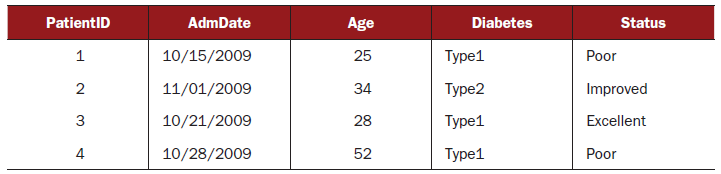
数据集通常是长方形数据矩阵,行代表一个观察值,列代表一个变量,下表提供了一个假想的病人数据集
不同的规则有不同的数据集行列名称。数据统计把它们成为一个观察值和变量,数据库分析员把它们成为一条记录和域,数据挖掘和机器学习把它们成为一个样例和属性。我们将会在本书中用一个观察值和变量这个术语。
你可以分清数据结构(本例中的长方形数组)和包含数据类型的数据内容。在上表所示的数据集中,PatientID是一个行,或者是一个标识符。AdmDate是一个日期变量,Age是一个连续型变量,Diabetes是一个记号变量,Status是一个序级变量。
R语言有很多结构来存储数据,包括标量,向量,数组,数据框架和线性表。上表在R语言里相当于一个数据框架。这个结构的差异给R语言在处理数据时提供了大量的灵活性。
R语言可以处理的数据类型或者模式,包含数字型,字符型,逻辑型(TRUE或FALSE),复数(虚数)和行(字节)。在R语言中,PatientID,AdmDate和Age是数字变量,反之,Diabetes和Status是字符型变量。另外你需要分别告诉R语言PatientID是一个主标识符,AdmDate包含日期,Diabetes和Status是一个名义和序级变量。
R语言把主标识符称作行名称,把分类变量(名义变量和序级变量)称作因素。我们会在下一个章节讲这些。你会在第三章学到日期变量。