实验一、词法分析实验
商业软件工程 苏伟祥 201506110160
一、实验目的
编制一个此法分析程序
二、实验内容需求
输入源程序字符串
输出二元组(种别,单词本身)
待分析语言的词法规则
三、实验方法、步骤以及结果测试
1.源文件名:
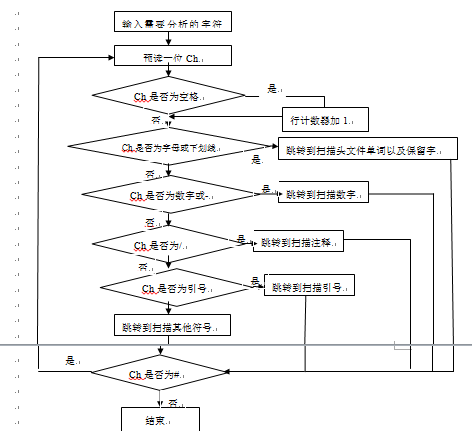
2.原理分析及流程图
3.主要程序及解释
do{ scanf("%c",&ch); prog[p++]=ch; }while(ch!='#'); p=0; printf("词法分析结果如下: "); do{ sum=0; for(m=0;m<8;m++) token[m++]= NULL; ch=prog[p++]; m=0; while((ch==' ')||(ch==' ')) ch=prog[p++]; if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))) { while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) { token[m++]=ch; ch=prog[p++]; } p--; syn=10; for(n=0;n<6;n++) if(strcmp(token,rwtab[n])==0) { syn=n+1; break; } } else if((ch>='0')&&(ch<='9')) { while((ch>='0')&&(ch<='9')) { sum=sum*10+ch-'0'; ch=prog[p++]; } p--; syn=11; } else { switch(ch) { case '<': token[m++]=ch; ch=prog[p++]; if(ch=='=') { syn=22; token[m++]=ch; } else { syn=20; p--; } break; case '>': token[m++]=ch; ch=prog[p++]; if(ch=='=') { syn=24; token[m++]=ch; } else { syn=23; p--; } break; case '+': token[m++]=ch; ch=prog[p++]; if(ch=='+') { syn=17; token[m++]=ch; } else { syn=13; p--; } break; case '-': token[m++]=ch; ch=prog[p++]; if(ch=='-') { syn=29; token[m++]=ch; } else { syn=14; p--; } break; case '!': ch=prog[p++]; if(ch=='=') { syn=21; token[m++]=ch; } else { syn=31; p--; } break; case '=': token[m++]=ch; ch=prog[p++]; if(ch=='=') { syn=25; token[m++]=ch; } else { syn=18; p--; } break; case '*': syn=15; token[m++]=ch; break; case '/': syn=16; token[m++]=ch; break; case '(': syn=27; token[m++]=ch; break; case ')': syn=28; token[m++]=ch; break; case '{': syn=5; token[m++]=ch; break; case '}': syn=6; token[m++]=ch; break; case ';': syn=26; token[m++]=ch; break; case '"': syn=30; token[m++]=ch; break; case '#': syn=0; token[m++]=ch; break; case ':': syn=17; token[m++]=ch; break; default: syn=-1; break; } token[m++]='�'; }
4.运行结果及分析
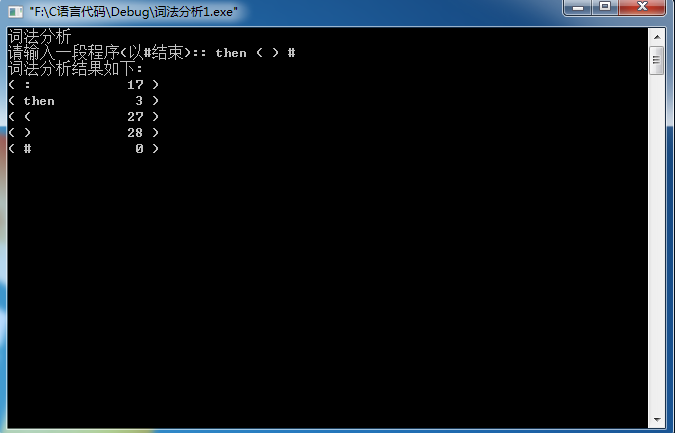
还是比较符合预期的,但是偶尔会出现意外情况 比如说输入x,输出的却是xf,种别码也不对。
原因可能是读取的时候出现了一些小错,但是检查很多遍后代码也没有错。
四、实验总结
通过此次实验,让我了解到如何设计、编制并调试词法分析程序,加深对词法分析原理的理解;熟悉了构造词法分析程序的手工方式的相关原理,使用某种高级语言直接编写此法分析程序。另外,也让我重新熟悉了C语言的相关内容,加深了对C语言的用途的理解。