本次使用POI处理xlsx文件,莫名的遇到了一个无法逾越的问题。
总共71个xlsx文件,单个文件最大达到50M以上,71个xls文件摆在那里就有3-4G的大小。
在起始处理的时候,发现原本适用于正常大小的POI处理xls程序竟然屡次的报错GC outofmemory 的内存移除的问题。
【当前状况】
①一个50M大小的xlsx文件,使用压缩文件打开,可以看到xml文件达到900M以上
②一个50M大小以上的xlsx文件,单个工作簿,行数平均在15W行---40W之间,列数在64列左右
③单方面的调整了JVM运行的 堆内存大小,调整到了4G并没有什么效果
④程序运行起来之后,XSSFWorkbook workbook1 = new XSSFWorkbook(fileInputStream); 跑起来,CPU瞬间99%满负荷,内存最高可以使用9.79G的占用率,仅这一个xlsx文件
【官方解决方法】
网上关于POI处理超大文件的资料不很多,粘贴,水贴更是多如牛毛。POI官网,有一个SXSSF的XSSF扩展API插件,话说是可以【生成/处理】【有歧义】大型电子表格。

但是,仅仅是支持生成而已。
如果用于操作大型xlsx文件,API中给出的构造方法,还是需要先构造XSSFWorkbook对象。

在上一步就会卡死导致内存溢出,根本走不到下步。

最后,还是找到了一篇有用的信息,关于官方的解决思路,就是将xlsx文件转化为CVS文件进行相应的处理,这样不用占用太大的内存空间,导致内存溢出程序崩溃。
一下是官方提供的XLS转化为CVS的代码,注解做了部分翻译。留下之后有时间再进行研究。


1 package com.poi.dealXlsx; 2 3 import org.apache.poi.openxml4j.exceptions.OpenXML4JException; 4 5 /* ==================================================================== 6 Licensed to the Apache Software Foundation (ASF) under one or more 7 contributor license agreements. See the NOTICE file distributed with 8 this work for additional information regarding copyright ownership. 9 The ASF licenses this file to You under the Apache License, Version 2.0 10 (the "License"); you may not use this file except in compliance with 11 the License. You may obtain a copy of the License at 12 13 http://www.apache.org/licenses/LICENSE-2.0 14 15 Unless required by applicable law or agreed to in writing, software 16 distributed under the License is distributed on an "AS IS" BASIS, 17 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 18 See the License for the specific language governing permissions and 19 limitations under the License. 20 ==================================================================== */ 21 22 23 import java.io.File; 24 import java.io.IOException; 25 import java.io.InputStream; 26 import java.io.PrintStream; 27 28 import javax.xml.parsers.ParserConfigurationException; 29 30 import org.apache.poi.openxml4j.opc.OPCPackage; 31 import org.apache.poi.openxml4j.opc.PackageAccess; 32 import org.apache.poi.ss.usermodel.DataFormatter; 33 import org.apache.poi.ss.util.CellAddress; 34 import org.apache.poi.ss.util.CellReference; 35 import org.apache.poi.util.SAXHelper; 36 import org.apache.poi.xssf.eventusermodel.ReadOnlySharedStringsTable; 37 import org.apache.poi.xssf.eventusermodel.XSSFReader; 38 import org.apache.poi.xssf.eventusermodel.XSSFSheetXMLHandler; 39 import org.apache.poi.xssf.eventusermodel.XSSFSheetXMLHandler.SheetContentsHandler; 40 import org.apache.poi.xssf.extractor.XSSFEventBasedExcelExtractor; 41 import org.apache.poi.xssf.model.StylesTable; 42 import org.apache.poi.xssf.usermodel.XSSFComment; 43 import org.xml.sax.ContentHandler; 44 import org.xml.sax.InputSource; 45 import org.xml.sax.SAXException; 46 import org.xml.sax.XMLReader; 47 48 /** 49 *一个基本的XLSX - > CSV处理器 50 * POI样本程序XLS2CSVmra从包中 51 * org.apache.poi.hssf.eventusermodel.examples。 52 *与HSSF版本一样,这会试图找到错误 53 *行和单元格,并为它们输出空条目。 54 * <p /> 55 *使用SAX解析器读取数据表以保持 56 *内存占用比较小,所以这应该是 57 *能够阅读庞大的工作簿。样式表和 58 *共享字符串表必须保存在内存中。该 59 *标准POI样式表类使用,但是一个自定义 60 *(只读)类用于共享字符串表 61 *因为标准的POI SharedStringsTable增长很大 62 *快速与唯一字符串的数量。 63 * <p /> 64 *更高级的SAX事件解析实现 65 *的XLSX文件,请参阅{@link XSSFEventBasedExcelExtractor} 66 *和{@link XSSFSheetXMLHandler}。请注意,在很多情况下, 67 *可以简单地使用那些与习惯 68 * {@link SheetContentsHandler}并且不需要SAX代码 69 * 你自己! 70 */ 71 public class XLSX2CSV { 72 /** 73 *使用XSSF Event SAX助手进行大部分工作 74 *解析Sheet XML,并输出内容 75 *作为(基本)CSV。 76 */ 77 private class SheetToCSV implements SheetContentsHandler { 78 private boolean firstCellOfRow = false; 79 private int currentRow = -1; 80 private int currentCol = -1; 81 82 /** 83 * 输出缺失的行 84 * @param number 85 */ 86 private void outputMissingRows(int number) { 87 for (int i = 0; i < number; i++) { 88 for (int j = 0; j < minColumns; j++) { 89 output.append(','); 90 } 91 output.append(' '); 92 } 93 } 94 95 @Override 96 public void startRow(int rowNum) { 97 // If there were gaps, output the missing rows 98 outputMissingRows(rowNum - currentRow - 1); 99 // Prepare for this row 100 firstCellOfRow = true; 101 currentRow = rowNum; 102 currentCol = -1; 103 } 104 105 @Override 106 public void endRow(int rowNum) { 107 // Ensure the minimum number of columns 108 for (int i = currentCol; i < minColumns; i++) { 109 output.append(','); 110 } 111 output.append(' '); 112 } 113 114 @Override 115 public void cell(String cellReference, String formattedValue,XSSFComment comment) { 116 if (firstCellOfRow) { 117 firstCellOfRow = false; 118 } else { 119 output.append(','); 120 } 121 122 // gracefully handle missing CellRef here in a similar way as XSSFCell does 123 if (cellReference == null) { 124 cellReference = new CellAddress(currentRow, currentCol).formatAsString(); 125 } 126 127 // Did we miss any cells? 128 int thisCol = (new CellReference(cellReference)).getCol(); 129 int missedCols = thisCol - currentCol - 1; 130 for (int i = 0; i < missedCols; i++) { 131 output.append(','); 132 } 133 currentCol = thisCol; 134 135 // Number or string? 136 try { 137 Double.parseDouble(formattedValue); 138 output.append(formattedValue); 139 } catch (NumberFormatException e) { 140 output.append('"'); 141 output.append(formattedValue); 142 output.append('"'); 143 } 144 } 145 146 @Override 147 public void headerFooter(String text, boolean isHeader, String tagName) { 148 // Skip, no headers or footers in CSV 149 } 150 } 151 152 153 154 /** 155 * 表示可以存储多个数据对象的容器。 156 */ 157 private final OPCPackage xlsxPackage; 158 159 /** 160 * 以最左边开始读取的列数 161 */ 162 private final int minColumns; 163 164 /** 165 * 写出数据流 166 */ 167 private final PrintStream output; 168 169 /** 170 * 创建一个新的XLSX -> CSV转换器 171 * 172 * @param pkg The XLSX package to process 173 * @param output The PrintStream to output the CSV to 174 * @param minColumns 要输出的最小列数,或-1表示最小值 175 */ 176 public XLSX2CSV(OPCPackage pkg, PrintStream output, int minColumns) { 177 this.xlsxPackage = pkg; 178 this.output = output; 179 this.minColumns = minColumns; 180 } 181 182 /** 183 * Parses and shows the content of one sheet 184 * using the specified styles and shared-strings tables. 185 *解析并显示一个工作簿的内容 186 *使用指定的样式和共享字符串表。 187 * @param styles 工作簿中所有工作表共享的样式表。 188 * @param strings 这是处理共享字符串表的轻量级方式。 大多数文本单元格将引用这里的内容。请注意,如果字符串由不同格式的位组成,则每个SI条目都可以有多个T元素 189 * @param sheetInputStream 190 */ 191 public void processSheet(StylesTable styles, 192 ReadOnlySharedStringsTable strings, 193 SheetContentsHandler sheetHandler, InputStream sheetInputStream) 194 throws IOException, ParserConfigurationException, SAXException { 195 DataFormatter formatter = new DataFormatter(); 196 InputSource sheetSource = new InputSource(sheetInputStream); 197 try { 198 XMLReader sheetParser = SAXHelper.newXMLReader(); 199 ContentHandler handler = new XSSFSheetXMLHandler(styles, null, 200 strings, sheetHandler, formatter, false); 201 sheetParser.setContentHandler(handler); 202 sheetParser.parse(sheetSource); 203 } catch (ParserConfigurationException e) { 204 throw new RuntimeException("SAX parser appears to be broken - " 205 + e.getMessage()); 206 } 207 } 208 209 /** 210 * Initiates the processing of the XLS workbook file to CSV. 211 * 启动将XLS工作簿文件处理为CSV。 212 * 213 * @throws IOException 214 * @throws OpenXML4JException 215 * @throws ParserConfigurationException 216 * @throws SAXException 217 */ 218 public void process() 219 throws IOException, OpenXML4JException, ParserConfigurationException, SAXException { 220 ReadOnlySharedStringsTable strings = new ReadOnlySharedStringsTable(this.xlsxPackage); 221 XSSFReader xssfReader = new XSSFReader(this.xlsxPackage); 222 StylesTable styles = xssfReader.getStylesTable(); 223 XSSFReader.SheetIterator iter = (XSSFReader.SheetIterator) xssfReader.getSheetsData(); 224 int index = 0; 225 while (iter.hasNext()) { 226 InputStream stream = iter.next(); 227 String sheetName = iter.getSheetName(); 228 this.output.println(); 229 this.output.println(sheetName + " [index=" + index + "]:"); 230 processSheet(styles, strings, new SheetToCSV(), stream); 231 stream.close(); 232 ++index; 233 } 234 } 235 236 public static void main(String[] args) throws Exception { 237 /* if (args.length < 1) { 238 System.err.println("Use:"); 239 System.err.println(" XLSX2CSV <xlsx file> [min columns]"); 240 return; 241 }*/ 242 243 File xlsxFile = new File("D:/基因数据测试/S1.xlsx"); 244 if (!xlsxFile.exists()) { 245 System.err.println("没找到文件: " + xlsxFile.getPath()); 246 return; 247 } 248 249 int minColumns = -1; 250 if (args.length >= 2) 251 minColumns = Integer.parseInt(args[1]); 252 253 // The package open is instantaneous, as it should be. 254 OPCPackage p = OPCPackage.open(xlsxFile.getPath(), PackageAccess.READ); 255 XLSX2CSV xlsx2csv = new XLSX2CSV(p, System.out, minColumns); 256 xlsx2csv.process(); 257 p.close(); 258 } 259 }
----------------------------------------------------------------------------------【待续1】------------------------------------------------------------------------------------------
上回书说道,官方提供的XLS转化为CVS代码,其实就是使用org.xml.sax.XMLReader使用SAX解析器去解析了xls底层的xml文件而已。并没有真正的转化为CVS文件。
【XMLReader就是JDK自带的方法,查阅API可以查看相关实现类和相关工具类的方法和使用】
对于上段代码的研读,贴出来:
1 package com.poi.dealXlsx; 2 3 import org.apache.poi.openxml4j.exceptions.OpenXML4JException; 4 import java.io.File; 5 import java.io.IOException; 6 import java.io.InputStream; 7 import java.io.PrintStream; 8 9 10 import javax.xml.parsers.ParserConfigurationException; 11 12 13 import org.apache.poi.openxml4j.opc.OPCPackage; 14 import org.apache.poi.openxml4j.opc.PackageAccess; 15 import org.apache.poi.ss.usermodel.DataFormatter; 16 import org.apache.poi.ss.util.CellAddress; 17 import org.apache.poi.ss.util.CellReference; 18 import org.apache.poi.util.SAXHelper; 19 import org.apache.poi.xssf.eventusermodel.ReadOnlySharedStringsTable; 20 import org.apache.poi.xssf.eventusermodel.XSSFReader; 21 import org.apache.poi.xssf.eventusermodel.XSSFSheetXMLHandler; 22 import org.apache.poi.xssf.eventusermodel.XSSFSheetXMLHandler.SheetContentsHandler; 23 import org.apache.poi.xssf.model.StylesTable; 24 import org.apache.poi.xssf.usermodel.XSSFComment; 25 import org.xml.sax.ContentHandler; 26 import org.xml.sax.InputSource; 27 import org.xml.sax.SAXException; 28 import org.xml.sax.XMLReader; 29 30 /** 31 * 一个基本的XLSX - > CSV处理器 POI样本程序XLS2CSVmra从包中 32 * 实际上是将xlsx文件从传统的POI解析 转变为将xlsx底层的xml文件交给SAX解析器去解析 33 * 以便处理超大xlsx文件,从而占用更小的内存和CPU资源 34 */ 35 public class XLSX2CSV { 36 37 /** 38 * XSSFSheetXMLHandler处理器,用来处理xlsx文件底层xml文件的sheet部分 39 */ 40 private class SheetToCSV implements SheetContentsHandler { 41 private boolean firstCellOfRow = false; 42 private int currentRow = -1; 43 private int currentCol = -1; 44 45 /** 46 * 输出缺失的行 47 * @param number 48 */ 49 private void outputMissingRows(int number) { 50 for (int i = 0; i < number; i++) { 51 for (int j = 0; j < minColumns; j++) { 52 output.append(','); 53 } 54 output.println("缺失一行"); 55 } 56 } 57 58 //重新开始一行 59 @Override 60 public void startRow(int rowNum) { 61 outputMissingRows(rowNum - currentRow - 1); 62 firstCellOfRow = true; 63 currentRow = rowNum; 64 currentCol = -1; 65 } 66 67 @Override 68 public void endRow(int rowNum) { 69 //确保最小的列数 70 for (int i = currentCol; i < minColumns; i++) { 71 output.println(rowNum+"行结束"); 72 } 73 output.println("下标:"+rowNum+"行结束"); 74 } 75 76 @Override 77 public void cell(String cellReference, String formattedValue,XSSFComment comment) { 78 // 以下处理了单元格为Null的情况 79 //通过【A1】等判断是是【第一行第1列】 80 int thisCol = (new CellReference(cellReference)).getCol(); 81 int missedCols = thisCol - currentCol - 1; 82 for (int i = 0; i < missedCols; i++) { 83 output.println("单元格值为空"); 84 } 85 currentCol = thisCol; 86 if (firstCellOfRow) { 87 firstCellOfRow = false; 88 output.println(currentRow+"行的第一个单元格"); 89 } 90 91 92 //cellReference代表单元格的横纵坐标 93 if (cellReference == null) { 94 cellReference = new CellAddress(currentRow, currentCol).formatAsString(); 95 } 96 97 output.println("行"+currentRow+"+列"+currentCol+">>值:"+formattedValue); 98 } 99 100 @Override 101 public void headerFooter(String text, boolean isHeader, String tagName) { 102 // CSV文件中没有页眉页脚 103 } 104 } 105 106 107 /** 108 * 表示可以存储多个数据对象的容器。 109 */ 110 private final OPCPackage xlsxPackage; 111 112 /** 113 * 以最左边开始读取的列数 114 */ 115 private final int minColumns; 116 117 /** 118 * 写出数据流 119 */ 120 private final PrintStream output; 121 122 /** 123 * 创建一个新的XLSX -> CSV转换器 124 * 125 * @param pkg The XLSX package to process 126 * @param output The PrintStream to output the CSV to 127 * @param minColumns 要输出的最小列数,或-1表示最小值 128 */ 129 public XLSX2CSV(OPCPackage pkg, PrintStream output, int minColumns) { 130 this.xlsxPackage = pkg; 131 this.output = output; 132 this.minColumns = minColumns; 133 } 134 135 /** 136 *解析并显示一个工作簿的内容 137 * @param styles 工作簿中所有工作表共享的样式表。 138 * @param readOnlyTableString 这是处理共享字符串表的轻量级方式。 大多数文本单元格将引用这里的内容。请注意,如果字符串由不同格式的位组成,则每个SI条目都可以有多个T元素 139 * @param sheetInputStream 以sheet为单位的输入流 140 */ 141 public void processSheet(StylesTable styles,ReadOnlySharedStringsTable readOnlyTableString,SheetContentsHandler sheetHandler, InputStream sheetInputStream) 142 throws IOException, ParserConfigurationException, SAXException { 143 144 DataFormatter formatter = new DataFormatter(); 145 InputSource sheetSource = new InputSource(sheetInputStream); 146 try { 147 //为了尽可能的节省内存和I/0消耗,XmlReader读取Xml需要通过Read()实例方法,不断读取Xml文档中的声明,节点开始,节点内容,节点结束,以及空白等等,直到文档结束,Read()方法返回false 148 XMLReader reader = SAXHelper.newXMLReader(); 149 //XSSFSheetXMLHandler处理器,用来处理xlsx文件底层xml文件的sheet部分,用于生成行和单元格事件 150 ContentHandler handler = new XSSFSheetXMLHandler(styles, null,readOnlyTableString, sheetHandler, formatter, false); 151 //允许应用程序注册内容事件处理程序 152 reader.setContentHandler(handler); 153 //解析XML文件 154 reader.parse(sheetSource); 155 } catch (ParserConfigurationException e) { 156 throw new RuntimeException("SAX解析器坏了"+ e.getMessage()); 157 } 158 } 159 160 /** 161 * Initiates the processing of the XLS workbook file to CSV. 162 * 启动将XLS工作簿文件处理为CSV。 163 * 164 * @throws IOException 165 * @throws OpenXML4JException 166 * @throws ParserConfigurationException 167 * @throws SAXException 168 */ 169 public void process()throws IOException, OpenXML4JException, ParserConfigurationException, SAXException { 170 171 //用于构建XSSFSheetXMLHandler处理器所需要实例化的参数 172 ReadOnlySharedStringsTable readOnlyTableString = new ReadOnlySharedStringsTable(this.xlsxPackage); 173 //XSSFReader获取xlsx文件xml下的各个部分,适用于低内存sax解析或类似。 它构成了对XSSF的EventUserModel支持的核心部分。 174 XSSFReader xssfReader = new XSSFReader(this.xlsxPackage); 175 //工作簿中所有工作表共享的样式表 176 StylesTable styles = xssfReader.getStylesTable(); 177 //从org.apache.poi.xssf.eventusermodel.XSSFReader中获取到Sheet中的数据用来迭代,交给SAX去解析 178 XSSFReader.SheetIterator iter = (XSSFReader.SheetIterator) xssfReader.getSheetsData(); 179 int index = 0; 180 //此处迭代以 sheet为单位,一个工作簿进行一次解析 181 while (iter.hasNext()) { 182 InputStream inputStream = iter.next(); 183 String sheetName = iter.getSheetName(); 184 this.output.println("开始解析》》》》》》》》》》》》》》》》》》》》"); 185 this.output.println("工作簿名称:"+sheetName + " [下标=" + index + "]"); 186 processSheet(styles, readOnlyTableString, new SheetToCSV(), inputStream); 187 inputStream.close(); 188 ++index; 189 } 190 } 191 192 public static void main(String[] args) throws Exception { 193 File xlsxFile = new File("D:/基因数据测试/S1.xlsx"); 194 if (!xlsxFile.exists()) { 195 System.err.println("没找到文件: " + xlsxFile.getPath()); 196 return; 197 } 198 199 int minColumns = -1; 200 201 //打开一个POI容器 参数1 文档路径 参数2 READ READ_WRITE WRITE三种模式 202 OPCPackage p = OPCPackage.open(xlsxFile.getPath(), PackageAccess.READ); 203 204 //自己创建的xls->cvs的转化器 205 XLSX2CSV xlsx2csv = new XLSX2CSV(p, System.out, minColumns); 206 xlsx2csv.process(); 207 //关闭容器 208 p.close(); 209 } 210 }
实际测试的,就是下面的文件:

文件大小51M大小左右

对于上面这段官方提供的方法,我的处理思想是:
将xlsx中的数据读取出来之后,进行每1000行数据一次拆分的做法,将上述较大的xls文件拆分为一个一个的小文件,然后使用 http://www.cnblogs.com/sxdcgaq8080/p/7344787.html
提供的方法迭代去处理文件数据。
明天,将具体的处理代码写出来。
----------------------------------------------------------------------------------【待续2】------------------------------------------------------------------------------------------
处理了将近两天的时间,终于把xlsx超大文件的拆解弄出来了。
1 package com.poi.dealXlsx; 2 3 import org.apache.poi.openxml4j.exceptions.OpenXML4JException; 4 5 import java.io.File; 6 import java.io.FileInputStream; 7 import java.io.FileNotFoundException; 8 import java.io.FileOutputStream; 9 import java.io.IOException; 10 import java.io.InputStream; 11 import java.io.PrintStream; 12 13 14 15 16 17 18 import java.util.ArrayList; 19 import java.util.Arrays; 20 import java.util.Comparator; 21 import java.util.List; 22 23 import javax.xml.parsers.ParserConfigurationException; 24 25 26 27 28 29 30 31 32 33 34 35 36 import org.apache.poi.openxml4j.opc.OPCPackage; 37 import org.apache.poi.openxml4j.opc.PackageAccess; 38 import org.apache.poi.ss.usermodel.Cell; 39 import org.apache.poi.ss.usermodel.DataFormatter; 40 import org.apache.poi.ss.usermodel.Row; 41 import org.apache.poi.ss.usermodel.Sheet; 42 import org.apache.poi.ss.util.CellAddress; 43 import org.apache.poi.ss.util.CellReference; 44 import org.apache.poi.util.SAXHelper; 45 import org.apache.poi.xssf.eventusermodel.ReadOnlySharedStringsTable; 46 import org.apache.poi.xssf.eventusermodel.XSSFReader; 47 import org.apache.poi.xssf.eventusermodel.XSSFSheetXMLHandler; 48 import org.apache.poi.xssf.eventusermodel.XSSFSheetXMLHandler.SheetContentsHandler; 49 import org.apache.poi.xssf.model.StylesTable; 50 import org.apache.poi.xssf.usermodel.XSSFComment; 51 import org.apache.poi.xssf.usermodel.XSSFWorkbook; 52 import org.xml.sax.ContentHandler; 53 import org.xml.sax.InputSource; 54 import org.xml.sax.SAXException; 55 import org.xml.sax.XMLReader; 56 57 /** 58 * 一个基本的XLSX - > CSV处理器 POI样本程序XLS2CSVmra从包中 59 * 实际上是将xlsx文件从传统的POI解析 转变为将xlsx底层的xml文件交给SAX解析器去解析 60 * 以便处理超大xlsx文件,从而占用更小的内存和CPU资源 61 */ 62 public class XLSX2CSV { 63 64 /** 65 * XSSFSheetXMLHandler处理器,用来处理xlsx文件底层xml文件的sheet部分 66 */ 67 private class SheetToCSV implements SheetContentsHandler { 68 private boolean firstCellOfRow = false; 69 private int currentRow = -1; 70 private int currentCol = -1; 71 private List<String> firstRowValue = new ArrayList<String>(); 72 /** 73 * 输出缺失的行 74 * @param number 75 */ 76 private void outputMissingRows(int number) { 77 for (int i = 0; i < number; i++) { 78 for (int j = 0; j < minColumns; j++) { 79 output.append(','); 80 } 81 output.println("缺失一行"); 82 } 83 } 84 85 //重新开始一行 86 @Override 87 public void startRow(int rowNum) { 88 outputMissingRows(rowNum - currentRow - 1); 89 firstCellOfRow = true; 90 currentRow = rowNum; 91 currentCol = -1; 92 } 93 94 @Override 95 public void endRow(int rowNum) { 96 //确保最小的列数 97 for (int i = currentCol; i < minColumns; i++) { 98 output.println(rowNum+"行结束"); 99 } 100 output.println("下标:"+rowNum+"行结束"); 101 } 102 103 104 /** 105 * 逻辑处理的地方 106 */ 107 @Override 108 public void cell(String cellReference, String formattedValue,XSSFComment comment) { 109 110 // 以下处理了单元格为Null的情况 111 //通过【A1】等判断是是【第一行第1列】 112 int thisCol = (new CellReference(cellReference)).getCol(); 113 int missedCols = thisCol - currentCol - 1; 114 for (int i = 0; i < missedCols; i++) { 115 output.println("单元格值为空"); 116 } 117 currentCol = thisCol; 118 if (firstCellOfRow) { 119 firstCellOfRow = false; 120 output.println(currentRow+"行的第一个单元格"); 121 } 122 123 124 //cellReference代表单元格的横纵坐标 125 if (cellReference == null) { 126 cellReference = new CellAddress(currentRow, currentCol).formatAsString(); 127 } 128 //打印出行列中的值 129 // output.println("行"+currentRow+"+列"+currentCol+">>值:"+formattedValue); 130 //单独把第一行 也就是列名 全部存储起来,用于插入每一个拆解开的xls文件中 131 if(currentRow == 0){ 132 //如果是第一行的第一列 说明重新读取了一个新的原始文件 需要重新存储列名 133 if(currentCol == 0){ 134 firstRowValue.clear(); 135 } 136 firstRowValue.add(formattedValue); 137 138 }else{ 139 File file = new File("d:/分解xls"); 140 141 //如果currentRow=0的时候应该重新创建文件夹,代表有开始拆解新的xls文件 142 //否则代表正在拆解当前的xls文件,应该在当前的文件夹中进行 143 if(currentRow == 0){ 144 file = createDir(true,file); 145 }else{ 146 file = createDir(false,file); 147 } 148 //此处按照每1000行拆解为一个xlsx文件,修改1000,即按照自定义的行数拆解为一个xlsx文件 149 //如果行号模1000=0 需要重新创建一个文件 否则就在当前文件中写入数据 150 file = currentRow%1000 == 0 && currentCol == 0 ? getFile(file,true) : getFile(file,false); 151 152 try { 153 FileInputStream fileInputStream = new FileInputStream(file); 154 XSSFWorkbook workbook = new XSSFWorkbook(fileInputStream); 155 Sheet sheet = workbook.getSheetAt(0); 156 int lastRowNum = sheet.getLastRowNum();//当前xlsx中最大行 157 Row row = null; 158 if(lastRowNum == 1 & currentCol ==1){ 159 row = sheet.createRow(0); 160 for (int i = 0; i < firstRowValue.size(); i++) { 161 Cell cell = row.createCell(i); 162 cell.setCellValue(firstRowValue.get(i)); 163 } 164 } 165 if(lastRowNum == 0){ 166 row = currentCol != 0 ? sheet.getRow(1):sheet.createRow(1); 167 }else{ 168 row = currentCol != 0 ? sheet.getRow(lastRowNum):sheet.createRow(lastRowNum+1); 169 } 170 //为本单元格 赋值 171 Cell cell = row.createCell(currentCol); 172 cell.setCellValue(formattedValue); 173 FileOutputStream fileOutputStream = new FileOutputStream(file); 174 workbook.write(fileOutputStream); 175 fileOutputStream.close(); 176 workbook.close(); 177 178 } catch (FileNotFoundException e) { 179 output.println("不能获取到xlsx文件"); 180 } catch (IOException e) { 181 output.println("不是xlsx文件"); 182 } 183 } 184 185 } 186 187 188 @Override 189 public void headerFooter(String text, boolean isHeader, String tagName) { 190 // CSV文件中没有页眉页脚 191 } 192 193 /** 194 * 得到要操作的xlsx文件 195 * @param file 文件目录 196 * @param flag 是否需要重新创建一个新的xlsx 197 * @return 198 */ 199 private File getFile(File file,boolean flag){ 200 File [] fileList = file.listFiles(); 201 Arrays.sort(fileList,new OrderFile()); 202 String newDirName = "1"; 203 if(fileList.length != 0){ 204 if(flag){ 205 try { 206 newDirName = String.valueOf(Integer.parseInt(fileList[fileList.length-1].getName().substring(0, fileList[fileList.length-1].getName().indexOf(".")))+1); 207 } catch (Exception e) { 208 System.out.println("文件名获取失败"); 209 } 210 }else{ 211 return fileList[fileList.length-1]; 212 } 213 214 } 215 String filePath = file.getAbsolutePath()+"/"+newDirName+".xlsx"; 216 XSSFWorkbook workbook = new XSSFWorkbook(); 217 Sheet sheet = workbook.createSheet(newDirName); 218 try { 219 FileOutputStream out = new FileOutputStream(filePath); 220 workbook.write(out); 221 System.out.println("创建xls文件"+newDirName+".xlsx成功"); 222 } catch (FileNotFoundException e) { 223 System.out.println("创建xls失败"); 224 } catch (IOException e) { 225 System.out.println("创建xls失败"); 226 } 227 return new File(filePath); 228 } 229 230 231 /** 232 * 得到当前要操作的目录 233 * @param sign 标志 是否需要新创建一个文件夹 234 * @param file 文件夹路径 235 * @return 236 */ 237 private File createDir(boolean sign,File file){ 238 File [] fileList = file.listFiles(); 239 Arrays.sort(fileList,new OrderFileS()); 240 if(fileList.length == 0){ 241 File thisFile = new File(file.getAbsolutePath()+"/1/"); 242 boolean flag = thisFile.mkdirs(); 243 System.out.println("创建文件夹1"+flag); 244 return thisFile; 245 }else{ 246 if(sign){ 247 try { 248 String newDirName = String.valueOf(Integer.parseInt(fileList[fileList.length-1].getName())+1); 249 File thisFile = new File(file.getAbsolutePath()+"/"+newDirName+"/"); 250 boolean flag = thisFile.mkdirs(); 251 System.out.println("创建文件夹"+newDirName+flag); 252 return thisFile; 253 } catch (Exception e) { 254 System.out.println("顺序最后一个文件夹名字获取失败,类型转化失败"); 255 } 256 } 257 } 258 return fileList[fileList.length-1]; 259 } 260 } 261 262 /** 263 * 重写Comparator接口的compare方法,可以根据FileName实现自定义排序 264 * @author SXD 265 * 266 */ 267 class OrderFile implements Comparator<File>{ 268 269 @Override 270 public int compare(File o1, File o2) { 271 int fileName1 = 0; 272 int fileName2 = 0; 273 try { 274 fileName1 = Integer.parseInt(o1.getName().substring(0, o1.getName().indexOf("."))); 275 fileName2 = Integer.parseInt(o2.getName().substring(0, o2.getName().indexOf("."))); 276 } catch (Exception e) { 277 System.out.println("比较方法中 获取文件名失败"); 278 } 279 return fileName1>fileName2 ? 1 : fileName1 == fileName2 ? 0 : -1; 280 } 281 282 } 283 /** 284 * 排序文件夹 285 * @author SXD 286 * 287 */ 288 class OrderFileS implements Comparator<File>{ 289 290 @Override 291 public int compare(File o1, File o2) { 292 int fileName1 = 0; 293 int fileName2 = 0; 294 try { 295 fileName1 = Integer.parseInt(o1.getName()); 296 fileName2 = Integer.parseInt(o2.getName()); 297 } catch (Exception e) { 298 System.out.println("比较方法中 获取文件夹名失败"); 299 } 300 return fileName1>fileName2 ? 1 : fileName1 == fileName2 ? 0 : -1; 301 } 302 303 } 304 305 /** 306 * 表示可以存储多个数据对象的容器。 307 */ 308 private final OPCPackage xlsxPackage; 309 310 /** 311 * 以最左边开始读取的列数 312 */ 313 private final int minColumns; 314 315 /** 316 * 写出数据流 317 */ 318 private final PrintStream output; 319 320 /** 321 * 创建一个新的XLSX -> CSV转换器 322 * 323 * @param pkg The XLSX package to process 324 * @param output The PrintStream to output the CSV to 325 * @param minColumns 要输出的最小列数,或-1表示最小值 326 */ 327 public XLSX2CSV(OPCPackage pkg, PrintStream output, int minColumns) { 328 this.xlsxPackage = pkg; 329 this.output = output; 330 this.minColumns = minColumns; 331 } 332 333 /** 334 *解析并显示一个工作簿的内容 335 * @param styles 工作簿中所有工作表共享的样式表。 336 * @param readOnlyTableString 这是处理共享字符串表的轻量级方式。 大多数文本单元格将引用这里的内容。请注意,如果字符串由不同格式的位组成,则每个SI条目都可以有多个T元素 337 * @param sheetInputStream 以sheet为单位的输入流 338 */ 339 public void processSheet(StylesTable styles,ReadOnlySharedStringsTable readOnlyTableString,SheetContentsHandler sheetHandler, InputStream sheetInputStream) 340 throws IOException, ParserConfigurationException, SAXException { 341 342 DataFormatter formatter = new DataFormatter(); 343 InputSource sheetSource = new InputSource(sheetInputStream); 344 try { 345 //为了尽可能的节省内存和I/0消耗,XmlReader读取Xml需要通过Read()实例方法,不断读取Xml文档中的声明,节点开始,节点内容,节点结束,以及空白等等,直到文档结束,Read()方法返回false 346 XMLReader reader = SAXHelper.newXMLReader(); 347 //XSSFSheetXMLHandler处理器,用来处理xlsx文件底层xml文件的sheet部分,用于生成行和单元格事件 348 ContentHandler handler = new XSSFSheetXMLHandler(styles, null,readOnlyTableString, sheetHandler, formatter, false); 349 //允许应用程序注册内容事件处理程序 350 reader.setContentHandler(handler); 351 //解析XML文件 352 reader.parse(sheetSource); 353 } catch (ParserConfigurationException e) { 354 throw new RuntimeException("SAX解析器坏了"+ e.getMessage()); 355 } 356 } 357 358 /** 359 * Initiates the processing of the XLS workbook file to CSV. 360 * 启动将XLS工作簿文件处理为CSV。 361 * 362 * @throws IOException 363 * @throws OpenXML4JException 364 * @throws ParserConfigurationException 365 * @throws SAXException 366 */ 367 public void process()throws IOException, OpenXML4JException, ParserConfigurationException, SAXException { 368 369 //用于构建XSSFSheetXMLHandler处理器所需要实例化的参数 370 ReadOnlySharedStringsTable readOnlyTableString = new ReadOnlySharedStringsTable(this.xlsxPackage); 371 //XSSFReader获取xlsx文件xml下的各个部分,适用于低内存sax解析或类似。 它构成了对XSSF的EventUserModel支持的核心部分。 372 XSSFReader xssfReader = new XSSFReader(this.xlsxPackage); 373 //工作簿中所有工作表共享的样式表 374 StylesTable styles = xssfReader.getStylesTable(); 375 //从org.apache.poi.xssf.eventusermodel.XSSFReader中获取到Sheet中的数据用来迭代,交给SAX去解析 376 XSSFReader.SheetIterator iter = (XSSFReader.SheetIterator) xssfReader.getSheetsData(); 377 int index = 0; 378 //此处迭代以 sheet为单位,一个工作簿进行一次解析 379 while (iter.hasNext()) { 380 InputStream inputStream = iter.next(); 381 String sheetName = iter.getSheetName(); 382 this.output.println("开始解析》》》》》》》》》》》》》》》》》》》》"); 383 this.output.println("工作簿名称:"+sheetName + " [下标=" + index + "]"); 384 processSheet(styles, readOnlyTableString, new SheetToCSV(), inputStream); 385 inputStream.close(); 386 ++index; 387 } 388 } 389 390 //可以在这里循环处理多个超大xlsx文件,逻辑中已经处理 一个超大的xlsx文件拆解开的小的xlsx文件会放在一个文件夹中 391 public static void main(String[] args) throws Exception { 392 /**********这段代码,处理多个xlsx文件,只要循环去取即可************/ 393 File xlsxFile = new File("D:/基因数据测试/S1.xlsx"); 394 if (!xlsxFile.exists()) { 395 System.err.println("没找到文件: " + xlsxFile.getPath()); 396 return; 397 } 398 /***********************/ 399 int minColumns = -1; 400 401 //打开一个POI容器 参数1 文档路径 参数2 READ READ_WRITE WRITE三种模式 402 OPCPackage p = OPCPackage.open(xlsxFile.getPath(), PackageAccess.READ); 403 404 //自己创建的xls->cvs的转化器 405 XLSX2CSV xlsx2csv = new XLSX2CSV(p, System.out, minColumns); 406 xlsx2csv.process(); 407 //关闭容器 408 p.close(); 409 } 410 }
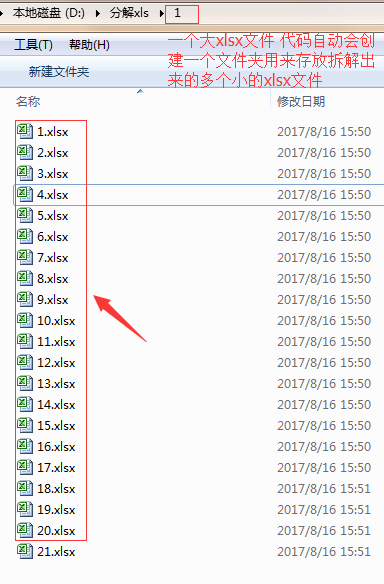
亲测 ,发现将50行拆解为一个xlsx文件,整体的速度是最合适的。 如果1000行拆解为一个xlsx文件,速度非常慢,因为每处理一个cell的数据,都会去获取xlsx文件对象。越到后面,xlsx文件中行数越大,数据越多,获取到这个xlsx对象也就越来越难以忍受。
----------------------------------------------------------------------------------待定,之后使用多线程和对象池来提高速度------------------------------------------------------------------------------------------------