一、安装版本
链接:https://pan.baidu.com/s/1WD_clSNZGkbL5FDT43IoNg
提取码:mhzm
filebeat-7.4.0-linux-x86_64.tar.gz
elasticsearch-7.4.0-linux-x86_64.tar.gz
kibana-7.4.0-linux-x86_64.tar.gz
logstash-7.4.0.tar.gz
kafka_2.12-2.3.0.tgz
二、各组件作用
filebeat:一个日志文件托运工具,在你的服务器上安装客户端后,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件。
elasticsearch:基于 JSON 的分布式搜索和分析引擎,专为实现水平扩展、高可靠性和管理便捷性而设计。
kibana:能够以图表的形式呈现数据,并且具有可扩展的用户界面,供您全方位配置和管理 Elastic Stack。
logstash:具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。
kafka:一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。
三、filebeat安装与配置
# 把filebeat包传至想要收集日志的应用机器上,解压到指定目录 tar -xzf filebeat-7.4.0-linux-x86_64.tar.gz -C /opt/app # 改名 mv filebeat-7.4.0 filebeat # 修改filebeat.yml - type: log enabled: true paths: - /opt/applog/ldp/daily.log # 采集日志的路径 fields: log_topic: "test-ldp" # topic名字 multiline.pattern: ^[ multiline.negate: true multiline.match: after # 输出到kafka output.kafka: hosts: ["xxx.xxx.xxx.xxx:9092"] topic: '%{[fields][log_topic]}' # 启动filebeat(前提:filebeat安装机器与安装kafka的机器网络层相通) cd /opt/app/filebeat nohup ./filebeat -e -c filebeat.yml > /opt/applog/filebeat.log & # 如果启动日志出现Failed to connect to broker vm-vmwxxx-app:9092: dial tcp: lookup vm-vmwxxx-app on [::1]:53: read udp [::1]:33342->[::1]:53: read: connection refused # 解决方法 切换到root用户执行:vi /etc/hosts 在文件末尾添加部署kafka机器的IP与主机名即可
以下elasticsearch、kibana、logstash、kafka都是在同一台虚拟机上安装,基于elk用户。
添加组:groupadd elk 添加用户:useradd elk -m -s /bin/bash -d /home/elk -g elk 给elk添加密码:passwd elk

四、kafka安装与配置
1.解压安装包到指定目录
# 解压文件并改名 tar -xzf kafka_2.12-2.3.0.tgz -C /DATA/elk mv kafka_2.12-2.3.0 kafka # 修改kafka配置 cd /DATA/elk/kafka/config vi server.properties broker.id=0 port=9092 #端口号 log.dirs=/DATA/logs/kafka #日志存放路径可修改可不修改 zookeeper.connect=xxx.xxx.xxx.xxx:2181 #zookeeper地址和端口
2.zk配置(使用其自带的Zookeeper)
# zk配置文件名:zookeeper.properties cd /DATA/elk/kafka/config vi zookeeper.properties # zk配置 dataDir=/DATA/logs/zk_data dataLogDir=/DATA/logs/zk_log clientPort=2181 maxClientCnxns=100 tickTime=2000 initLimit=10
3.编写启停脚本
# 启动脚本 #!/bin/bash #启动zookeeper /DATA/elk/kafka/bin/zookeeper-server-start.sh /DATA/elk/kafka/config/zookeeper.properties & # 3s后启动kafka sleep 3 #启动kafka /DATA/elk/kafka/bin/kafka-server-start.sh /DATA/elk/kafka/config/server.properties & # 停止脚本 #!/bin/bash #关闭kafka /DATA/elk/kafka/bin/kafka-server-stop.sh /DATA/elk/kafka/config/server.properties & # 3s后关闭zk sleep 3 #关闭zookeeper /DATA/elk/kafka/bin/zookeeper-server-stop.sh /DATA/elk/kafka/config/zookeeper.properties &
执行启动脚本,待服务起来后可以创建topic试下效果:
# 进入到kafka bin目录 cd /DATA/elk/kafka/bin # 创建topic 出现Created topic ldp-test.说明创建成功 ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic ldp-test # 查看topic ./kafka-topics.sh --list --zookeeper localhost:2181 # 删除topic ./kafka-topics.sh --delete --zookeeper localhost:2181 --topic ldp-test
使用终端打开两个窗口来验证生产者和消费者的通信
# 生产者
./kafka-console-producer.sh --broker-list localhost:9092 --topic ldp-test

# 消费者
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic ldp-test --from-beginning

生产者发送消息

消费者接收消息

重启filebeat,执行查看topic命令看之前filebeat中配置的topic名字有没有出现在列表里

查看消费者信息,有出现信息说明filebeat到kafka数据流通成功。

五、logstash安装与配置
将logstash包解压到指定目录,编辑文件
cd config/ # conf文件放置在该目录下 mkdir conf.d cd conf.d # 创建conf文件,名字自定义 touch ldp-pipeline.conf vi ldp-pipeline.conf input { kafka { bootstrap_servers => "xxx.xxx.xxx.xxx:9092" topics => "test-ldp" group_id => "ldp-group" client_id => "ldp-client" codec => "json" id => "test-ldp" } } output { elasticsearch { hosts => ["xxx.xxx.xxx.xxx:9200"] index => "test-ldp-index-%{+YYYY.MM.dd}" } }
修改logstash.yml文件
node.name: xxx.xxx.xxx.xxx path.data: /DATA/elk/logstash/data http.host: xxx.xxx.xxx.xxx http.port: 9600 log.level: info path.logs: /DATA/logs/logstash
修改pipelines.yml文件
- pipeline.id: test-ldp path.config: "/DATA/elk/logstash/config/conf.d/ldp-pipeline.conf" pipeline.workers: 1 pipeline.batch.size: 125 pipeline.batch.delay: 50 queue.type: memory
六、安装es
将es包解压至指定目录,配置jdk环境,本例采用jdk1.8
# 修改es配置文件 cd /DATA/elk/elasticsearch/config vi elasticsearch.yml path.logs: /DATA/logs/es network.host: xxx.xxx.xxx.xxx cluster.initial_master_nodes: ["node-1"]
在bin目录下启动es
nohup ./elasticsearch &
启动时报错解决方案:
a.# 若出现ERROR: bootstrap checks failed[1]: max file descriptors [4096] for elasticsearch process is too low。。。。 解决方案: # 切换到root用户修改 vim /etc/security/limits.conf # 在最后面追加下面内容 * soft nofile 65536 * hard nofile 65536 * soft nproc 4096 * hard nproc 4096 # 退出重新登录检测配置是否生效: ulimit -Hn ulimit -Sn ulimit -Hu ulimit -Su b.重新启动出现如下错误 ERROR: max number of threads [3802] for user [chenyn] is too low,increase to at least [4096]** 解决方案: #进入limits.d目录下修改配置文件。 vim /etc/security/limits.d/20-nproc.conf # 修改为 启动ES用户名 soft nproc 4096 c.重新启动出现如下错误 ERROR: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]** 解决方案: vim /etc/sysctl.conf vm.max_map_count=655360 #执行以下命令生效: sysctl -p
es完成后启动logstash
cd /DATA/elk/logstash/bin
nohup ./logstash &
观察日志有无报错信息

通过elasticsearch看整个流程数据是否正确流通
查看索引:curl 'xxx.xxx.xxx.xxx:9200/_cat/indices?v'

根据索引查询数据:curl -XGET 'xxx.xxx.xxx.xxx:9200/test-ldp-index/_search?pretty'
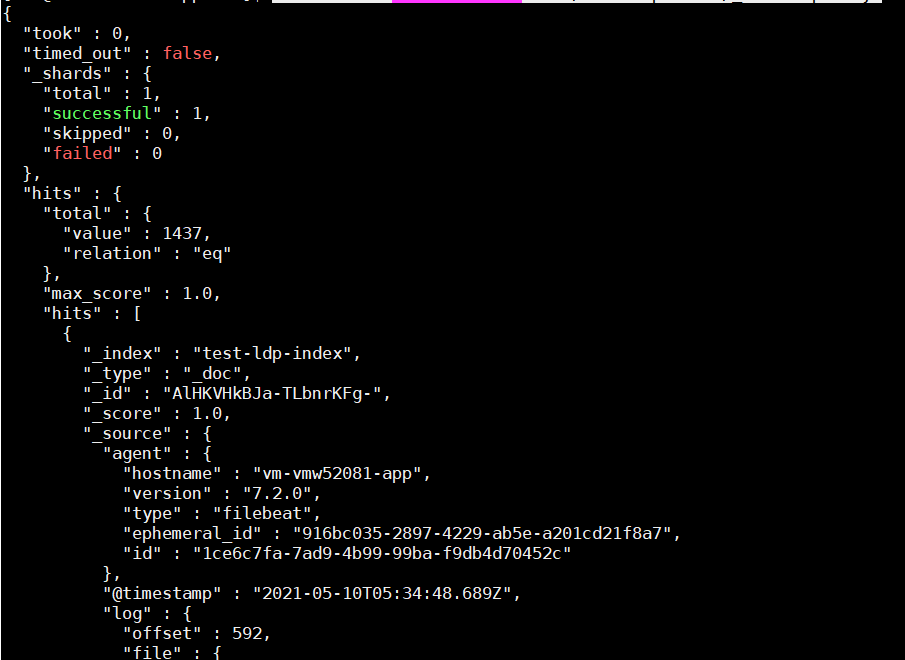
这就证明整个流程下来数据流通无误。
七、安装kibana
解压包到指定目录,修改kibana.yml配置文件。
cd config vi kibana.yml server.host: "xxx.xxx.xxx.xxx" elasticsearch.hosts: ["http://esip:9200"]
启动kibana
cd /DATA/elk/kibana/bin
./kibana &
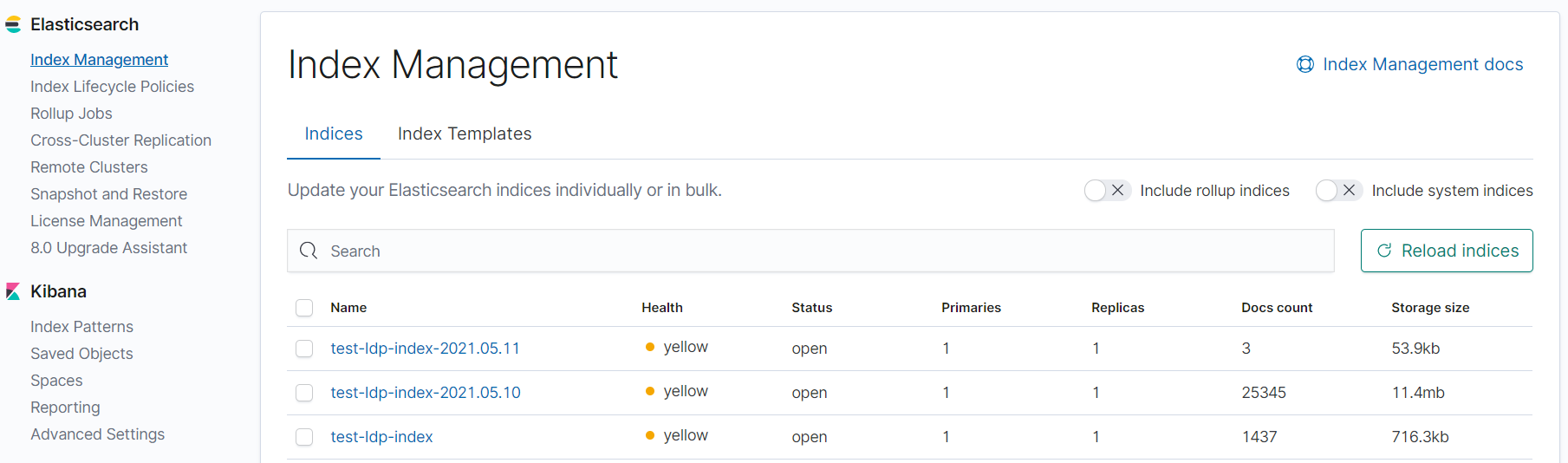
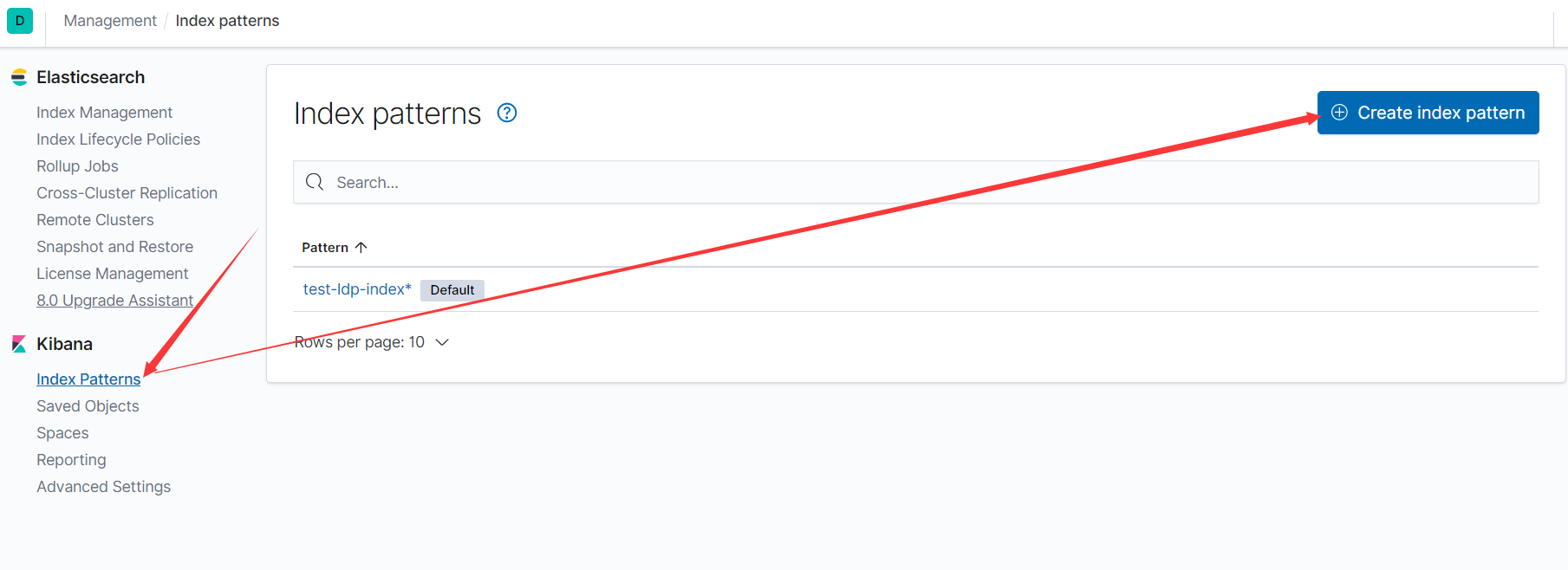
创建索引
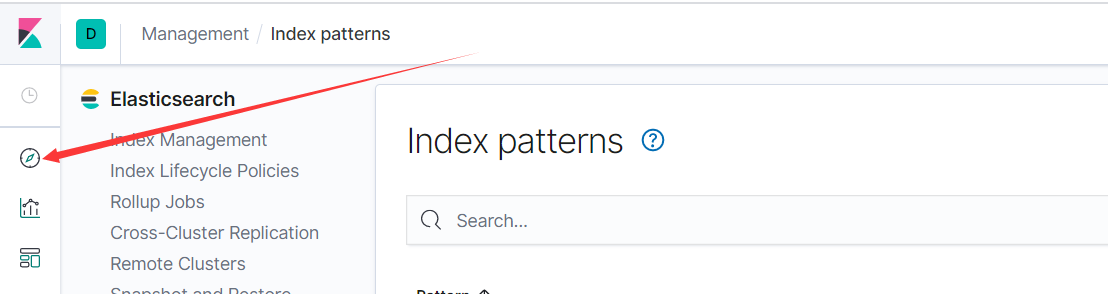
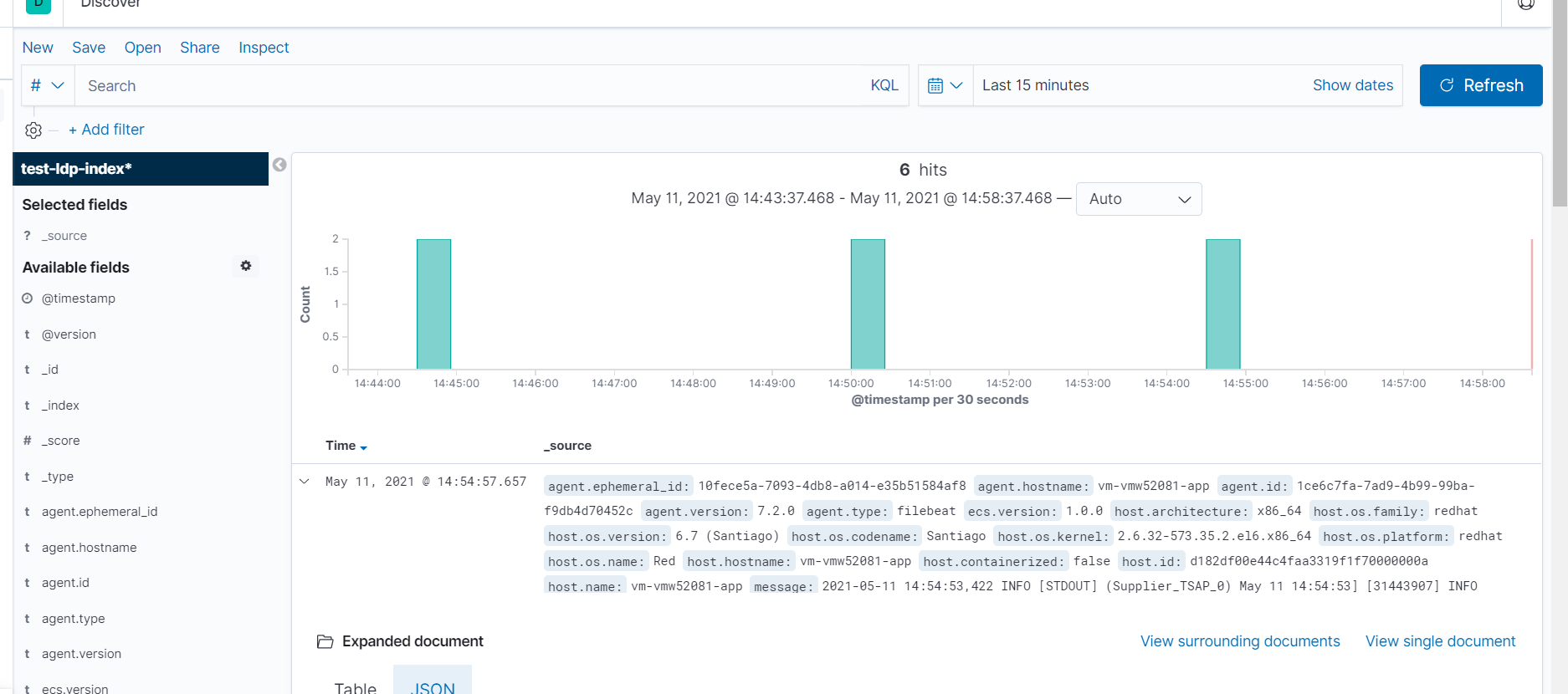
查看数据
参考:【https://www.cnblogs.com/jiashengmei/p/8857053.html】