此次博客记录来源于一次项目,需要往es写入百亿条数据,环境采用【程序->kafka->logstash->es】的流程,搭建好之后发现写入效率非常低,2000条/s,算下来写够一百亿需要将近两个月然后就有了本次优化记录。最终优化结果可以达到36000/s且稳定,3天就可以结束。
服务配置:
|
Ip |
192.168.210.111 |
192.168.210.112 |
192.168.210.113 |
|
Es集群 |
Es7.4 |
Es7.4 |
Es7.4 |
|
Logstash集群 |
Logstash7.4 |
Logstash7.4 |
Logstash7.4 |
|
内存 |
80G |
80G |
80G |
|
CPU |
5 |
5 |
5 |
内存配置:
全默认配置
数据格式:
13369998888,15666665478,2020-12-30 03:03:45,中国
Logstash配置:
Input:
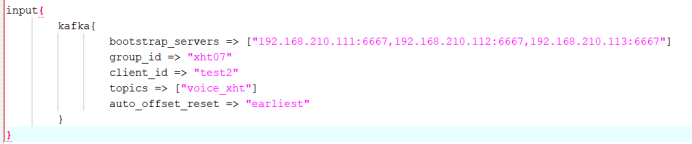
Filter:
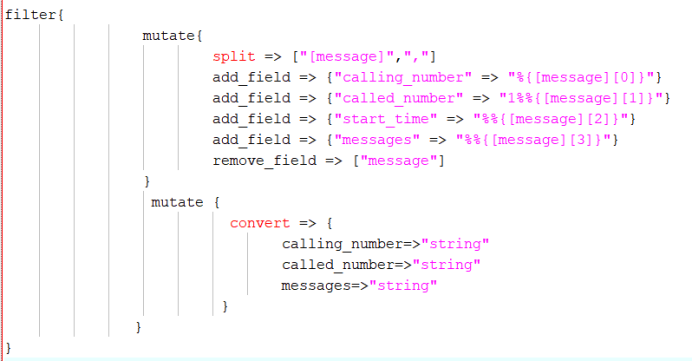
Output:

优化项:
内存优化:
|
|
Logstash |
ES |
|
jvm.options |
(1G)->(16G) |
(1G)->(16G) |
效果:
写入效率2000条/s上升到5000条/s(一个logstash)
第二次优化项:
三个logstash并行写入。
内存优化:
|
|
Logstash |
ES |
|
jvm.options |
(1G)->(16G) |
(16G)->(31G) |
效果:
效果不明显。
推测瓶颈在logstash
第三次优化项:
三个logstash并行写入。
Logstash优化:
Input:
generator (无中生有)

Filter:
ruby 随机生成手机号、时间
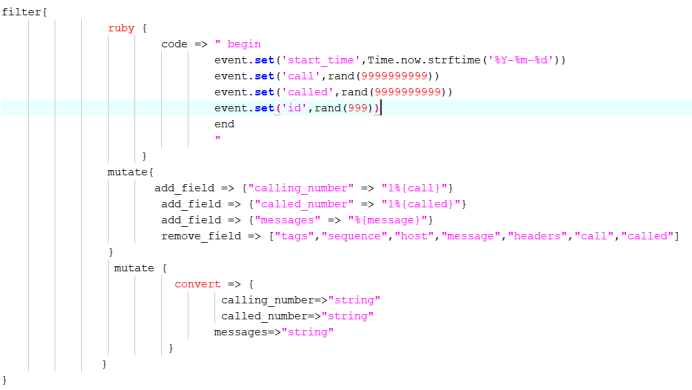
Output:

Logstash.yml:
pipeline.batch.size: 30000 每批次写入数据量 (越多越好,高效利用内存空间)
pipeline.batch.delay: 2 每批次间隔时间(越短越好,高效利用CPU)
pipeline.workers: 5 工作核数(不超过CPU核数)
效果:
写入效率5000条/s上升到8000条/s
推测瓶颈在es write线程
第四次优化项:
三个logstash并行写入。
Es配置优化:
elasticsearch.yml:
thread_pool.write.size: 6 线程数(不超过CPU核数)
thread_pool.write.queue_size: 500 队列大小(越大吞吐量越大,但处理的就越慢)
效果:
效果不明显,并且在这时出现了es写入速度跟不上logstash生产速度而产生的异常信息。
retrying failedaction with response code:429
以及
Attempted tosend a bulk request to elasticsearch' but Elasticsearch appears to beunreachable or down!
推测瓶颈可能在磁盘IO
第五次优化项:
三个logstash并行写入。
Es索引参数优化:
分片数:
number_of_shards 主分片数
number_of_replicas 副本分片数
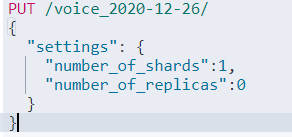
刷新频率:
refresh_interval 索引刷新时间间隔(越短越消耗资源)
1m为1分钟。
刷新时会产生一个新的段,每一个段都会消耗文件句柄、内存和cpu运行周期
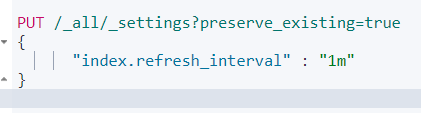
可以将 refresh_interval 设置为 -1 以加快导入速度。导入结束后,再将 refresh_interval 设置为一个正数
异步刷盘:
durability:async 异步
flush_threshold_size 当translog的大小达到此值时会进行一次flush操作。默认是512mb
sync_interval 控制数据从内存到硬盘的操作频率,以减少硬盘IO,默认5s
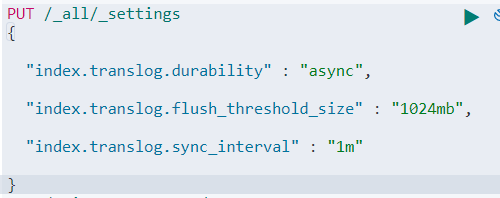
效果:
写入效率8000条/s上升到15000条/s
第六次优化项:
三个logstash并行写入。
Logstash脚本优化:
Output:

使用Es自动生成的id,写入时不会每次去判断这个ID是否存在。
效果:
写入效率15000条/s上升到20000条/s
第七次优化项:
三个logstash并行写入。
Es索引参数优化:
分片数:
number_of_shards 主分片数
number_of_replicas 副本分片数
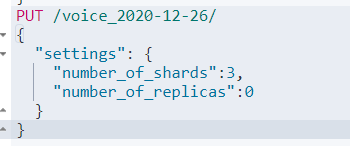
主分片数=集群节点数效果最佳
需要注意的是:这个配置不支持动态修改,只能在创建索引的时候指定。
效果:
写入效率20000条/s上升到36000条/s
为了方便监控:可以使用kibana的xpack.
开启方式:
Logstash:logstash.yml
xpack.monitoring.enabled: true
xpack.monitoring.elasticsearch.hosts: ["http://ambari01:9200", "http://ambari02:9200","http://ambari03:9200"]
Es:elasticsearch.yml
xpack.monitoring.collection.enabled: true