1.前言
HBase是云计算环境下最重要的NOSQL数据库,提供了基于Hadoop的数据存储、索引、查询,其最大的优点就是可以通过硬件的扩展从而几乎无限的扩展其存储和检索能力。但是HBase与传统的基于SQL语言的关系数据库无论从理念还是使用方式上都相去甚远,以至于要将基于SQL的项目移植到HBase时往往需要重写整个项目。
为了解决这个问题,很多开源项目提供了HBase的类SQL中间件,意即提供一种在HBase上使用的类SQL语言,使得程序员能够像使用关系数据库一样使用HBase,Apache Phoenix就是其中的一个优秀项目。
本文介绍了如何将基于传统关系数据库的程序通过Apache Phoenix移植到基于HBase的云计算平台上的方法,并详细讲述了该过程中碰到的种种困难。主要内容包括:
HBase及云计算环境的安装配置;
HBase的Java API编程;
Phoenix的安装配置与使用;
Squirrel的安装配置与使用;
使用Phoenix移植SQL代码至HBase;
Phoenix性能调优;
本文的读者应该是数据库系统项目的开发人员和维护人员,云计算项目开发人员,最好具有以下基本知识:
Linux系统使用常识;
Hadoop、Hbase、Zookeeper等云计算环境使用常识;
Java编程开发基础;
SQL语言基础;
Oracle、SQLServer或Mysql等关系数据库使用管理基础;
2.HBase及云计算环境的安装配置
2.1环境配置
云计算环境通常安装在linux或者CentOS等类UNIX操作系统中,本文涉及的软件至少需要三个,即Hadoop、Hbase和Zookeeper,其版本号如下:
hadoop-2.3.0-cdh5.1.0
zookeeper-3.4.5-cdh5.1.0
hbase-0.98.1-cdh5.1.0
注意:本文使用了云时代的版本5.1.0,由于此类软件版本众多,互相之间的兼容性复杂,因此最好统一采用cdh的版本。系统配置如下图所示:
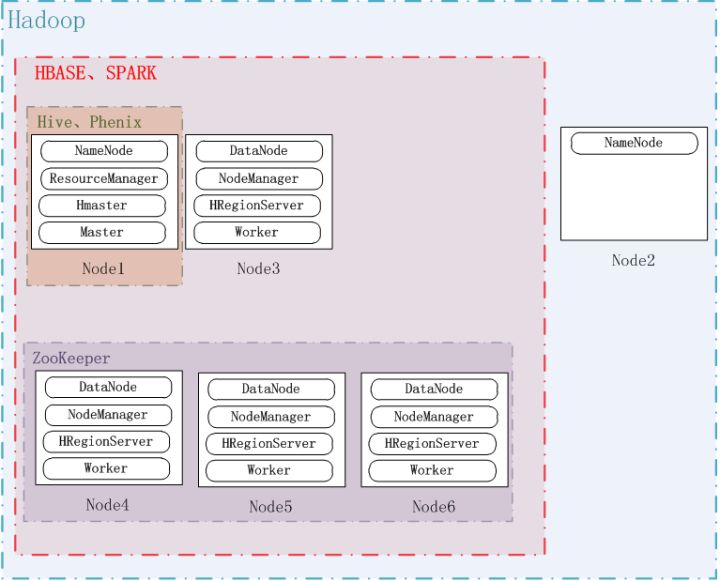
系统一共六个节点,即Node1Node6,hadoop安装在全部六个节点上,其中Node1和Node2是NameNode,其他是DataNode;ZooKeeper安装在Node4、Node5和Node6上,其端口使用默认的2181;Hbase安装在Node1、Node3Node6上,其中Node1是HMaster,其他是HRegionServer。具体参数配置可以参考其他文档,此处不做详细描述。
注意:客户端必须通过ZooKeeper找到Hbase的入口。对于客户来说,只需要知道ZooKeeper在哪儿;需要访问hbase时,客户端去找ZooKeeper,ZooKeeper再去查询HBase的HMaster和HRegionServer等信息,具体情况见《HBase实战》63页。
2.2HBase Shell使用
环境配置成功后,即可使用HBase Shell对HBase数据库进行操作,类似于Oracle提供的sqlplus。
登陆任意一个安装了HBase的服务器,输入:
hbase shell
list
即可列出该hbase中存储的所有表格。
创建一个名为test的表格,它带有一个名为cf的列族,并使用list来查看表格是否被创建,然后插入一些数据:
hbase(main):003:0> create 'test', 'cf'
0 row(s) in 1.2200 seconds
hbase(main):003:0> list
test
1 row(s) in 0.0550 seconds
hbase(main):004:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0560 seconds
hbase(main):005:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0370 seconds
hbase(main):006:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0450 seconds
使用scan来查看test表格中的内容:
hbase(main):007:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1288380727188, value=value1
row2 column=cf:b, timestamp=1288380738440, value=value2
row3 column=cf:c, timestamp=1288380747365, value=value3
3 row(s) in 0.0590 seconds
得到表中的一行数据:
hbase(main):008:0> get 'test', 'row1'
COLUMN CELL
cf:a timestamp=1288380727188, value=value1
1 row(s) in 0.0400 seconds
disable和drop一个表格:
hbase(main):012:0> disable 'test'
0 row(s) in 1.0930 seconds
hbase(main):013:0> drop 'test'
0 row(s) in 0.0770 seconds
退出shell:
hbase(main):014:0> exit
其他更多具体的命令请参看HBase的手册或者在线帮助。
3.HBase Java API 编程
使用HBase的Java API进行开发需要掌握HBase的基本理念,推荐阅读《HBase实战》一书。
在进行开发的操作系统(例如Windows、Linux或者CentOS)中解压hbase-0.98.1-cdh5.1.0.tar.gz,得到开发所依赖的所有jar包,位于hbase-0.98.1-cdh5.1.0/lib目录中。
在开发环境(例如Eclipse、NetBean或者Intellij)中建立工程,导入hbase-0.98.1-cdh5.1.0lib中的所有jar包。
3.1关于远程连接HBase
在给出源代码之前,先介绍一下远程连接HBase的问题。从Oracle时代过来的程序员,显然期望得到数据库服务器的ip、port和Service Name之类的信息。但是在连接HBase时,你需要的却是一个或多个ZooKeeper服务器的ip(或者hostname)和port,因为只有它才知晓整个HBase集群的元数据。
显然,使用hostname比使用ip要显得习惯更好,因为它带来了更大的可移植性,因此费一点笔墨讲讲linux和windows的hostname设置。
在linux下,hostname通过修改/etc/hosts文件来完成,在集群的每台服务器上加入如下内容:
192.168.1.101 Node1
192.168.1.102 Node2
192.168.1.103 Node3
192.168.1.104 Node4
192.168.1.105 Node5
192.168.1.106 Node6
在各自的/etc/sysconfig/network文件中,将“HOSTNAME=”修改为“HOSTNAME=Node?”(将Node?替换为本服务器的hostname)。
在Windows下(仅测试过Win7 64),修改Windows/System32/drivers/etc/hosts文件,加入:
192.168.1.101 Node1
192.168.1.102 Node2
192.168.1.103 Node3
192.168.1.104 Node4
192.168.1.105 Node5
192.168.1.106 Node6
(不同的windows平台hosts文件的位置可能不一样,建议装一个everything,桌面搜索速度极快)。
其实多种方法都可以连接到ZooKeeper,例如ip加端口:
public static String hbase_svr_ip = "192.168.1.104,
192.168.1.105, 192.168.1.106";
public static String hbase_svr_port =
"2181";
或者hostname加端口:
public static String hbase_svr_hostname = "Node4,Node5,Node6";
public static String hbase_svr_port =
"2181";
或者将端口直接写在ip后:
public static String hbase_svr_ip = "192.168.1.104:2181,
192.168.1.105:2181, 192.168.1.106:2181";
或者将端口直接写在hostname后:
public static String hbase_svr_hostname = "Node4:2181,Node5:2181,Node6:2181";
或者仅使用一个ZooKeeper服务器:
public static String hbase_svr_hostname = "Node4:2181";
具体使用哪种方法就看程序员自己的偏好,也存在某种方法在某些版本中可能无法连接的问题,本文中没有穷尽测试,但个人认为hostname加端口的方法可能比较稳妥。
3.2源代码
本篇给出了使用Java API操作HBase的源代码,注意要将这几行替换为实际的ZooKeeper服务器地址、hostname和端口号:
public static String hbase_svr_ip = "192.168.1.104,
192.168.1.105, 192.168.1.106";
public static String hbase_svr_port =
"2181";
public static String hbase_svr_hostname = "Node4,Node5,Node6";
代码功能包括:
远程连接Hbase数据库;
创建表;
扫描所有表;
插入数据;
扫描数据;
删除数据;
删除表。
package com.wxb;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
/**
-
@author wxb hbase的基本操作方法
*/
public class HBaseSample {
public static String hbase_svr_ip = "192.168.1.104, 192.168.1.105, 192.168.1.106";
public static String hbase_svr_port = "2181";
public static String hbase_svr_hostname = "Node4,Node5,Node6";
private HConnection connection = null;
Configuration config = null;/**
-
构造函数,构造一个HBaseSample对象,必须在最后调用close方法来关闭所有的连接,释放所有的资源
*/
public HBaseSample() {
config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", hbase_svr_hostname);
config.set("hbase.zookeeper.property.clientPort", hbase_svr_port);
// System.out.println(config.get("hbase.zookeeper.quorum"));
// System.out.println(config.get("hbase.zookeeper.property.clientPort"));try {
connection = HConnectionManager.createConnection(config);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
- 释放资源
*/
public void close() {
try {
if (null != connection) {
connection.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
- 创建表格
- @param tableName
- @param columnFarily
*/
public void createTable(final String tableName, String columnFarily) {
if (null != config) {
System.out.println("begin create table...");
HBaseAdmin admin = null;
try {
admin = new HBaseAdmin(config);
if (admin.tableExists(tableName)) {
System.out.println(tableName + " is already exist!");
} else {
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
tableDesc.addFamily(new HColumnDescriptor(columnFarily));
admin.createTable(tableDesc);
System.out.println(tableDesc.toString()
+ " has been created.");
}
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
} else {
System.out.println("hbase could not connected!");
}
}
/**
- 向指定表格中添加一行数据
- @param table
- @param key
- @param family
- @param col
- @param dataIn
- @return
*/
public boolean addOneRecord(String table, String key, String family,
String col, byte[] dataIn) {
if (null != connection) {
try {
HTableInterface tb = connection.getTable(table);
Put put = new Put(key.getBytes());
put.add(family.getBytes(), col.getBytes(), dataIn);
tb.put(put);
System.out.println("put data key = " + key);
return true;
} catch (IOException e) {
System.out.println("put data failed.");
return false;
}
} else {
System.out.println("hbase could not connected!");
return false;
}
}
/**
- 得到hbase中所有的表
- @return
*/
public ListgetAllTables() {
Listtables = null;
if (connection != null) {
try {
HTableDescriptor[] allTable = connection.listTables();
if (allTable.length > 0)
tables = new ArrayList();
for (HTableDescriptor hTableDescriptor : allTable) {
tables.add(hTableDescriptor.getNameAsString());
System.out.println(hTableDescriptor.getNameAsString());
}
} catch (IOException e) {
e.printStackTrace();
}
} else {
System.out.println("hbase could not connected!");
}
return tables;
}
public byte[] getValueWithKey(String tableName, String rowKey,
String family, String qualifier) {
byte[] rel = null;
if (null != connection) {
try {
HTableInterface table = connection.getTable(tableName);
Get get = new Get(rowKey.getBytes());
get.addColumn(Bytes.toBytes(family), Bytes.toBytes(qualifier));
Result result = table.get(get);
if (!result.isEmpty()) {
rel = result.getValue(Bytes.toBytes(family),
Bytes.toBytes(qualifier));
}
} catch (IOException e) {
e.printStackTrace();
}
} else {
System.out.println("hbase could not connected!");
}
return rel;
}/**
- 从表中删除一行
- @param tableName
- @param rowKey
*/
public void deleteWithKey(String tableName, String rowKey) {
if (null != connection) {
try {
HTableInterface table = connection.getTable(tableName);
Delete delete = new Delete(rowKey.getBytes());
table.delete(delete);
} catch (IOException e) {
e.printStackTrace();
}
} else {
System.out.println("hbase could not connected!");
}
}
/**
- 得到一个表中的所有元素
- @param tableName
*/
public void getAllData(String tableName) {
if (null != connection) {
try {
HTableInterface table = connection.getTable(tableName);
Scan scan = new Scan();
ResultScanner rs = table.getScanner(scan);
for (Result r : rs) {
Cell[] cells = r.rawCells();
System.out.println("This row have " + cells.length
+ " cells:");
for (Cell cell : cells) {
String row = Bytes.toString(CellUtil.cloneRow(cell));
String family = Bytes.toString(CellUtil
.cloneFamily(cell));
String qualifier = Bytes.toString(CellUtil
.cloneQualifier(cell));
String value = Bytes
.toString(CellUtil.cloneValue(cell));
System.out.println(String.format("%s:%s:%s:%s", row,
family, qualifier, value));
}
}
} catch (IOException e) {
e.printStackTrace();
}
} else {
System.out.println("hbase could not connected!");
}
}
public void deleteTable(String tableName) {
if (null != config) {
System.out.println("begin delete table...");
HBaseAdmin admin = null;
try {
admin = new HBaseAdmin(config);
if (!admin.tableExists(tableName)) {
System.out.println(tableName + " is not exist!");
} else {
admin.disableTable(tableName);
admin.deleteTable(tableName);
System.out.println(tableName + " has been deleted.");
}
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
} else {
System.out.println("hbase could not connected!");
}
}/**
-
@param args
*/
public static void main(String[] args) {
HBaseSample sample = new HBaseSample();
// 1.create table and insert data
sample.createTable("student", "fam1");
sample.addOneRecord("student", "id1", "fam1", "name", "Jack".getBytes());
sample.addOneRecord("student", "id1", "fam1", "address",
"HZ".getBytes());// 2.list table
sample.getAllTables();// 3.getValue
byte[] value = sample.getValueWithKey("student", "id1", "fam1",
"address");
System.out.println("value = " + Bytes.toString(value));// 4.addOneRecord and delete
// sample.addOneRecord("student", "id2", "fam1", "name", "wxb".getBytes());
// sample.addOneRecord("student", "id2", "fam1", "address",
// "here".getBytes());
// sample.deleteWithKey("student", "id2");// 5.scan table
sample.getAllData("student");// 6.delete table
// sample.deleteTable("student");sample.close();
}
}
-
- Phoenix的安装配置与使用
从上一章可以看出,HBase的基本理念和传统的关系数据库是截然不同的,为了使得熟悉SQL的程序员能够快速使用HBase,使用Apache Phoenix是比较好的办法。它提供了一组类似于SQL的语法,以及序列、索引、函数等工具,使得将SQL代码移植至HBase成为可能。
4.1 Phoenix安装
同其他分布式软件一样,Phoenix的安装也是较为复杂的,且要密切关注其版本兼容性,否则很可能无法正常运行。例如Phoenix4.x版本都有兼容HBase0.98的版本,但是经过两天的测试才发现不同的Phoenix版本对HBase0.98的小版本号的要求不同。
由于本文使用的是HBase0.98.1,因此只能使用Phoenix4.1.0版本。如果使用的Phoenix版本和HBase版本不兼容,会出现第一次能够连接HBase,但以后都连接失败的现象。
Phoenix的具体安装步骤如下:
第一步:将phoenix-4.1.0-bin.tar.gz拷贝到Node1(HBase的HMaster)的某路径下,解压缩,拷贝hadoop2/phoenix-4.1.0-server-hadoop2.jar到HBase的lib目录下。
第二步:然后用scp(关于scp和ssh的设置请参考网上的其他文章,假设用户名为hadoop)拷贝到各个regionserver的HBase的lib目录下:
scp phoenix-4.1.0-server-hadoop2.jar hadoop@Node3:/home/hadoop/hbase-0.98.1-cdh5.1.0/lib/
phoenix-core-4.6.0-HBase-0.98.jar
scp phoenix-4.1.0-server-hadoop2.jar hadoop@Node4:/home/hadoop/hbase-0.98.1-cdh5.1.0/lib/
phoenix-core-4.6.0-HBase-0.98.jar
scp phoenix-4.1.0-server-hadoop2.jar hadoop@Node5:/home/hadoop/hbase-0.98.1-cdh5.1.0/lib/
phoenix-core-4.6.0-HBase-0.98.jar
scp phoenix-4.1.0-server-hadoop2.jar hadoop@Node6:/home/hadoop/hbase-0.98.1-cdh5.1.0/lib/
phoenix-core-4.6.0-HBase-0.98.jar
第三步:在HMaster上重启hbase(即Node1);
第四步:将phoenix-4.1.0-client-hadoop2.jar加入客户端的CLASSPATH变量路径中,修改用户的.bash_profile文件,同时将此文件拷贝到hbase的lib目录下。
第五步:测试使用phoenix,输入命令:
sqlline.py Node4:2181
注意:后面的参数是ZooKeeper的服务器和端口。
出现以下显示则说明连接成功。
[hadoop@iips25 hadoop2]$bin/sqlline.py Node1:2181
Setting property: [isolation, TRANSACTION_READ_COMMITTED]
issuing: !connect jdbc:phoenix:Node4 none none org.apache.phoenix.jdbc.PhoenixDriver
Connecting to jdbc:phoenix:Node4
16/06/21 08:04:24 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-phoenix.properties,hadoop-metrics2.properties
Connected to: Phoenix (version 4.1)
Driver: org.apache.phoenix.jdbc.PhoenixDriver (version 4.1)
Autocommit status: true
Transaction isolation: TRANSACTION_READ_COMMITTED
Building list of tables and columns for tab-completion (set fastconnect to true to skip)...
59/59 (100%) Done
Done
sqlline version 1.1.2
0: jdbc:phoenix:Node4>
查看数据库表:(注意,phoenix只能看到自己创建的表,不能看到HBase创建的表)
0: jdbc:phoenix:Node4> !tables
+------------+-------------+------------+------------+------------+------------+---------------------------+----------------+-------------+----------------+--------+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL_NAME | REF_GENERATION | INDEX_STATE | IMMUTABLE_ROWS | SALT_B |
+------------+-------------+------------+------------+------------+------------+---------------------------+----------------+-------------+----------------+--------+
| null | SYSTEM | CATALOG | SYSTEM TABLE | null | null | null | null | null | false | null |
| null | SYSTEM | SEQUENCE | SYSTEM TABLE | null | null | null | null | null | false | null |
+------------+-------------+------------+------------+------------+------------+---------------------------+----------------+-------------+----------------+--------+
0: jdbc:phoenix:Node4>
创建表,并插入数据:
0: jdbc:phoenix:Node4> create table abc(a integer primary key, b integer) ;
No rows affected (1.133 seconds)
0: jdbc:phoenix:Node4> UPSERT INTO abc VALUES (1, 1);
1 row affected (0.064 seconds)
0: jdbc:phoenix:Node4> UPSERT INTO abc VALUES (2, 2);
1 row affected (0.009 seconds)
0: jdbc:phoenix:Node4> UPSERT INTO abc VALUES (3, 12);
1 row affected (0.009 seconds)
0: jdbc:phoenix:Node4> select * from abc;
+------------+------------+
| A | B |
+------------+------------+
| 1 | 1 |
| 2 | 2 |
| 3 | 12 |
+------------+------------+
3 rows selected (0.082 seconds)
0: jdbc:phoenix:Node4>
创建包含中文的表(注意中文要使用VARCHAR):
create table user ( id integer primary key, name VARCHAR);
upsert into user values ( 2, '测试员2');
upsert into user values ( 1, '测试员1');
select * from user;
+------------+------------+
| ID | NAME |
+------------+------------+
| 1 | 测试员1 |
| 2 | 测试员2 |
4.2 phoenix配置
在hbase集群每个服务器的hbase-site.xml配置文件中,加入:
4.3 phoenix语法简介
phoenix的语法可参考其官方网站,也可下载其“Grammar _ Apache Phoenix.html”网页。
访问Phoenix时,可以使用其提供的sqlline.py命令,也可以使用下一章介绍的数据库图形界面工具Squirrel,当然也可以通过Phoenix提供的Java API。
4.3.1. 创建表
注意:Phoenix中的表必须有主键,这一点和许多关系数据库不同。因为主键是后续很多表操作的必备因素。
CREATE TABLE IF NOT EXISTS MYTABLE (ID INTEGER PRIMARY KEY, NAME VARCHAR, SEX VARCHAR, ADDRESS VARCHAR);
4.3.2. 删除表
DROP TABLE IF EXISTS MYTABLE;
4.3.3. 插入数据
UPSERT INTO MYTABLE VALUES (1, 'WXB', 'MALE', '010-22222222');
注意phoenix使用UPSERT而不是INSERT。
4.3.4. 删除数据
DELETE FROM MYTABLE WHERE ID = 1;
4.3.5. 查询数据
SELECT * FROM MYTABLE WHERE ID=1;
4.3.6. 修改数据
UPSERT INTO MYTABLE VALUES (1, 'WXB', 'MALE', '010-22222222');
可以看到,修改数据与插入数据一样,都是使用UPSERT语句,若此主键对应的行不存在,就插入,否则就修改。这也是为什么Phoenix的表必须有主键的原因之一。
4.3.7. 创建序列
Phoenix的序列与Oracle很像,也是先创建,然后调用next得到下一个值。也可以继续调用current value得到当前序列值,没有调用next时,不能使用current value。
创建一个序列:
CREATE SEQUENCE IF NOT EXISTS WXB_SEQ START WITH 1000 INCREMENT BY 1 MINVALUE 1000 MAXVALUE 999999999 CYCLE CACHE 30;
其含义基本上与Oracle类似。
4.3.8. 使用序列
序列只能在Select或者Upsert语句中使用,例如在Upsert中使用:
UPSERT INTO MYTABLE VALUES (NEXT VALUE FOR WXB_SEQ, 'WXB', 'MALE', '010-22222222');
读取序列的当前值时,采用这个语句:
SELECT CURRENT VALUE FOR WXB_SEQ DUALID FROM WXB_DUAL;
然后读取DUALID就可得到序列的当前值。
这里的WXB_DUAL是我自己创建的一个特殊表,用来模拟Oracle中的Dual表。
CREATE TABLE IF NOT EXISTS WXB_DUAL (DUALID INTEGER PRIMARY KEY );
UPSERT INTO WXB_DUAL VALUES (1);
4.3.9. 删除序列
DROP SEQUENCE IF EXISTS WXB_SEQ;
本章至此为止,详细的操作留待后续再讲。
- 安装SQuirrel
Squirrel是一个图形化的数据库工具,它可以将Phoenix以图形化的方式展示出来,它可以安装在windows或linux系统中。
5.1 安装步骤
第一步:
设置好JDK,JAVA_HOME,CLASSPATH等一系列的环境变量,注意无论是在windows还是在linux下,都需要上面安装的hbase和phoenix的存放jar包的目录,并将其设置到CLASSPATH中。windows下的CLASSPATH如下:
%JAVA_HOME%lib;%JAVA_HOME%libdt.jar;%JAVA_HOME%lib ools.jar;D:hbase-0.98.1-cdh5.1.0lib;D:phoenix-4.1.0-binhadoop2
linux的CLASSPATH如下:
export PHOENIX_HOME=/home/hadoop/phoenix-4.1.0-bin
export CLASSPATH=$PHOENIX_HOME/hadoop2/phoenix-4.1.0-client-hadoop2.jar:$HBASE_HOME/lib/:$CLASSPATH
export PATH=$PHOENIX_HOME/bin:$PATH
第二步:
下载解压squirrel-sql-snapshot-20160613_2107-standard.jar(最新版本的squirrel安装包),在命令行中运行java -jar squirrel-sql-snapshot-20160613_2107-standard.jar开始安装。
第三步:执行如下安装
- Remove prior phoenix-[oldversion]-client.jar from the lib directory of SQuirrel, copy phoenix-[newversion]-client.jar to the lib directory (newversion should be compatible with the version of the phoenix server jar used with your HBase installation)
- Start SQuirrel and add new driver to SQuirrel (Drivers -> New Driver)
- In Add Driver dialog box, set Name to Phoenix, and set the Example URL to jdbc:phoenix:localhost.
- Type “org.apache.phoenix.jdbc.PhoenixDriver” into the Class Name textbox and click OK to close this dialog.
- Switch to Alias tab and create the new Alias (Aliases -> New Aliases)
- In the dialog box, Name:Any name, Driver: Phoenix, User Name:Anything, Password:Anything
- Construct URL as follows: jdbc:phoenix:zookeeper quorum server. For example, to connect to a local HBase use: jdbc:phoenix:localhost
- Press Test (which should succeed if everything is setup correctly) and press OK to close.
- Now double click on your newly created Phoenix alias and click Connect. Now you are ready to run SQL queries against Phoenix.
注意,我们连接的URL是jdbc:phoenix:Node4,用户名和密码随意即可。连接成功后,如下:
5.2 使用
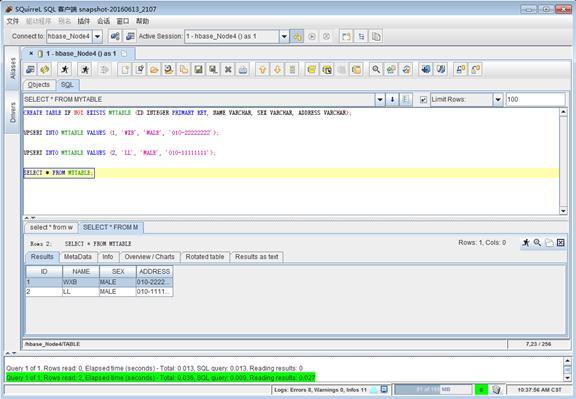
安装完毕后,就可以在Squirrel中执行各种phoenix支持的类SQL语句和观察数据了,例如在SQL栏中输入如下语句:
CREATE TABLE IF NOT EXISTS MYTABLE (ID INTEGER PRIMARY KEY, NAME VARCHAR, SEX VARCHAR, ADDRESS VARCHAR);
UPSERT INTO MYTABLE VALUES (1, 'WXB', 'MALE', '010-22222222');
UPSERT INTO MYTABLE VALUES (2, ‘LL’, 'MALE', '010-11111111');
SELECT * FROM MYTABLE;
结果如下:
使用Squirrel的好处在于可以方便的查看数据库中的各种对象,以及编辑和执行复杂的phoenix类sql脚本。
- 使用Phoenix移植SQL代码至HBase
Phoenix提供了完全适配JDBC的API,程序员可以像操作关系数据库(例如Oracle)一样来使用JDBC来操作Phoenix,这也是Phoenix的最大的优势所在。唯一需要注意的是,提交的SQL语句必须符合Phoenix语法,虽然此语法很类似于SQL,但还是有许多不同之处。
6.1 Phoenix Java Coding
本章给出了一个最基本的Phoenix JDBC源代码实例,注意其中所引用的所有类几乎都来自于java.sql.*包,与Oracle唯一的不同是其driver的字符串,该字符串等于前面连接Squirrel的连接字符串,你可以在Squirrel上测试driver字符串是否能够正确连接。driver字符串一般为jdbc:phoenix:ZooKeeper_hostname:port,例如jdbc:phoenix:Node4,Node5,Node6:2181。但是在端口为默认2181端口时,也可以省略端口号。
编码之前将phoenix-4.1.0-client-hadoop2.jar加入java项目的依赖Libraries,例子代码如下:
package com.wxb;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
/**
- @author wxb Phoenix的基本操作方法
*/
public class PhoenixSample {
public static String hbase_svr_ip = "192.168.1.104, 192.168.1.105, 192.168.1.106";
public static String hbase_svr_port = "2181";
public static String hbase_svr_hostname = "Node4,Node5,Node6";
/*
* 所有几种方式的driver都能够通过测试: 1.Node4 2.Node4,Node5,Node6 3.Node4:2181
* 4.Node4,Node5,Node6:2181 5.Node4:2181,Node5:2181,Node6:2181
* 6.101.60.27.114
*/
public static String driver = "jdbc:phoenix:" + hbase_svr_hostname;
public static void createTable(String tableName) {
System.out.println("create table " + tableName);
Statement stmt = null;
try {
Connection con = DriverManager.getConnection(driver);
stmt = con.createStatement();
stmt.executeUpdate("create table if not exists " + tableName
+ " (mykey integer not null primary key, mycolumn varchar)");
con.commit();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void addRecord(String tableName, String values) {
Statement stmt = null;
try {
Connection con = DriverManager.getConnection(driver);
stmt = con.createStatement();
stmt.executeUpdate("upsert into " + tableName + " values ("
+ values + ")");
con.commit();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void deleteRecord(String tableName, String whereClause) {
Statement stmt = null;
try {
Connection con = DriverManager.getConnection(driver);
stmt = con.createStatement();
stmt.executeUpdate("delete from " + tableName + " where "
+ whereClause);
con.commit();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void createSequence(String seqName) {
System.out.println("Create Sequence :" + seqName);
Statement stmt = null;
try {
Connection con = DriverManager.getConnection(driver);
stmt = con.createStatement();
stmt.executeUpdate("CREATE SEQUENCE IF NOT EXISTS "
+ seqName
+ " START WITH 1000 INCREMENT BY 1 MINVALUE 1000 MAXVALUE 999999999 CYCLE CACHE 30");
con.commit();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void dropSequence(String seqName) {
System.out.println("drop Sequence :" + seqName);
Statement stmt = null;
try {
Connection con = DriverManager.getConnection(driver);
stmt = con.createStatement();
stmt.executeUpdate("DROP SEQUENCE IF EXISTS " + seqName);
con.commit();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void getAllData(String tableName) {
System.out.println("Get all data from :" + tableName);
ResultSet rset = null;
try {
Connection con = DriverManager.getConnection(driver);
PreparedStatement statement = con.prepareStatement("select * from "
+ tableName);
rset = statement.executeQuery();
while (rset.next()) {
System.out.print(rset.getInt("mykey"));
System.out.println(" " + rset.getString("mycolumn"));
}
statement.close();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void dropTable(String tableName) {
Statement stmt = null;
try {
Connection con = DriverManager.getConnection(driver);
stmt = con.createStatement();
stmt.executeUpdate("drop table if exists " + tableName);
con.commit();
con.close();
System.out.println("drop table " + tableName);
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
createTable("wxb_test");
createSequence("WXB_SEQ_ID");
// 使用了Sequence
addRecord("wxb_test", "NEXT VALUE FOR WXB_SEQ_ID,'wxb'");
addRecord("wxb_test", "NEXT VALUE FOR WXB_SEQ_ID,'wjw'");
addRecord("wxb_test", "NEXT VALUE FOR WXB_SEQ_ID,'wjl'");
// deleteRecord("wxb_test", " mykey = 1 ");
getAllData("wxb_test");
// dropTable("wxb_test");
// dropSequence("WXB_SEQ_ID");
}
}
6.2 每个表必须包含一个主键
在使用Phoenix时,建立的每个表都必须包含一个主键,这与关系数据库不同。而且每个表的主键会自动被索引,这意味着在select语句的where子句中使用主键作为条件,会得到最快的查询速度。关于索引,在后续章节中再详细介绍。
我的建议是,为每个表创建一个序列,并在插入数据时以序列的值作为主键的值。
6.3 JDBC连接池
Phoenix支持用户自己创建JDBC连接池,可以将基于JDBC连接池的代码复制过来,把Driver部分修改一番即可。
6.4 中文支持
涉及中文的字段可设置为VARCHAR类型,经测试没有问题。
6.5 CLOB和BLOB
CLOB和BLOB字段我都设置为VARCHAR类型,经测试存储400k字节的数据没有问题,更多的没有测试。
6.6 复杂的SQL语句
因为本文使用的Phoenix版本不是最新版,因此官网上给出的SQL语法不是完全都能够支持,例如下面的语句就不能支持:
delete from wxb_senword where swid in (select swid from wxb_rela_sw_group where groupid=1)
因此对于一些复杂的SQL语句,需要先到官网上查询语法,然后在phoenix中进行测试,测试通过后才能够在程序中使用。
两个表的关联查询是可行的,语句如下:
SELECT d.swid,d.swname, d.userid, e.groupid FROM wxb_senword d JOIN wxb_rela_sw_group e ON e.swid = d.swid where e.groupid=1;
7. Phoenix性能调优
7.1 代码移植流程
将基于SQL的java代码移植到Phoenix其实不难,以Oracle为例,基本流程如下:
将Oracle中的所有表在Phoenix中重新建立一次,没有主键的自己加一个主键(并建立对应的序列);
将Oracle中所有的序列、视图都在Phoenix中重新建立一次;
将程序中的每条SQL语句都翻译为Phoenix的SQL语句,并测试该语句是否能够正确运行,若不能,总能找到几条简单的语句进行替代。
7.2 Oracle和HBase的性能差异
移植完成后,经过一系列debug,程序总算能够正常运行了。但是性能问题会变得非常严重,这是关系数据库和HBase之间的设计思路和应用问题域之间的差异造成的。
Oracle的设计思路是尽可能的快速对数据进行操作,但是随着表中记录数的不断增加,查询性能持续下降。要对Oracle进行硬件扩充会比较困难,而且会在单表一亿条左右时(没有经过本人验证)碰到性能瓶颈。Oracle的优势是在表中记录数不多(几百万以内,具体看服务器性能)时拥有极高的查询速度。
而HBase的优势是让单表可以存储几乎无限的记录,并且可以方便的扩充硬件,使得查询速度可以达到一个稳定的标准。但是其缺点在于表中数据不多时,查询速度相对较慢。经测试,Phoenix的表在记录数很少时(数十条),查询单条数据也需要0.2秒左右(服务器集群配置见前面的章节),而同时单服务器的Oracle查询这样的数据仅需30ms左右,相差接近十倍。
7.3 Phoenix索引性能测试
与Oracle相比,Phoenix在性能上还有一个特点就是在没有索引的情况下,查询性能下降很快。
例如下表:
CREATE TABLE IF NOT EXISTS WXB_WORD (ID INTEGER PRIMARY KEY, NAME VARCHAR, VALUE DOUBLE, HEAT INTEGER, FOCUSLEVEL INTEGER, USERID INTEGER);
不建立索引的情况下,在前面介绍的集群上进行查询性能测试,查询语句如下(确保单条命中):
SELECT * FROM WXB_WORD WHERE NAME=’XXX’;
50万条记录,平均单条查询时间为0.38秒;
100万条记录,平均单条查询时间为0.79秒;
500万条记录,平均单条查询时间为4.31秒;
然而在NAME字段上建立索引后,将表中数据增加到1亿条,平均单条查询时间为0.164秒,可见索引对Phoenix性能的提升作用是无可替代的。
7.4 Phoenix索引简介
Phoenix中的索引被称之为Secondary Indexing(二级索引),这是为了和HBase主键上的索引区分开。在HBase中,每个表有且仅有一个主键的索引,该索引按照字典序进行排序;所有不基于主键的查询都会导致全表扫描,效率非常低下。在Phoenix中,可以对表中的任何一个字段或者几个字段建立二级索引,该索引实际上是一个独立的表,表中包含了被索引的列以及建立索引时包含的列(在索引的include语句中包含的列)。当用户对表进行查询时,会首先对索引进行查询,若能够得到全部的结果,则会直接返回,否则就到原表中进行查询。
注意,Phoenix的每个表都可以建立多个索引,索引和原表之间的同步由Phoenix保证。但是,索引越多,写入效率越低。
Phoenix支持两种类型的索引:可变索引(mutable indexing)和不可变索引(immutable indexing)。在表中数据需要变化时,使用可变索引;当应用场景为“一次写入,只会追加,永不改变”时使用不可变索引。本文中只使用了可变索引。
7.5 建立索引的方法与语句
在建立索引之前,再次检查Phoenix的配置,在HBase集群的每个服务器的hbase-site.xml配置文件中,加入:
create index if not exists idx_wxb_word on wxb_word (name desc) include (value) ;
那么这种语句就查询得特别快:
select name,value from wxb_word where name='AHNHLYPKGYAR_59999';
但是如果查询语句中还需要知道其他字段的值,例如:
select name,value,userid from wxb_word where name='AHNHLYPKGYAR_59999';
那么,就和没有索引差不多,因为该索引中没有包含userid这个字段。
另外需要注意的是:主键不需要索引,查询也非常快,这是由HBASE的特性保证的。
删除索引语句:
drop index if exists idx_wxb_word on wxb_word;
8. 总结
使用Phoenix将SQL代码移植到HBase应注意以下几个问题。
第一,应用场景是否合适?是否需要在单表中存储几乎无限的数据,并保证一定的查询性能?在数据量较少的情景下,Phoenix反而比Oracle的性能差。若要追求最高的性能,可以考虑同时使用关系数据库和HBase,并自己保证这部分数据的同步。
第二,Phoenix、HBase、Hadoop、ZooKeeper的版本兼容问题。在大部分情况下,开发人员并不能决定HBase、Hadoop和ZooKeeper的版本,因此只能寻找合适的Phoenix版本来适配它们,这将导致你不能使用最新的Phoenix版本。如同本文中写的一样,这种情况会导致一些Phoenix SQL语句的特性得不到支持。
第三,注意Phoenix的每个表必须包含一个主键(其实就是HBase的Primary rowkey),且该主键自带索引,合理设计这个主键能够带来性能上的提升和查询的便利。作为从SQL时代过来的程序员,抛弃节约空间的想法;在大数据时代,就是尽可能的用空间换时间。举个例子,你甚至可以将所有字段以一定的顺序和分隔符全部堆到主键上。
第四,移植代码时,将所有SQL语句一一翻译为对应的Phoenix语句即可。注意参考Phoenix主页上的语法介绍,并一一进行测试。Phoenix对JDBC的支持很好,诸如连接池一类的特性可以原封不动的照搬。但若原来的程序使用了针对SQL语句的中间件之类的技术,请恕我也不知如何处理。
第五,一定要对Phoenix的表建立二级索引,索引中尽可能包含所有需要查询的字段。索引会导致数据插入速度变慢,但会带来巨大的性能提升。