1 你是如何实现Flume数据传输的监控的
使用第三方框架Ganglia实时监控Flume。
2 Flume的Source,Sink,Channel的作用?你们Source是什么类型?
1、作用 (1)Source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy (2)Channel组件对采集到的数据进行缓存,可以存放在Memory或File中。 (3)Sink组件是用于把数据发送到目的地的组件,目的地包括Hdfs、Logger、avro、thrift、ipc、file、Hbase、solr、自定义。
2、我公司采用的Source类型为: (1)监控后台日志:exec (2)监控后台产生日志的端口:netcat
3 Flume 的 Channel Selectors

4 Flume 参数调优
Source 增加Source个数(使用Tair Dir Source时可增加FileGroups个数)可以增大Source的读取数据的能力。 例如:当某一个目录产生的文件过多时需要将这个文件目录拆分成多个文件目录,同时配置好多个 Source 以保证 Source 有足够的能力获取到新产生的数据。 batchSize 参数决定 Source 一次批量运输到 Channel 的event条数,适当调大这个参数可以提高 Source 搬运 Event 到 Channel 时的性能。
Channel type 选择 memory 时 Channel 的性能最好,但是如果 Flume 进程意外挂掉可能会丢失数据。type 选择 file 时 Channel 的容错性更好,但是性能上会比 memory channel 差。 使用file Channel时 dataDirs 配置多个不同盘下的目录可以提高性能。 Capacity 参数决定 Channel 可容纳最大的 event 条数。transactionCapacity 参数决定每次 Source 往 channel 里面写的最大event 条数和每次 Sink 从channel 里面读的最大 event 条数。transactionCapacity 需要大于 Source 和Sink的batchSize 参数。
Sink 增加 Sink 的个数可以增加 Sink 消费 event 的能力。Sink 也不是越多越好够用就行,过多的 Sink 会占用系统资源,造成系统资源不必要的浪费。 batchSize 参数决定 Sink 一次批量从 Channel 读取的 event 条数,适当调大这个参数可以提高 Sink 从 Channel 搬出 event 的性能。
5 Flume 的事务机制
Flume的事务机制(类似数据库的事务机制):
Flume 使用两个独立的事务分别负责从 Soucrce 到 Channel(put),以及从 Channel 到Sink 的事件传递(take)。
比如 spooling directory source 为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到 Channel 且提交成功,那么 Soucrce 就将该文件标记为完成。
同理,事务以类似的方式处理从 Channel 到 Sink 的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到 Channel 中,等待重新传递。
6 Flume 采集数据会丢失吗?
不会,Channel 存储可以存储在 File 中,数据传输自身有事务。
------------------------------------------------------------------------------------------------------
1.Flume 采集数据会丢失吗?
不会,Channel 存储可以存储在 File 中,数据传输自身有事务。
2.Flume 与 Kafka 的选取?
采集层主要可以使用 Flume、Kafka 两种技术。
Flume:Flume 是管道流方式,提供了很多的默认实现,让用户通过参数部署,及扩展 API。
Kafka:Kafka 是一个可持久化的分布式的消息队列。
Kafka 是一个非常通用的系统。你可以有许多生产者和很多的消费者共享多个主题Topics。相比之下,Flume 是一个专用工具被设计为旨在往 HDFS,HBase 发送数据。它对HDFS 有特殊的优化,并且集成了 Hadoop 的安全特性。所以,Cloudera 建议如果数据被多个系统消费的话,使用 kafka;如果数据被设计给 Hadoop 使用,使用 Flume。正如你们所知 Flume 内置很多的 source 和 sink 组件。然而,Kafka 明显有一个更小的生产消费者生态系统,并且 Kafka 的社区支持不好。希望将来这种情况会得到改善,但是目前:使用 Kafka 意味着你准备好了编写你自己的生产者和消费者代码。如果已经存在的 Flume Sources 和 Sinks 满足你的需求,并且你更喜欢不需要任何开发的系统,请使用 Flume。Flume 可以使用拦截器实时处理数据。这些对数据屏蔽或者过量是很有用的。Kafka 需要外部的流处理系统才能做到。
Kafka 和 Flume 都是可靠的系统,通过适当的配置能保证零数据丢失。然而,Flume 不支持副本事件。于是,如果 Flume 代理的一个节点奔溃了,即使使用了可靠的文件管道方式,你也将丢失这些事件直到你恢复这些磁盘。如果你需要一个高可靠行的管道,那么使用Kafka 是个更好的选择。
Flume 和 Kafka 可以很好地结合起来使用。如果你的设计需要从 Kafka 到 Hadoop 的流数据,使用 Flume 代理并配置 Kafka 的 Source 读取数据也是可行的:你没有必要实现自己的消费者。你可以直接利用Flume 与HDFS 及HBase 的结合的所有好处。你可以使用ClouderaManager 对消费者的监控,并且你甚至可以添加拦截器进行一些流处理。
3.数据怎么采集到 Kafka,实现方式?
使用官方提供的 flumeKafka 插件,插件的实现方式是自定义了 flume 的 sink,将数据从channle 中取出,通过 kafka 的producer 写入到 kafka 中,可以自定义分区等。
4.flume 管道内存,flume 宕机了数据丢失怎么解决?
1)Flume 的 channel 分为很多种,可以将数据写入到文件。
2)防止非首个 agent 宕机的方法数可以做集群或者主备
5. flume 和 kafka 采集日志区别,采集日志时中间停了,怎么记录之前的日志?
Flume 采集日志是通过流的方式直接将日志收集到存储层,而 kafka 是将缓存在 kafka集群,待后期可以采集到存储层。
Flume 采集中间停了,可以采用文件的方式记录之前的日志,而 kafka 是采用 offset 的方式记录之前的日志。
6.flume 有哪些组件,flume 的 source、channel、sink 具体是做什么的?

1)source:用于采集数据,Source 是产生数据流的地方,同时 Source 会将产生的数据
流传输到 Channel,这个有点类似于 Java IO 部分的 Channel。
2)channel:用于桥接 Sources 和 Sinks,类似于一个队列。
3)sink:从 Channel 收集数据,将数据写到目标源(可以是下一个 Source,也可以是 HDFS
或者 HBase)。
7.为什么使用Flume?

8.Flume组成架构?

关于flume事务
flume要尽可能的保证数据的安全性,其在source推送数据到channel以及sink从channel拉取数据时都是以事务方式进行的。因为在agent内的两次数据传递间都会涉及到数据的传送、从数据上游删除数据的问题;就比如sink从channel拉取数据并提交到数据下游之后需要从channel中删除已获取到的批次数据,其中跨越了多个原子事件,故而需要以事务的方式将这些原子事件进一步绑定在一起,以便在其中某个环节出错时进行回滚防止数据丢失。所以在选用file channel时一般来说是不会丢失数据的。
9.FlumeAgent内部原理?

10.Flume Event 是数据流的基本单元
它由一个装载数据的字节数组(byte payload)和一系列可选的字符串属性来组成(可选头部).

11.Flume agent
Flume source 消耗从类似于 web 服务器这样的外部源传来的 events.
外部数据源以一种 Flume source 能够认识的格式发送 event 给 Flume source.
Flume source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy.
flume source 是负责接收数据到 Flume Agent 的组件
2. Flume channel
当 Flume source 接受到一个 event 的时, Flume source 会把这个 event 存储在一个或多个 channel 中.
Channel 是连接Source和Sink的组件, 是位于 Source 和 Sink 之间的数据缓冲区。
Flume channel 使用被动存储机制. 它存储的数据的写入是靠 Flume source 来完成的, 数据的读取是靠后面的组件 Flume sink 来完成的.
Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个 Sink 的读取操作。
Flume 自带两种 Channel:
Memory Channel
Memory Channel是内存中的队列。
Memory Channel在不需要关心数据丢失的情景下适用。
如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel。
File Channel将所有事件写到磁盘。
因此在程序关闭或机器宕机的情况下不会丢失数据。
还可以有其他的 channel: 比如 JDBC channel.
3. Flume sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者发送到另一个Flume Agent。
Sink 是完全事务性的。
在从 Channel 批量删除数据之前,每个 Sink 用 Channel 启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,Sink 就利用 Channel 提交事务。事务一旦被提交,该 Channel 从自己的内部缓冲区删除事件。如果写入失败,将缓冲区takeList中的数据归还给Channel。
Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义。
12.你是如何实现Flume数据传输的监控的
使用第三方框架Ganglia实时监控Flume。
13.flume 调优 :
source :
1 ,增加 source 个数,可以增大 source 读取能力。
2 ,具体做法 : 如果一个目录下生成的文件过多,可以将它拆分成多个目录。每个目录都配置一个 source 。
3 ,增大 batchSize : 可以增大一次性批处理的 event 条数,适当调大这个参数,可以调高 source 搬运数据到 channel 的性能。
channel :
1 ,memory :性能好,但是,如果发生意外,可能丢失数据。
2 ,使用 file channel 时,dataDirs 配置多个不同盘下的目录可以提高性能。
3 ,transactionCapacity 需要大于 source 和 sink 的 batchSize 参数
sink :
增加 sink 个数可以增加消费 event 能力
------------------------------------------------------------------------------------------------------------------------------------
1 ,如何实现 flume 传输数据的实时监控
使用第三方框架 ganglia
2 ,flume 的 source,sink,channel 的作用,你们的 source 类型是 ?
source :搜集数据
channel :数据缓存
sink :把数据发送到目的地
常用 source 类型 :
1 ,监控文件 :exec
2 ,监控目录 :spooldir
3 ,flume 选择器 :
包括两种 :
1 ,每个通道都复制一份文件,replicating 。
2 ,选择性发往某个通道,Multiplexing 。
4 ,flume 调优 :
source :
1 ,增加 source 个数,可以增大 source 读取能力。
2 ,具体做法 : 如果一个目录下生成的文件过多,可以将它拆分成多个目录。每个目录都配置一个 source 。
3 ,增大 batchSize : 可以增大一次性批处理的 event 条数,适当调大这个参数,可以调高 source 搬运数据到 channel 的性能。
channel :
1 ,memory :性能好,但是,如果发生意外,可能丢失数据。
2 ,使用 file channel 时,dataDirs 配置多个不同盘下的目录可以提高性能。
3 ,transactionCapacity 需要大于 source 和 sink 的 batchSize 参数
sink :
增加 sink 个数可以增加消费 event 能力
5 ,事务机制 :
channel : 是位于 source 和 sink 之间的缓冲区。
1 ,flume 自带两种缓冲区,file channel 和 memory channel
2 ,file channel : 硬盘缓冲区,性能低,但是安全。系统宕机也不会丢失数据。
3 ,memory channel :内存缓冲区,性能高,但是有可能丢数据,在不关心数据有可能丢失的情况下使用。
put 事务流程 : 源将数据给管道
1 ,doPut :把数据写入临时缓冲区 putList 。
2 ,doCommit :检查 channel 内存队列是否足够合并。
3 ,doRollBack : 如果 channel 不行,我们就回滚数据。
take 事务流程 :
1 ,先将数据取到临时缓冲区 takeList。
2 ,doCommit :如果数据全部发送成功,就清除临时缓冲区。
3 ,doRollBack :如果数据发送过程中出现异常,doRollBack 将临时缓冲区的数据还给 channel 队列
6 ,flume 传数据会丢失吗 :
不会,因为 channel 可以存储在 file 中,而且 flume 本身是有事务的。
可以做 sink 组,一个坏掉了,就用另一个。
7 ,个人总结 : flume 总结
transactionCapacity :事务容量大小,指的就是 putList 和 takeList 的大小
transactionCapacity > batchSize
-----------------------------------------------------------------------------------------------------------------------------
1 怎样对Flume 数据传输进行监控
使用第三方框架 Ganglia 实时监控 Flume。
2 Flume的Source ,Sink ,Channel的作用? 使用过哪些Source类型?
作用
Source 组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy
Channel 组件对采集到的数据进行缓存,可以存放在 Memory 或 File 中。
Sink 组件是用于把数据发送到目的地的组件,目的地包括 Hdfs、Logger、avro、thrift、ipc、file、Hbase、solr、自定义。
常用的Source 类型:
(1)监控后台日志:exec
(2)监控后台产生日志的端口:netcat ,Exec spooldir
3 Flume 的 Channel Selectors有几种
Channel Selectors,可以让不同的项目日志通过不同的Channel到不同的Sink中去。
官方文档上Channel Selectors 有两种类型:Replicating Channel Selector (default)和Multiplexing Channel Selector
这两种Selector的区别是:Replicating 会将source过来的events发往所有channel,而Multiplexing可以选择该发往哪些Channel。
4 Flume参数调优
Source
增加 Source 个(使用 Tair Dir Source 时可增加 FileGroups 个数)可以增大 Source 的读取数据的能力。例如:当某一个目录产生的文件过多时需要将这个文件目录拆分成多个文件目录,同时配置好多个 Source 以保证 Source 有足够的能力获取到新产生的数据。batchSize 参数决定 Source 一次批量运输到 Channel 的 event 条数,适当调大这个参数可以提高 Source 搬运 Event 到 Channel 时的性能。
Channel
type 选择 memory 时 Channel 的性能最好,但是如果 Flume 进程意外挂掉可能会丢失数据。type 选择 file 时 Channel 的容错性更好,但是性能上会比 memory channel 差。使用 file Channel 时 dataDirs 配置多个不同盘下的目录可以提高性能。
Capacity 参数决定 Channel 可容纳最大的 event 条数。transactionCapacity 参数决定每次Source 往 channel 里面写的最大 event 条数和每次 Sink 从 channel 里面读的最大 event 条数。
transactionCapacity 需要大于 Source 和 Sink 的 batchSize 参数。
Sink
增加 Sink 的个数可以增加 Sink 消费 event 的能力。Sink 也不是越多越好够用就行,过多的 Sink 会占用系统资源,造成系统资源不必要的浪费。
batchSize 参数决定 Sink 一次批量从 Channel 读取的 event 条数,适当调大这个参数可以提高 Sink 从 Channel 搬出 event 的性能。
5 Flume的事务机制
Flume 的事务机制(类似数据库的事务机制):Flume 使用两个独立的事务分别负责从Soucrce 到 Channel,以及从 Channel 到 Sink 的事件传递。比如 spooling directory source 为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到 Channel 且提交成功,那么Soucrce 就将该文件标记为完成。同理,事务以类似的方式处理从 Channel 到 Sink 的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到Channel 中,等待重新传递。
6 Flume可以保证采集和发送数据的正确性吗?
在单机 upd环境下,采集数据时,如果读写大于100M/s的情况下会出现丢包现象,可以对丢失率进行统计,如果在可接受范围内不做处理,如果不能接受可以修改源码或者借鉴flume原理自行开发收集框架;
对收集到的数据,flume可以将其存储下磁盘中,且数据传输自身有事务。确保发送数据不丢失。
-----------------------------------------------------------------------------------------------------------------------------
Flume + Kafka 面试
1、flume 如何保证数据的可靠性?
- Flume 提供三种可靠性:JDBC、FILE、MEMORY
- Flume 使用事务的办法来保证 event 的可靠传递。Source 和 Sink 分别被封装在事务中,这些事务由保存 event 的存储提供或者由 Channel 提供。这就保证了 event 在数据流的点对点传输中是可靠的。
2、kafka 数据丢失问题,及如何保证?
1、kafka 数据丢失问题
a、acks=1 的时候(只保证写入 leader 成功),如果刚好 leader 挂了,则数据会丢失。
b、acks=0 的时候,使用异步模式的时候,该模式下 kafka 无法保证消息,有可能会丢。
2、brocker 如何保证不丢失
a、acks=all 所有副本都写入成功并确认。
b、retries=一个合理值 kafka 发送数据失败后的重试值。(如果总是失败,则可能是网络原因)
c、min.insync.replicas=2 消息至少要被写入到这么多副本才算成功。
d、unclean.leader.election.enable=false 关闭 unclean leader 选举,即不允许非 ISR 中的副本被选举为 leader,以避免数据丢失。
3、consumer 如何保证不丢失?
a、如果在消息处理完成前就提交了 offset,那么就有可能造成数据的丢失。
b、enable.auto.commit=false 关闭自动提交 offset。
c、处理完数据之后手动提交。
3、kafka 工作流程原理
大致原理即可。有几个点稍微详细即可。
4、kafka 保证消息顺序
1、全局顺序
a、全局使用一个生产者,一个分区,一个消费者。
2、局部顺序
a、每个分区是有序的,根据业务场景制定不同的 key 进入不同的分区。
5、zero copy 原理及如何使用?
- 1、zero copy 在内核层直接将文件内容传送给网络 socket,避免应用层数据拷贝,减小 IO 开销。
- 2、java.nio.channel.FileChannel 的 transferTo() 方法实现 zero copy。
6、spark Join 常见分类以及基本实现机制
1、shuffle hash join、broadcast hash join 以及 sort merge join。
2、shuffle hash join
小表 join 大表,依次读取小表的数据,对于每一行数据根据 join key 进行 hash,hash 到对应的 Bucket(桶),生成 hash table 中的一条记录。
数据缓存在内存中,如果内存放不下需要 dump 到外存。
再依次扫描大表的数据,使用相同的 hash 函数映射 Hash Table 中的记录,映射成功之后再检查 join 条件,如果匹配成功就可以将两者 join 在一起。
3、broadcast hash join
如果小表数据量增大,内存不能放下的时候,分别将两个表按照 join key 进行分区,将相同 join key 的记录重分布到同一节点,两张表的数据会被重分布到集群中所有节点。这个过程称为 shuffle(网络混启)。
每个分区节点上的数据单独执行单机 hash join 算法。
4、sort merge join
两张大表 join 采用了 sort merge join 算法:
shuffle 阶段:将两张大表根据 join key 进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理。
sort 阶段:对单个分区节点的两表数据,分别进行排序。
merge 阶段:对排好序的两张分区表数据执行 join 操作。join 操作很简单,分别遍历两个有序序列,碰到相同 join key 就 merge 输出,否则取更小一边。
128G 内存、多磁盘、万兆网卡、吞吐(几千到一万
--------------------------------------------------------------------------------------------------------------
flume三个器:监控器,拦截器,选择器
选择器:

Channel选择器是决定Source接收的一个特定事件写入哪些Channel的组件,它们告知Channel处理器,然后由其将事件写入到每个Channel。
Flume内置两种选择器:replicating和multiplexing。如果source的配置中没有指定选择器,那么会自动使用复制Channel选择器。
二、Replicationg Channel Selector
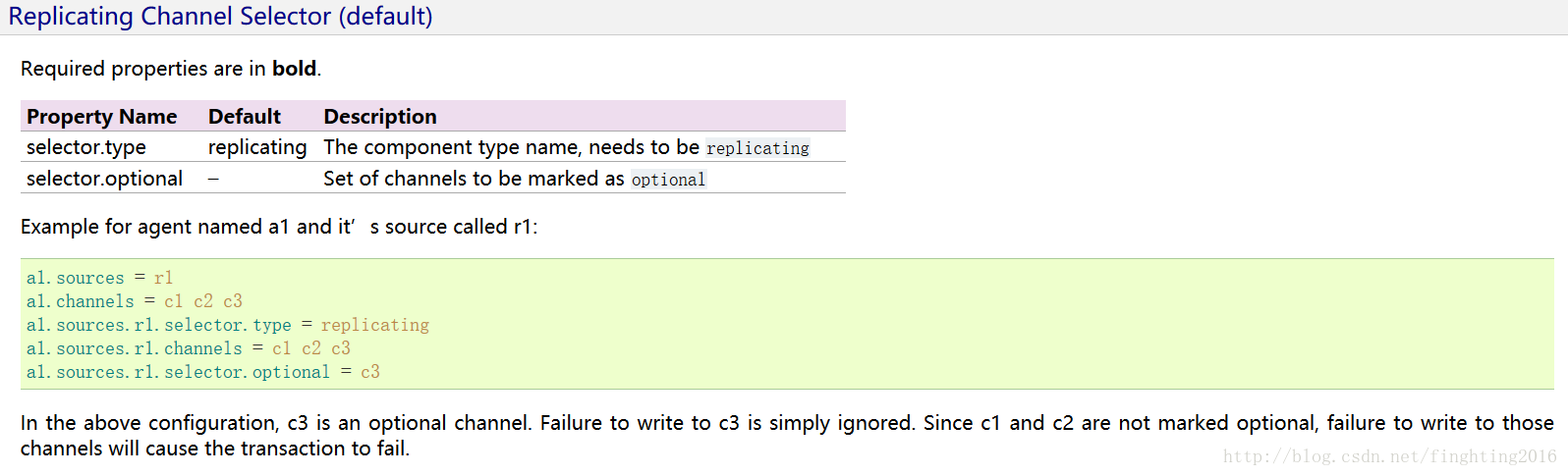
三、Multiplexing Channel Selector
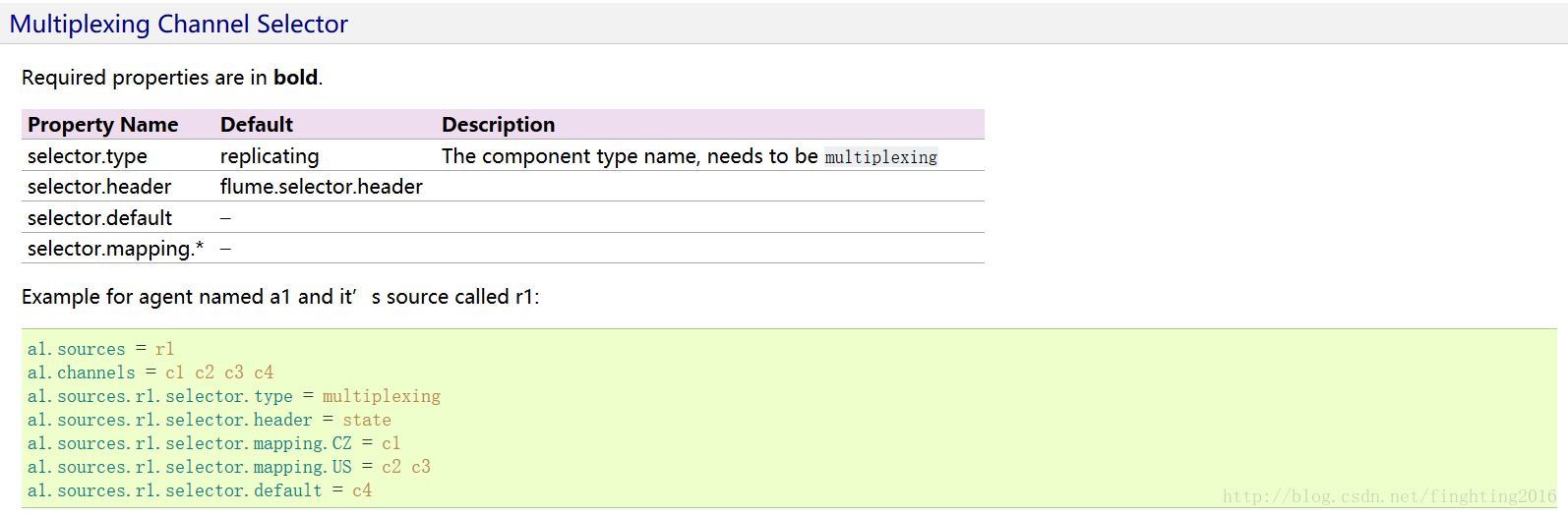
拦截器:
拦截器的种类介绍
1、Timestamp Interceptor(时间戳拦截器)
flume中一个最经常使用的拦截器 ,该拦截器的作用是将时间戳插入到flume的事件报头中。如果不使用任何拦截器,flume接受到的只有message。时间戳拦截器的配置。 参数 默认值 描述 type 类型名称timestamp,也可以使用类名的全路径 preserveExisting false 如果设置为true,若事件中报头已经存在,不会替换时间戳报头的值
source连接到时间戳拦截器的配置:
a1.sources.r1.interceptors = timestamp
a1.sources.r1.interceptors.timestamp.type=timestamp
a1.sources.r1.interceptors.timestamp.preserveExisting=false
2、Host Interceptor(主机拦截器)
主机拦截器插入服务器的ip地址或者主机名,agent将这些内容插入到事件的报头中。时间报头中的key使用hostHeader配置,默认是host。主机拦截器的配置参数 默认值 描述 type 类型名称host hostHeader host 事件投的key useIP true 如果设置为false,host键插入主机名 preserveExisting false 如果设置为true,若事件中报头已经存在,不会替换host报头的值
source连接到主机拦截器的配置:
a1.sources.r1.interceptors = host
a1.sources.r1.interceptors.host.type=host
a1.sources.r1.interceptors.host.useIP=false
a1.sources.r1.interceptors.timestamp.preserveExisting=true
3、静态拦截器(Static Interceptor)
静态拦截器的作用是将k/v插入到事件的报头中。配置如下参数 默认值 描述 type 类型名称static key key 事件头的key value value key对应的value值 preserveExisting true 如果设置为true,若事件中报头已经存在该key,不会替换value的值source连接到静态拦截器的配置:
a1.sources.r1.interceptors = static
a1.sources.r1.interceptors.static.type=static
a1.sources.r1.interceptors.static.key=logs
a1.sources.r1.interceptors.static.value=logFlume
a1.sources.r1.interceptors.static.preserveExisting=false
4、正则过滤拦截器(Regex Filtering Interceptor)
在日志采集的时候,可能有一些数据是我们不需要的,这样添加过滤拦截器,可以过滤掉不需要的日志,也可以根据需要收集满足正则条件的日志。参数默认值描述 type 类型名称REGEX_FILTER regex .* 匹配除“ ”之外的任何个字符 excludeEvents false 默认收集匹配到的事件。如果为true,则会删除匹配到的event,收集未匹配到的。
source连接到正则过滤拦截器的配置:
a1.sources.r1.interceptors = regex
a1.sources.r1.interceptors.regex.type=REGEX_FILTER
a1.sources.r1.interceptors.regex.regex=(rm)|(kill)
a1.sources.r1.interceptors.regex.excludeEvents=false
这样配置的拦截器就只会接收日志消息中带有rm 或者kill的日志。
5、Regex Extractor Interceptor
通过正则表达式来在header中添加指定的key,value则为正则匹配的部分
6、UUID Interceptor
用于在每个events header中生成一个UUID字符串,例如:b5755073-77a9-43c1-8fad-b7a586fc1b97。生成的UUID可以在sink中读取并使用。根据上面的source,拦截器的配置如下:
# source 拦截器
a1.sources.sources1.interceptors = i1
a1.sources.sources1.interceptors.i1.type = org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder
a1.sources.sources1.interceptors.i1.headerName = uuid
a1.sources.sources1.interceptors.i1.preserveExisting = true
a1.sources.sources1.interceptors.i1.prefix = UUID-
7、Morphline Interceptor
Morphline拦截器,该拦截器使用Morphline对每个events数据做相应的转换。关于Morphline的使用,可参考
http://kitesdk.org/docs/current/morphlines/morphlines-reference-guide.html
8、Search and Replace Interceptor
此拦截器基于Java正则表达式提供简单的基于字符串的搜索和替换功能。还可以进行回溯/群组捕捉。此拦截器使用与Java Matcher.replaceAll()方法中相同的规则
# 拦截器别名
a1.sources.avroSrc.interceptors = search-replace
# 拦截器类型,必须是search_replace
a1.sources.avroSrc.interceptors.search-replace.type = search_replace
#删除事件正文中的前导字母数字字符,根据正则匹配event内容
a1.sources.avroSrc.interceptors.search-replace.searchPattern = 快速褐色([az] +)跳过懒惰([az] +)
# 替换匹配到的event内容
a1.sources.avroSrc.interceptors.search-replace.replaceString = 饥饿的$ 2吃了不小心$ 1
# 设置字符集,默认是utf8
a1.sources.avroSrc.interceptors.search-replace.charset = utf8
自定义拦截器:
定义实现类MyInterceptor ,只需要实现Interceptor接口,定义内部类Builder实现Interceptor.Builder即可
监控器:
监控器可以看到:
source尝试写入channel中的event数量,成功写入且提交的event数量;
sink尝试从channel中拉取的event数量,成功读取的事件数量;
channel相关信息,例如:启动时间,停止时间,目前的event总数,容量,占用百分比