为什么要监控kernel.pid_max呢?以下这个案例来解答这个问题
有台生产环境的服务器down了,ssh连接不上去。就在准备去重启该机器的时候,突然又可以ssh登录了。但是只有一个同事成功登录,其他人依然无法连接。在成功登录的同事终端上执行任何命令,都会报如下错误:
# free
-bash: fork: Cannot allocate memory
后来多试验几次,偶尔能执行成功:
# free
total used free shared buff/cache available
Mem: 7814784 340028 6688016 9488 786740 7244604
Swap: 2097148 0 2097148
可以看出memory还有很多,不可能是内存耗尽问题。
当时想不通是啥情况。 今天查询资料无意中发现:当环境中有过多process,超过pid max可能会导致这个报错。
1. 查询pid_max值并修改(原来值挺大,为了测试改小点)
# sysctl -w kernel.pid_max=500
kernel.pid_max = 500
64位系统上pid_max最大值为2^22,32位系统上最大值为32768
优化系统参数也只能临时解决一些问题,实际生产中开发和测试环境的机器会被很多开发和人员使用,会出现一些linux系统瓶颈问题。这个时候靠优化一些系统参数并不能解决问题,但是我们可以使用监控来提前发现可能出现的问题,然后提前登录机器释放出来一些资源使服务能够平稳运行
具体的监控步骤如下:
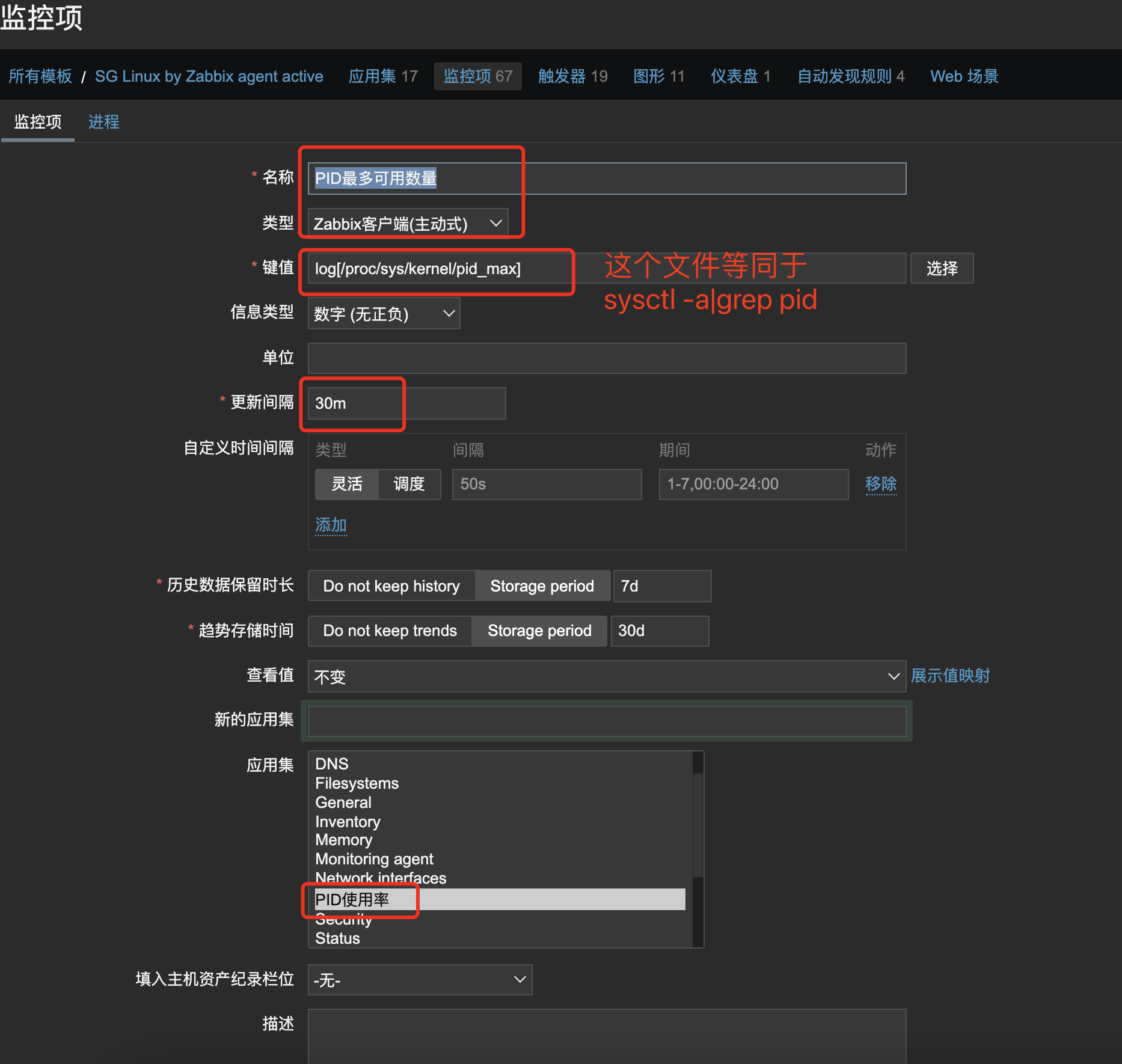
1、创建应用集:
再已有的模板中创建一个应用集《PID使用率》
2、创建监控项:
为了方便理解把kernel.pid_max的监控项拆分成了三个监控项《PID最多可用数量,PID当前已使用数量,PID当前使用率百分比》,为了方便管理将三个监控项都关联到应用集《PID使用率》
3:创建触发器: