1、Partitioner 组件通过让 Map 对 Key 进行分区,从而将不同分区的 Key 交由不同的 Reduce 处理。Partition属于map端
2、分区的总数与任务的reduce任务数相同
partitioner定义:
partitioner的作用是将mapper 输出的key/value拆分为分片(shard),每个reducer对应一个分片。
默认情况下,partitioner先计算key的散列值(hash值)。然后通过reducer个数执行取模运算:key.hashCode%(reducer个数)。这样能够随机地将整个key空间平均分发给每个reducer,同时也能确保不同mapper产生的相同key能被分发到同一个reducer。
以下图片截取自Hadoop权威指南(第三版)

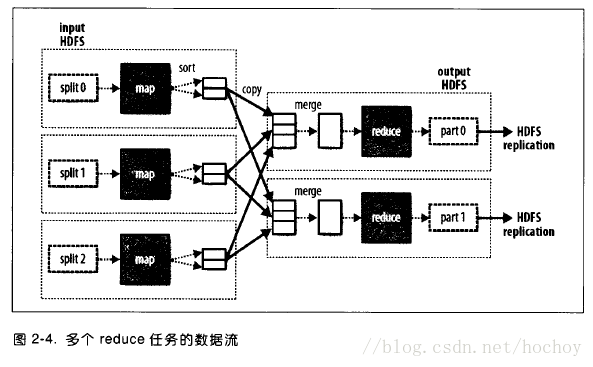

目的:
可以使用自定义Partitioner来达到reducer的负载均衡, 提高效率。
适用范围:
需要非常注意的是:必须提前知道有多少个分区。比如自定义Partitioner会返回4个不同int值,而reducer number设置了小于4,那就会报错。所以我们可以通过运行分析任务来确定分区数。
例如,有一堆包含时间戳的数据,但是不知道它能追朔到的时间范围,此时可以运行一个作业来计算出时间范围。
注意:
在自定义partitioner时一定要注意防止数据倾斜。
从以上源码我们可以看到Partitioner 抽象类由getPartition(KEY key, VALUE value, int numPartitions)方法组成,起三个参数分别为:(KEY key, VALUE value, int numPartitions)
一下大概对此方法做简要说明:
1)key、value分别指的是Mapper任务的输出
2)numReduceTasks指的是设置的Reducer任务数量,默认值是1,numReduceTasks指的是设置的Reducer任务数量,默认值是1
以下做一个简单的例子以供参考:
class ThePartitioner extends Partitioner<Text, Text> {
@Override
public int getPartition(Text key, Text value,
int numPartitions) {
Long l = Long.valueOf((key.hashCode() - Integer.MAX_VALUE) % numPartitions);
return Math.abs(Integer.parseInt(l.toString()));
}
}
————————————————
版权声明:本文为CSDN博主「hochoy」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hochoy/article/details/79633712