上个星期天晚上约11点半,左耳朵耗子在新浪微博上吐槽QQ安全中心密码修改的问题,引来不少围观。QQ安全中心的兄弟收到用户反馈后,第一时间fix bug并发布,其高效着实令人佩服。

当时也围观了下,问题并不复杂,是由于业务代码对于url的不恰当处理导致的(详见本文第3点),涉及url fragment(#)的内容,于是顺便重温了下这块的内容。
文章主要参考了httpwatch博客的一篇文章:《6 Things You Should Know About Fragment URLs》
其中1-5点的内容比较基础,6-7点的内容对于ajax应用的开发有不错的指导意义,可以了解下。
1、#右边的字符,代表了一个页面的特定位置
比如下面的url
http://www.example.com/index.html#casper
浏览器会寻找页面里面,name属性跟casper匹配的a标签,并自动滚动定位到该位置,如下
<a name="casper">页面会自动滚动到这个标签所在的位置</a>
2、HTTP请求里,不会带上#后面的部分
在地址栏里输入http://www.cnblogs.com/#casper,打开调试工具查看网络请求,会发现#casper并没有出现再网络请求中,如图所示

3、#后面的所有字符,都会被浏览当作位置标识符
关于这点,不少新手,包括老手,一不小心就掉坑里了。举个最新的例子,前不就做耳朵耗子在微博上吐槽腾讯安全中心密码修改的问题,如图 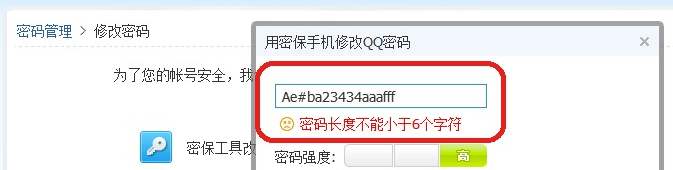
果断测试并抓了下包,一下就发现问题了:#后面的字符被截断了,于是便得到了错误的校验提示
https://aq.qq.com/cn2/ajax/get_psw_sgn?psw=Ae#ba234aaafff
4、改变#不会导致页面重新加载,但是会改变浏览器历史记录
关于这点很容易测试,假设当前访问的页面是http://www.qq.com,打开控制台,分别输入如下命令看下区别(是否刷新),然后,再查看window.history有什么区别(历史记录是否变化)
location.href += '#caper'; //页面不会刷新
location.href += '?visitor=caper'; //页面刷新
在普通的网页浏览中,我们每点击一个网页链接,就会在浏览器历史记录中新增一条浏览记录,并通过浏览器的导航功能轻松进行'上一步'、'下一步'的操作。
但对于ajax应用,url通常是不会变化的,尤其是单页面应用。这也就意味着,用户习以为常的浏览器导航功能(上一步、下一步)失去了作用,这在体验上是比较糟糕的。通过#,开发者可以利用不同的id,标识当前页面所处状态,提升用户体验。
5、JS中可以通过window.location.hash来读取或改变#的值
没什么好讲的,可结上一点简单测试下 :)
6、谷歌的网络蜘蛛默认会忽略#后面的内容
谷歌网络蜘蛛负责爬取网页的内容,以及网页里面的链接,它们会成为google搜索索引的一部分。网络蜘蛛会抓取并分析HTML,但由于它并不是浏览器程序,也没有javascript引擎,页面上用来加载显示内容的javascript并不会被执行。因此,#后面的字符会被网络蜘蛛忽视,只抓取#前面的内容,举例:
链接一:http://www.cnblogs.com/#casper
链接二:http://www.cnblogs.com/#chyingp
对于网络蜘蛛来说,链接一、链接二其实是一样的,它只会抓取http://www.cnblogs.com的内容,尽管两个链接可能展示的是不同的内容
这点无论对于开发者,还是搜索引擎都是不利的,前者辛苦创作的内容(应用)少了很多被访问的机会,而后者则失去了进一步丰富其内容索引的机会,特别是在ajax应用越来越多的今天。
为了解决这个问题,google提供了一个解决方案:hash bang,只要将#改成#!即可,实现大致为:当网络蜘蛛遇到#!时候,会自动将#!identifier转成_escaped_fragment_=identifier形式的参数,修改下之前的链接
链接一(新):http://www.cnblogs.com/#!casper
链接二(新):http://www.cnblogs.com/#!chyingp
在网络蜘蛛眼里,上面的链接是这样的
链接一(转化后):http://www.cnblogs.com/?_escaped_fragment_=casper
链接二(转化后):http://www.cnblogs.com/?_escaped_fragment_=chyingp
这里有两个注意点:
- 将#改成!#告诉网络蜘蛛:我们支持这个解决方案:hash bang
- 相应的,我们的应用也需要具备相应的支持能力,对于网络蜘蛛带escaped_fragment=casper的GET请求,需要能够提供相应的网页内容
更多内容,请参考:http://support.google.com/webmasters/bin/answer.py?hl=en&answer=174992
7、补充内容:hash bang的应用(注意这里的例子有些误导)
看了网上不少这方面的内容,都是以twitter为例子,但由于中国的特殊国情,访问twitter略麻烦,于是举个离我们比较近的例子:QQ空间。
应该很多人都有在用QQ空间,打开QQ空间,并点击“日志”,观察下当前的url
http://user.qzone.qq.com/替换成自己的QQ号码/infocenter#!app=2&via=QZ.HashRefresh&pos=catalog_list
可以发现,infocenter后面用的是#!,按照之前的讲解,我们稍稍做下修改,回车访问,证实我们的猜想。
http://user.qzone.qq.com/替换成自己的QQ号码/infocenter?_escaped_fragment_=app=2&via=QZ.HashRefresh&pos=catalog_list
2013/04/02添加
重新测试了下,空间目前不支持_escaped_fragment_,因此即使加了这个参数,也是会定位到个人中心
1、空间加#!的原因 1)缓存考虑 2)为可能的索引优化做准备
2、没支持_escaped_fragment_的原因:
非技术实现上的困难,因为目前的产品性质对于这块优化的需求不大
这块的例子,据说twitter是做了的,但得FQ才能测试,先TODO一下。