相关性算分
指文档与查询语句间的相关度,通过倒排索引可以获取与查询语句相匹配的文档列表
如何将最符合用户查询需求的文档放到前列呢?
本质问题是一个排序的问题,排序的依据是相关性算分,确定倒排索引哪个文档排在前面
影响相关度算分的参数:
A. TF(Term Frequency):词频,即单词在文档中出现的次数,词频越高,相关度越高,计算公式: tf(t in d) = √frequency
B. Document Frequency(DF):文档词频, 该词出现在多少篇文档中
C. IDF(Inverse Document Frequency):倒排文档频度,与文档词频相反,即 1/DF。即单词出现的文档数越少,相关度越高(如果一个单词在文档集出现越少,算为越重要单词),计算公式:idf(t) = 1 + log ( numDocs / (docFreq + 1))
D. Field-length Norm:字段长度归约, 字段有多长?字段越短,那么其权重就越高。如果一个词条出现在较短的字段,如 title 字段中,那么该字段的内容相比更长的body 字段而言,更有可能是关于该词条的,计算公式: norm(d) = 1 / √numTerms
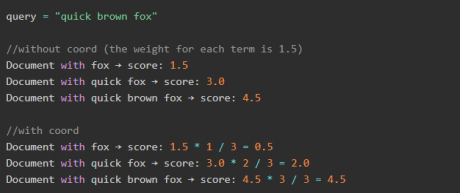
• TF/IDE 模型
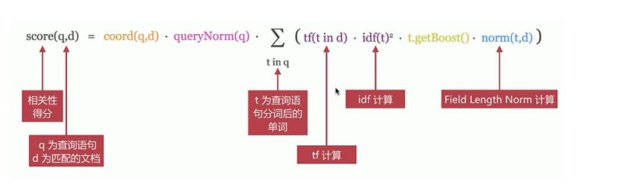
a) score(q, d),文档 d 与查询 q 的相关度分数(relevance score)
b) queryNorm(q),查询正则因子(query normalization factor)试图将查询正则化,以便可以比较两个不同 query 的结果
c) coord(q, d),协调因子(coordination factor)
d) tf(t in d),term t 在文档 d 中的词频
e) idf(t),term t 的逆向文档频率
f) t.getBoost(),查询中使用的自定义 boost,竞价排名用
g) norm(t, d),文档 d 的文本长度正则值
• BM25 模型(5.X 之后的默认模型)
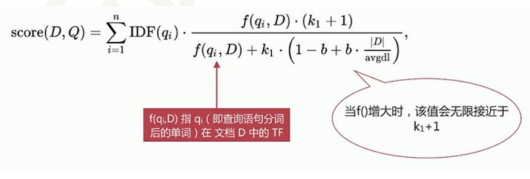
a) |D|:文档长度
b) avgdl:所有文档的平均文档长度
c) k1,b 是自由参数,lucene 默认 k1=1.2,b=0.75
d) IDF = log((#Docs - #DocsHit + 0.5)/(#DocsHit + 0.5))
e) TF = query count in one doc
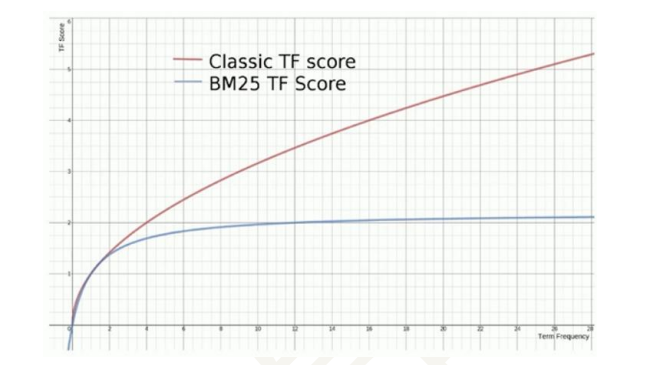
BM25 相比 TF/IDF 的一大优化是降低了 tf 在过大时的权重,避免词频对查询影响过大