一.单表查询
前期表的准备
# 创建表 create table emp( -> id int primary key auto_increment, -> name varchar(20) not null, -> gender enum('male','female') not null default 'male', -> age int(3) unsigned not null default 28, -> hire_date date not null, -> post varchar(50), -> post_comment varchar(100), -> salary double(15,2), -> office int, -> depart_id int -> ); #插入记录 #三个部门:教学,销售,运营 insert into emp(name,gender,age,hire_date,post,salary,office,depart_id) values ('jason','male',18,'20170301','张江第一帅形象代言',7300.33,401,1), #以下是教学部 ('egon','male',78,'20150302','teacher',1000000.31,401,1), ('kevin','male',81,'20130305','teacher',8300,401,1), ('tank','male',73,'20140701','teacher',3500,401,1), ('owen','male',28,'20121101','teacher',2100,401,1), ('jerry','female',18,'20110211','teacher',9000,401,1), ('nick','male',18,'19000301','teacher',30000,401,1), ('sean','male',48,'20101111','teacher',10000,401,1), ('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门 ('丫丫','female',38,'20101101','sale',2000.35,402,2), ('丁丁','female',18,'20110312','sale',1000.37,402,2), ('星星','female',18,'20160513','sale',3000.29,402,2), ('格格','female',28,'20170127','sale',4000.33,402,2), ('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门 ('程咬金','male',18,'19970312','operation',20000,403,3), ('程咬银','female',18,'20130311','operation',19000,403,3), ('程咬铜','male',18,'20150411','operation',18000,403,3), ('程咬铁','female',18,'20140512','operation',17000,403,3) ; #ps:如果在windows系统中,插入中文字符,select的结果为空白,可以将所有字符编码统一设置成gbk
1.语法执行顺序
1、统计各部门年龄在30岁以上的员工平均工资,并且保留平均工资大于10000的部门 select post,avg(salary) from emp where age >= 30 group by post having avg(salary) > 10000; # 语法这么写,但是执行顺序却不一样 from where group by having select # 大部分用到的条件就是这样了
在使用时我们可以按照执行顺序一步一步的写,这样不管多复杂的查询语句我们都可以一步一步的写出来
2.where约束条件
# 1.查询id大于等于3小于等于6的数据 select * from emp where id >=3 and id<=6; select * from emp where id between 3 and 6;
# 2.查询薪资是20000或者18000或者17000的数据 select * from emp where salary=20000 or salary=18000 or salary=17000; select * from emp where salary in (20000,18000,17000);
# 3.查询员工姓名中包含o字母的员工姓名和薪资 # 在你刚开始接触mysql查询的时候,建议你按照查询的优先级顺序拼写出你的sql语句 """ 先是查哪张表 from emp 再是根据什么条件去查 where name like ‘%o%’ 再是对查询出来的数据筛选展示部分 select name,salary """ select name,salary from emp where name like '%o%';
1 # 4.查询员工姓名是由四个字符组成的员工姓名与其薪资 2 select name,salary from emp where name like '____'; 3 select name,salary from emp where char_length(name)=4;
# 5.查询id小于3或者大于6的数据 select * from emp where id<3 and id>6; select * from emp where id not between 3 and 6;
# 6.查询薪资不在20000,18000,17000范围的数据 select * from emp where salary not in (20000,18000,17000);
补充:当数据过大时,终端不能显示,可以在获取所有数据后面加'g',这样能规范查询结果,如下图所示:

3.group by分组
# 数据分组应用场景:每个部门的平均薪资,男女比例等 # 1.按部门分组 select * from emp group by post; select id,name,gender from emp group by host;
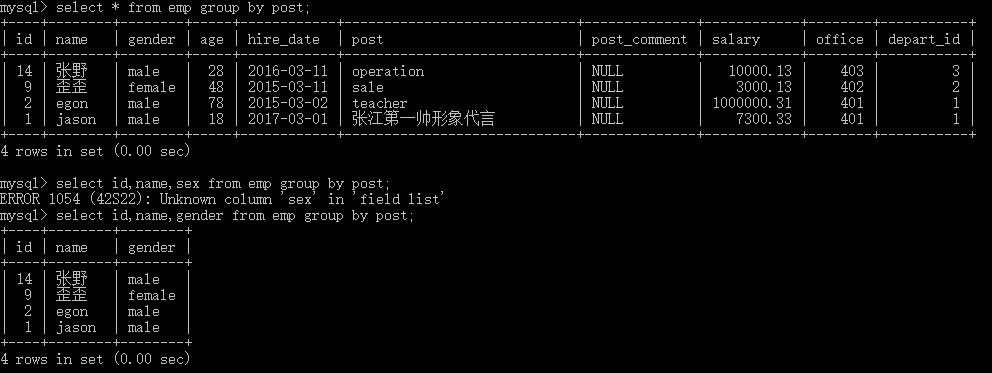
分组之后我们发现问题,分组会取出每个组的第一个数据,但是我们只是想要获取分组,而不是获取第一个数据
这时候需要我们将sql_mode设置为only_full_group_by,这样设置之后我们就能只获得分组,而不会获得具体的数据,然后再根据分组来筛选条件获取数据
# 查看mode模式 show variables like '%mode%'; # 改变mode模式 set global sql_mode='strict_trans_tables,only_full_group_by'; # 修改完成后一定要重启客户端!!!
重启客户端之后显示sql_mode已修改完成
# 重连客户端后再获取部门的数据 select * from emp group by post; # 报错 select id,name from emp group by post; # 报错 select post from emp group by post; # 获取部门信息
注意:只要分组了,就不能再'直接'查找到单个数据了,只能获取组名
分组后数据不能被直接获取了,但是我们可以通过'聚合函数'间接的获取
# 聚合函数的分类 ''' max(字段名):求最大值 min(字段名):求最小值 avg(字段名):求平均值 sum(字段名):求总和 count(字段名):计数 '''
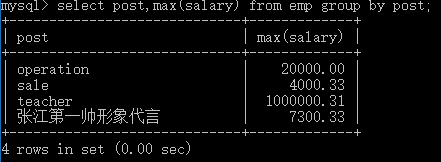
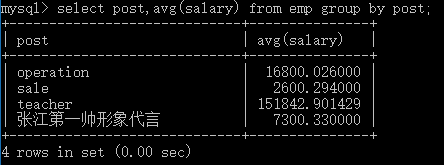
# 2.获取每个部门的最高工资 # 以组为单位统计组内数据>>>聚合查询(聚集到一起合成为一个结果) # 每个部门的最高工资 select post,max(salary) from emp group by post; # 每个部门的最低工资 select post,min(salary) from emp group by post; # 每个部门的平均工资 select post,avg(salary) from emp group by post; # 每个部门的工资总和 select post,sum(salary) from emp group by post; # 每个部门的人数 select post,count(id) from emp group by post;



注意:在查询人数的时候我们可以使用任意的非空字段来作为计数,但是推荐能够唯一标识数据的字段,比如id
在分组的情况下查不到单个的数据,但是我们可以使用group_concat查看所有的数据,还可以用来拼接字符串
# 3.查询分组之后的部门名称和每个部门下所有的学生姓名 # group_concat(分组之后用)不仅可以用来显示除分组外字段还有拼接字符串的作用 # 查询各部门所有的人员姓名 select post,group_concat(name) from emp group by post; # 在姓名后拼接字符串 select post,group_concat(name,'sb') from emp group by post; select post,group_concat(name,':',salary) from emp group by post; select post,group_concat(name,':',age) from emp group by post;
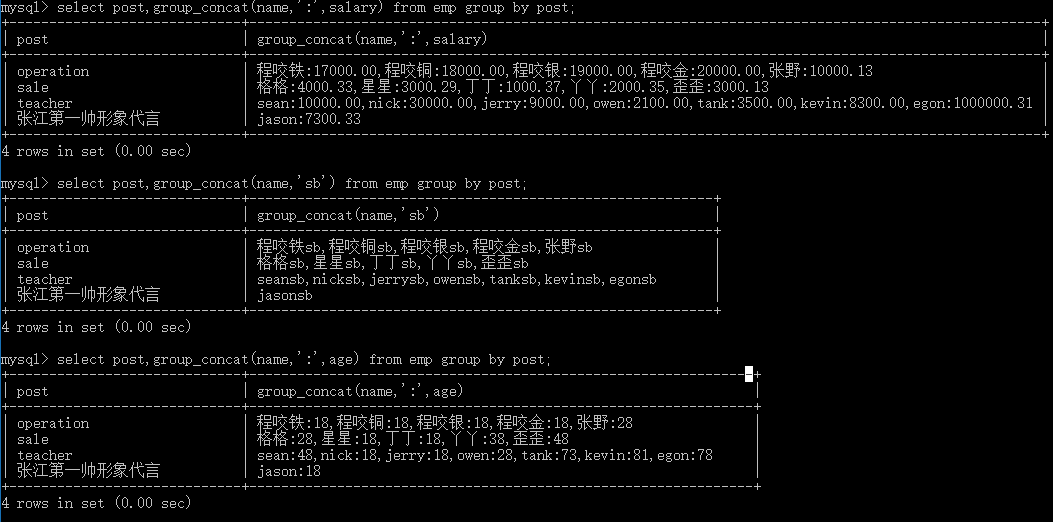
concat用来拼接表中的字符,as用来给表头起别名
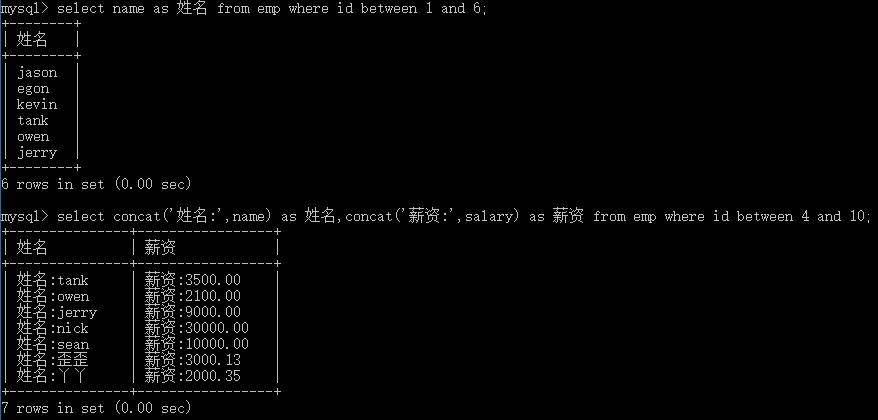
# 4.补充concat(不分组时用)拼接字符串达到更好的显示效果 as语法使用 # concat用来给表中数据拼接字符,as用来给表头起别名 select name as 姓名 from emp between 1 and 6; select concat('姓名:',name) as 姓名,concat('薪资:',salary) as 薪资 from emp where id between 4 and 10
select concat_ws(',',name,age,gender) as info from emp; # 使用concat_ws可以给字段中加入想要加入的字符串

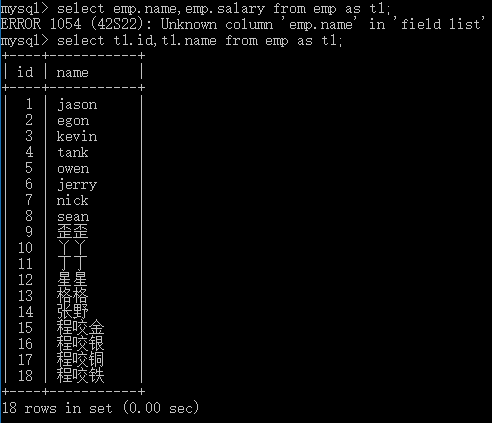
# 补充as语法 即可以给字段起别名也可以给表起别名 select t1.id,t1.name from emp as t1; # 起别名之后在这段语句中就不能再使用原表名了 select emp.name,emp.salary from emp as t1; # 报错,因为已经起了别名
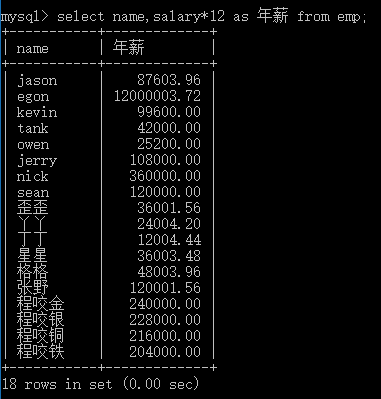
# 查询四则运算 # 查询每个人的年薪 select name,salary*12 from emp; select name,salary*12 as 年薪 from emp; # 查询每个人的日薪 select name,salary/30 as 日薪 from emp; # 查询5年后的年龄 select name,age+5 as 5年后的年龄 from emp; # 查询3年前的年龄 select name,age-3 as 3年前的年龄 from emp;
练习题
# 刚开始查询表,一定要按照最基本的步骤,先确定是哪张表,再确定查这张表也没有限制条件,再确定是否需要分类,最后再确定需要什么字段对应的信息 1. 查询岗位名以及岗位包含的所有员工名字 select post,group_concat(name) from emp group by post; 2. 查询岗位名以及各岗位内包含的员工个数 select post,count(id) from emp group by post; 3. 查询公司内男员工和女员工的个数 select gender,count(id) from emp group by gender; 4. 查询岗位名以及各岗位的平均薪资 select post,avg(salary) from emp group by post; 5. 查询岗位名以及各岗位的最高薪资 select post,max(salary) from emp group by post; 6. 查询岗位名以及各岗位的最低薪资 select post,min(salary) from emp group by post; 7. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资 select gender,avg(salary) from emp group by gender;
1.当关键字where和group by同时出现的情况下,group by按照执行顺序必须跟在where之后
2.where先根据后面的条件对表进行筛选,group by再根据筛选过的表再进行分类
3.聚合函数必须可以跟在group by后面,也可以跟在执行顺序最后的select后面,但是不能跟在where后面
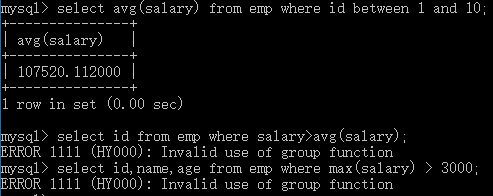
# 可以跟在select后面 select avg(salary) from emp where id between 1 and 10; # 不可以跟在where后面 select id from emp where salary>avg(salary); # 报错 # 报错类型:ERROR 1111 (HY000): Invalid use of group function
# 查询语句的语法顺序 select>>>from>>>where>>>group by # 查询语句的执行顺序 from>>>where>>>group by>>>select
8、统计各部门年龄在30岁以上的员工平均工资 select post,avg(salary) from emp where age>30 group by post;

4.having约束条件
1.having和where一样都是用来筛选数据的,只不过having是跟在group by之后的,where是对整体数据进行筛选,而having是在分组之后进行筛选
2.having语法格式和where一致
3.having可以使用聚合函数
# 1、统计各部门年龄在30岁以上的员工平均工资,并且保留平均工资大于10000的部门 select post,avg(salary) from emp where age>30 group by post having avg(salary)>10000;

强调:having必须跟在group by后面使用
5.distinct去重
去重的数据必须有一模一样的数据才能去重
# 对有重复的展示数据进行去重操作 select distinct id,age from emp; # 并不能去重,因为id肯定是不一样的 select distinct age from emp; # 可以去重,有重复的

6.order by排序
# 升序排序 select * from emp order by salary; # 默认升序排 select * from emp order by salary asc; # 升序 # 降序排序 select * from emp order by salary desc; # 降序 # 先按照年龄降序排列,如果年龄相同就按照薪资升序排列 select * from emp order by age desc,salary asc; # 统计各部门年龄在10岁以上的员工平均工资,并且保留平均工资大于1000的部门,然后对平均工资进行排序 select post,avg(salary) from emp where age>10 group by post having avg(salary)>1000 order by avg(salary);

7.limit限制展示条数
# 限制展示条数 select * from emp limit 3; # 限制每次展示三条 # 查询工资最高的人的详细信息 select * from emp order by salary desc limit 1; # 按工资降序排序并限制展示第一条,即工资最高的那个人

# 分页显示 select * from emp limit 5,6; # 第一个参数为展示的起始位置,第二个参数表示展示的条数,即从第五条开始展示,往后展示六条

8.正则
select * from emp where name regexp '^j.*(n|y)$'; # 展示以j开头并且以n或者y结尾的数据

二.多表查询
表的创建
#建表 create table dep( id int, name varchar(20) ); create table emp( id int primary key auto_increment, name varchar(20), sex enum('male','female') not null default 'male', age int, dep_id int ); #插入数据 insert into dep values (200,'技术'), (201,'人力资源'), (202,'销售'), (203,'运营'); insert into emp(name,sex,age,dep_id) values ('jason','male',18,200), ('egon','female',48,201), ('kevin','male',38,201), ('nick','female',28,202), ('owen','male',18,200), ('jerry','female',18,204) ; # 当初为什么我们要分表,就是为了方便管理,在硬盘上确实是多张表,但是到了内存中我们应该把他们再拼成一张表进行查询才合理
表的查询
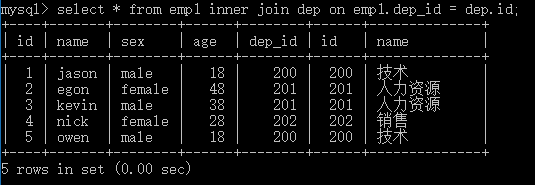
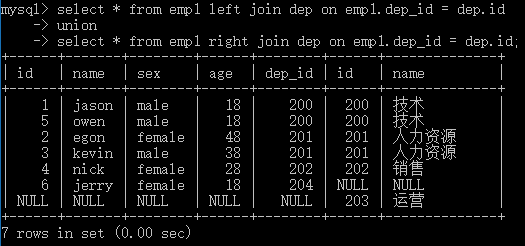
select * from emp,dep; # 左表一条记录与右表所有记录都对应一遍>>>笛卡尔积 # 将所有的数据都对应了一遍,虽然不合理但是其中有合理的数据,现在我们需要做的就是找出合理的数据 # 查询员工及所在部门的信息 select * from emp,dep where emp.dep_id = dep.id; # 查询部门为技术部的员工及部门信息 select * from emp,dep where emp.dep_id = dep.id and dep.name = '技术'; # 将两张表关联到一起的操作,有专门对应的方法 # 1、内连接:只取两张表有对应关系的记录 select * from emp inner join dep on emp.dep_id = dep.id; select * from emp inner join dep on emp.dep_id = dep.id where dep.name = "技术"; # 2、左连接: 在内连接的基础上保留左表没有对应关系的记录 select * from emp left join dep on emp.dep_id = dep.id; # 3、右连接: 在内连接的基础上保留右表没有对应关系的记录 select * from emp right join dep on emp.dep_id = dep.id; # 4、全连接:在内连接的基础上保留左、右面表没有对应关系的的记录 select * from emp left join dep on emp.dep_id = dep.id union select * from emp right join dep on emp.dep_id = dep.id;
子查询
# 就是将一个查询语句的结果用括号括起来当作另外一个查询语句的条件去用 # 1.查询部门是技术或者人力资源的员工信息 """ 先获取技术部和人力资源部的id号,再去员工表里面根据前面的id筛选出符合要求的员工信息 """ select * from emp where dep_id in (select id from dep where name = "技术" or name = "人力资源"); # 2.每个部门最新入职的员工 思路:先查每个部门最新入职的员工,再按部门对应上联表查询 select t1.id,t1.name,t1.hire_date,t1.post,t2.* from emp as t1 inner join (select post,max(hire_date) as max_date from emp group by post) as t2 on t1.post = t2.post where t1.hire_date = t2.max_date ; """ 记住一个规律,表的查询结果可以作为其他表的查询条件,也可以通过其别名的方式把它作为一张虚拟表去跟其他表做关联查询 """ select * from emp inner join dep on emp.dep_id = dep.id;

exist返回的是一个bool值,当为True执行外层语句,为False不执行外层语句
# exist(了解) EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录, 而是返回一个真假值,True或False。 当返回True时,外层查询语句将进行查询 当返回值为False时,外层查询语句不进行查询。 select * from emp where exists (select id from dep where id > 3); select * from emp where exists (select id from dep where id > 250);
37