事务
“要么全部成功,要么全部失败”
ACID
ACID嘛,原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)!
我们以从A账户转账50元到B账户为例进行说明一下ACID,四大特性。
原子性
根据定义,原子性是指一个事务是一个不可分割的工作单位,其中的操作要么都做,要么都不做。即要么转账成功,要么转账失败,是不存在中间的状态!
如果无法保证原子性会怎么样?
OK,就会出现数据不一致的情形,A账户减去50元,而B账户增加50元操作失败。系统将无故丢失50元~
隔离性
根据定义,隔离性是指多个事务并发执行的时候,事务内部的操作与其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
如果无法保证隔离性会怎么样?
OK,假设A账户有200元,B账户0元。A账户往B账户转账两次,金额为50元,分别在两个事务中执行。如果无法保证隔离性,会出现下面的情形
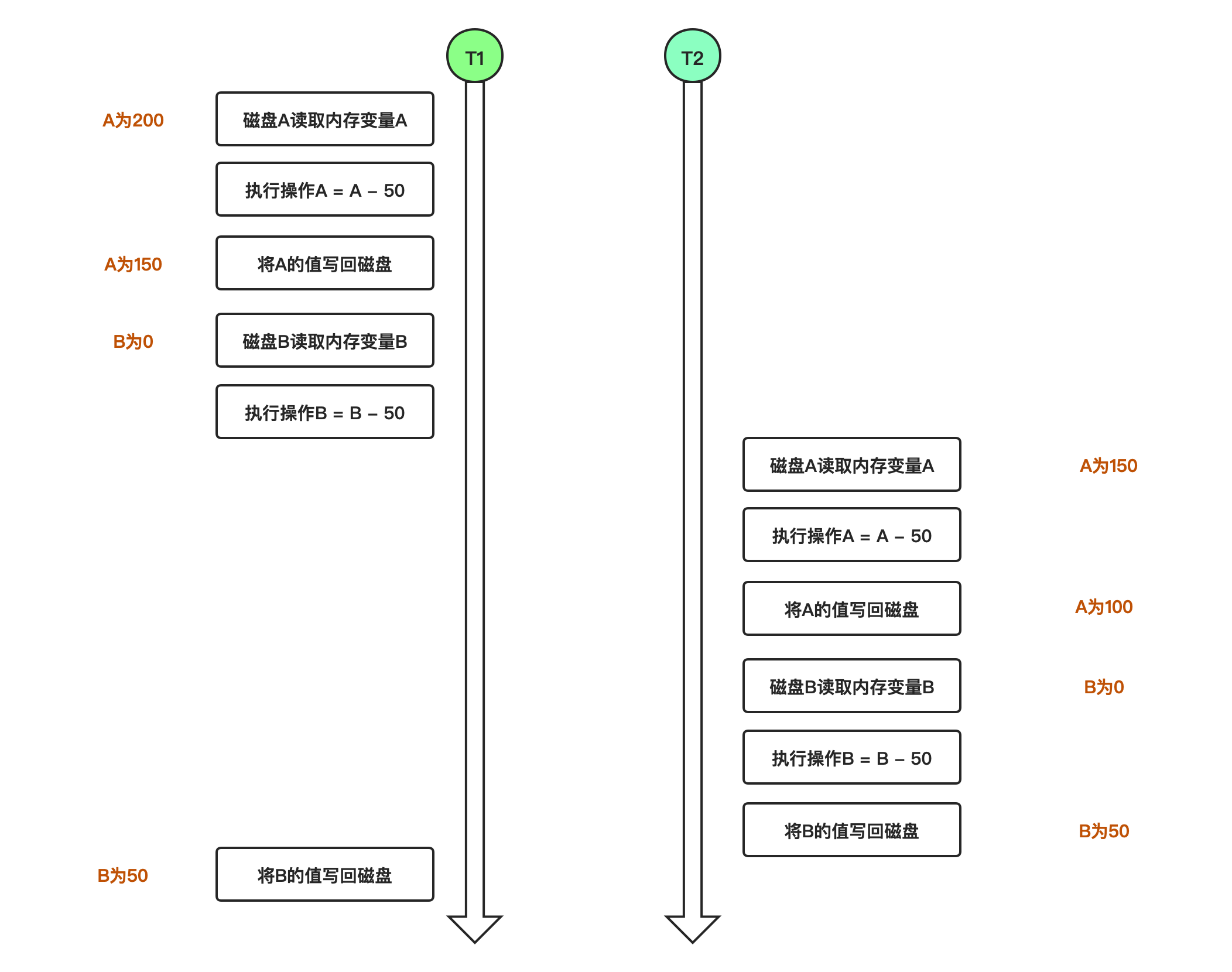
如图所示,如果不保证隔离性,A扣款两次,而B只加款一次,凭空消失了50元,依然出现了数据不一致的情形!
持久性
根据定义,持久性是指事务一旦提交,它对数据库的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
如果无法保证持久性会怎么样?
在MySQL中,为了解决CPU和磁盘速度不一致问题,MySQL是将磁盘上的数据加载到内存,对内存进行操作,然后再回写磁盘。好,假设此时宕机了,在内存中修改的数据全部丢失了,持久性就无法保证。
设想一下,系统提示你转账成功。但是你发现金额没有发生任何改变,此时数据出现了不合法的数据状态,我们将这种状态认为是数据不一致的情形。
一致性
根据定义,一致性是指事务执行前后,数据处于一种合法的状态,这种状态是语义上的而不是语法上的。 那什么是合法的数据状态呢? oK,这个状态是满足预定的约束就叫做合法的状态,再通俗一点,这状态是由你自己来定义的。满足这个状态,数据就是一致的,不满足这个状态,数据就是不一致的!
如果无法保证一致性会怎么样?
- 例一:A账户有200元,转账300元出去,此时A账户余额为-100元。你自然就发现了此时数据是不一致的,为什么呢?因为你定义了一个状态,余额这列必须大于0。
- 例二:A账户200元,转账50元给B账户,A账户的钱扣了,但是B账户因为各种意外,余额并没有增加。你也知道此时数据是不一致的,为什么呢?因为你定义了一个状态,要求A+B的余额必须不变。
mysql怎么保证一致性?
OK,这个问题分为两个层面来说。 从数据库层面,数据库通过原子性、隔离性、持久性来保证一致性。也就是说ACID四大特性之中,C(一致性)是目的,A(原子性)、I(隔离性)、D(持久性)是手段,是为了保证一致性,数据库提供的手段。数据库必须要实现AID三大特性,才有可能实现一致性。例如,原子性无法保证,显然一致性也无法保证。
但是,如果你在事务里故意写出违反约束的代码,一致性还是无法保证的。例如,你在转账的例子中,你的代码里故意不给B账户加钱,那一致性还是无法保证。因此,还必须从应用层角度考虑。
从应用层面,通过代码判断数据库数据是否有效,然后决定回滚还是提交数据!
mysql怎么保证原子性
OK,是利用Innodb的undo log。 undo log名为回滚日志,是实现原子性的关键,当事务回滚时能够撤销所有已经成功执行的sql语句,他需要记录你要回滚的相应日志信息。 例如
- (1)当你delete一条数据的时候,就需要记录这条数据的信息,回滚的时候,insert这条旧数据
- (2)当你update一条数据的时候,就需要记录之前的旧值,回滚的时候,根据旧值执行update操作
- (3)当年insert一条数据的时候,就需要这条记录的主键,回滚的时候,根据主键执行delete操作
undo log记录了这些回滚需要的信息,当事务执行失败或调用了rollback,导致事务需要回滚,便可以利用undo log中的信息将数据回滚到修改之前的样子。
mysql怎么保证持久性的
OK,是利用Innodb的redo log。 正如之前说的,Mysql是先把磁盘上的数据加载到内存中,在内存中对数据进行修改,再刷回磁盘上。如果此时突然宕机,内存中的数据就会丢失。 怎么解决这个问题? 简单啊,事务提交前直接把数据写入磁盘就行啊。 这么做有什么问题?
- 只修改一个页面里的一个字节,就要将整个页面刷入磁盘,太浪费资源了。毕竟一个页面16kb大小,你只改其中一点点东西,就要将16kb的内容刷入磁盘,听着也不合理。
- 毕竟一个事务里的SQL可能牵涉到多个数据页的修改,而这些数据页可能不是相邻的,也就是属于随机IO。显然操作随机IO,速度会比较慢。
于是,决定采用redo log解决上面的问题。当做数据修改的时候,不仅在内存中操作,还会在redo log中记录这次操作。当事务提交的时候,会将redo log日志进行刷盘(redo log一部分在内存中,一部分在磁盘上)。当数据库宕机重启的时候,会将redo log中的内容恢复到数据库中,再根据undo log和binlog内容决定回滚数据还是提交数据。
采用redo log的好处?
其实好处就是将redo log进行刷盘比对数据页刷盘效率高,具体表现如下
redo log体积小,毕竟只记录了哪一页修改了啥,因此体积小,刷盘快。redo log是一直往末尾进行追加,属于顺序IO。效率显然比随机IO来的快。
mysql怎么保证隔离性
利用的是锁和MVCC机制。
参考: https://dreamcater.gitee.io/javabooks/#/crazy/MySQL?id=mysql%e7%9a%84acid%e5%8e%9f%e7%90%86