确的方法,但在编写数据库级(SQL)的查询时,却不会产生同样的效果。
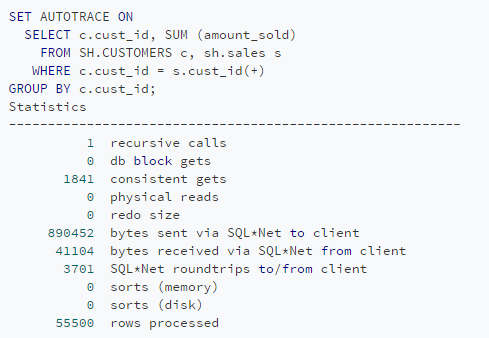
下面用两种不同的方法来解决同一个示例问题,并将结果进行比较。看看CUSTOMERS表中对应的每个客户在SALES表中有多少条记录。
过程式方法如下:

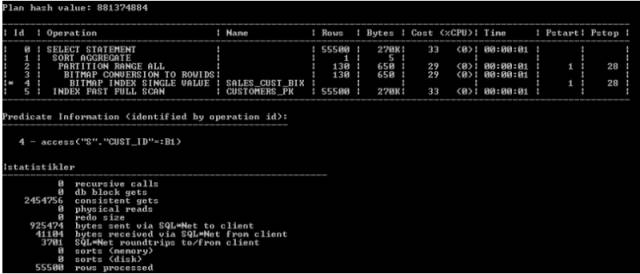
现在,采用基于SET的方法来编写查询。
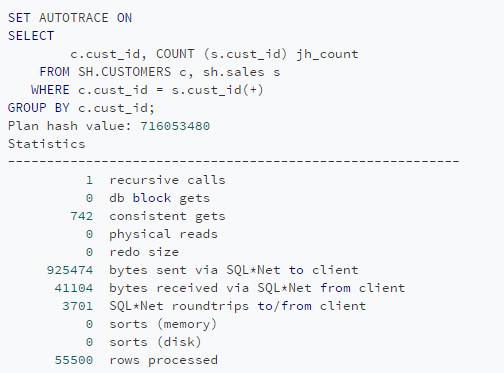
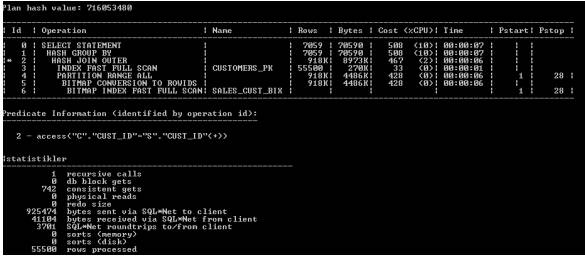
可以看到在两个查询的consistent gets数量之间的差异(当检查缓冲区缓存读到的块数据时)是巨大的。使用两种不同方法编写的查询在运行时导致不同时间。这种差别可以用性能来解释。
在另一个例子中,常见的习惯是在SQL语句中调用PL/SQL函数。作为过程式工作的例子,也是一种解决问题的方法。还有其他一些影响在SQL内调用PL/SQL代码性能的不利因素,但在本文中,不会提到性能问题。
下面编写查找客户表中每个客户的购买金额的代码。
过程方法:
在第一步中,创建一个PL/SQL函数来计算每个客户的总数,然后在代码和输出中调用这个函数。
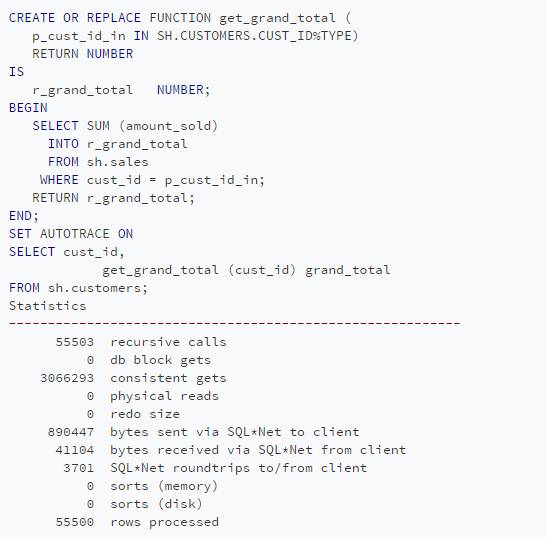
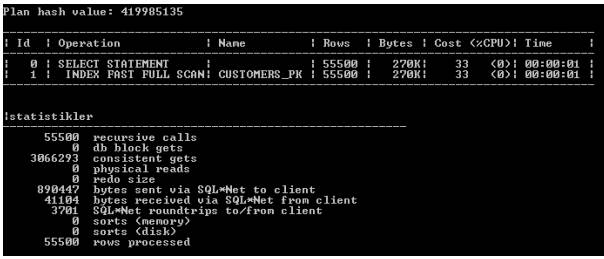
现在,采用基于SET的方法来编写查询。
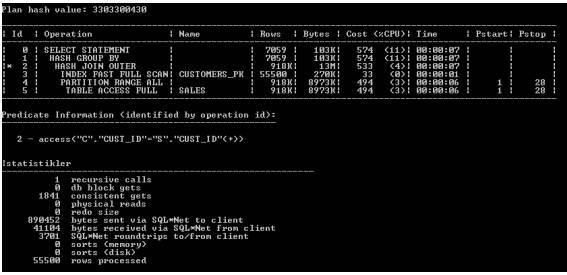
在本例中,通过查看consistent GETS和递归调用输出,我们可以看到相同的情况。
我们的查询也是生成更高效的数据库操作的第一步,它考虑的是批处理,而不是逐行思考。在进行数据库操作时,批处理的方法会让你在一天结束时消耗更少的资源,从而提高工作效率。