collections模块-数据类型扩展模块
''' 在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。 1.namedtuple: 生成可以使用名字来访问元素内容的tuple 2.deque: 双端队列,可以快速的从另外一侧追加和推出对象 3.Counter: 计数器,主要用来计数 4.OrderedDict: 有序字典 5.defaultdict: 带有默认值的字典 '''
namedtuple 具名元组


from collections import namedtuple point = namedtuple('坐标点', ['x', 'y']) p = point(1.0, 10.2) print(p) # 坐标点(x=1.0, y=10.2) print(p.x) print(p.y) # 1.0 # 10.2 def namedtuple_code(): from collections import namedtuple # 第一个是类名,第二个是类的各个字段的名字。后者可以是由数个字符串组成的可迭代对象,或者是由空格分隔开的字段名组成的字符串 # name_list = ['name', 'country', 'population', 'area'] # City = namedtuple('City', name_list) City = namedtuple('City', 'name country population area') # # 注意:元素的个数必须跟namedtuple第二个参数里面的值对应元素的数量一致 shanghai = City('shanghai', 'China', 24240000, '华东') beijing = City('beijing', 'China', 21540000, '华北') print(shanghai) print(shanghai.name, shanghai.country, shanghai.population, shanghai.area) print(shanghai[0], shanghai[1], shanghai[2], shanghai[3]) # 可以直接用 .名字 取值,也可以直接用索引取值 # City(name='shanghai', country='China', population=24240000, area='华东') # shanghai China 24240000 华东 # shanghai China 24240000 华东 print(beijing) print(beijing.name, beijing.country, beijing.population, beijing.area) # City(name='beijing', country='China', population=21540000, area='华北') # beijing China 21540000 华北 target_city = [] target_city.append(shanghai) target_city.append(beijing) print(target_city) # [City(name='shanghai', country='China', population=24240000, area='华东'), City(name='beijing', country='China', population=21540000, area='华北')]
deque 双端队列(FIFO: first in first out)
# 特殊点,双端队列可以根据索引在任意位置插值(队列不应该支持任意位置插值,只能在首尾插值) # 使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。 # deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈
from collections import deque q = deque(['a', 'b', 'c']) q.append(1) # 尾部添加 q.appendleft(2) # 开头添加 print(q) print(q.pop(), q.popleft()) # 尾部出队, 头部出队 print(q) # deque([2, 'a', 'b', 'c', 1]) # 1 2 # deque(['a', 'b', 'c']) q.insert(1, '哈哈哈') print(q) # deque(['a', '哈哈哈', 'b', 'c'])
扩展:queue队列模块
import queue ''' put 往队列添加值 get 从队列取值 ''' q = queue.Queue() # 生成队列对象 print(q) # <queue.Queue object at 0x000002D69AF45198> q.put('first') # 往队列里添值 q.put('second') q.put('third') print(q.get()) # 从队列取值 print(q.get()) print(q.get()) # print(q.get()) # 如果队列中的值取完了,程序会在原地等待,直到从队列中拿到值才停止 # first # second # third # ---原地等待----
OrderedDict 有序字典
# 跟普通的字典的区别是有序无序(插入顺序) # OrderedDict的Key会按照插入的顺序排列 # 备注:python3.6以后,默认字典的Key也会按照插入的顺序排列 from collections import OrderedDict ordered_d1 = OrderedDict([('a', 1), ('b', 2)]) print(ordered_d1) # OrderedDict([('a', 1), ('b', 2)]) # python自带字典无序可以在python3.5之前的版本中去验证
defalutdict 默认值字典
# defaultdict 默认值字典,后续字典中新建的key对应的值就是括号里的(括号里必须是数据类型) # 在使用key取值的时候,如果key不存在,会返回定义时的那个默认值 defaultdict(list) # 与之前fromkeys 空列表的区别,不会共用同一个列表 from collections import defaultdict values = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90] my_dict = defaultdict(list) # 后续该字典中新建的key对应的value默认就是列表 for value in values: if value > 66: my_dict['k1'].append(value) else: my_dict['k2'].append(value) print(my_dict) # defaultdict(<class 'list'>, {'k2': [11, 22, 33, 44, 55, 66], 'k1': [77, 88, 99, 90]}) # int 的默认值是0, bool 的默认值是False, tuple的默认值是 () my_dict1 = defaultdict(int) print(my_dict1['xxx']) print(my_dict1['yyy']) # 0 # 0 my_dict2 = defaultdict(bool) print(my_dict2['kkk']) # False my_dict3 = defaultdict(tuple) print(my_dict3['mmm']) # () # 括号里必须是数据类型 values = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90] # my_dict = defaultdict(values) # 报错,TypeError: first argument must be callable or None # print(my_dict) # my_dict = defaultdict("values") # 报错,TypeError: first argument must be callable or None # print(my_dict) # my_dict = defaultdict(1) # 报错,TypeError: first argument must be callable or None # print(my_dict) # my_dict = defaultdict([]) # 报错,TypeError: first argument must be callable or None strings = {'puppy', 'kitten', 'puppy', 'puppy', 'wesel', 'puppy', 'kitten', 'puppy'} counts = defaultdict(lambda: 0) for i in strings: counts[i] += 1 print(counts) # defaultdict(<function <lambda> at 0x00000163AD001E18>, {'kitten': 1, 'wesel': 1, 'puppy': 1})
Counter 计数
# Counter 计数,跟踪值出现的次数,一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。 from collections import Counter l = [1, 3, 'a', 'c', 'aa', 'a', 'b', 'c'] c = Counter(l) print(c) # Counter({'a': 2, 'c': 2, 1: 1, 3: 1, 'aa': 1, 'b': 1})
s = 'abcdeabcdabcaba' # 普通python代码写法 d = {} for i in s: if i not in d: d[i] = 1 else: d[i] += 1 print(d) # {'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1} # Counter 计数写法 from collections import Counter s = Counter('abcdeabcdabcaba') print(s) # Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
time模块与datetime模块-日期时间模块
和时间有关系的我们就要用到时间模块。在使用模块之前,应该首先导入模块。
#常用方法 1.time.sleep(secs) (线程)推迟指定的时间运行。单位为秒。 2.time.time() 获取当前时间戳
表示时间的三种方式
''' 在Python中,通常有这三种方式来表示时间:时间戳、格式化的时间字符串、结构化时间(struct_time 元组): (1)时间戳(timestamp) : 通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。 (2)格式化的时间字符串(Format String): ‘1999-12-06 12:18:16’,人们平时见得最多的时间格式。 (3)结构化时间(struct_time) : struct_time元组共九个元素:(年,月,日,时,分,秒,周几,一年中第几天,是否夏令时) '''
获取当前时间的三种格式
import time print(time.localtime()) # time.struct_time(tm_year=2019, tm_mon=7, tm_mday=27, tm_hour=8, tm_min=30, tm_sec=51, tm_wday=5, tm_yday=208, tm_isdst=0) print(time.time()) # 1564187451.786054 print(time.strftime("%Y-%m-%d %H-%M-%S")) # 2019-07-27 08-32-06
结构化时间返回值含义
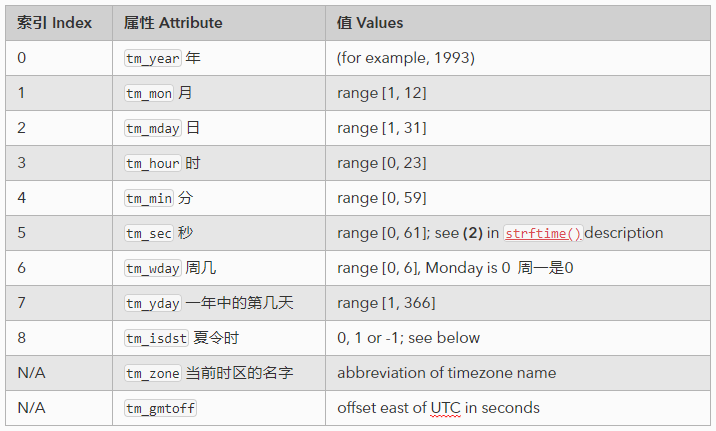
格式化时间的参数含义
''' %y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身 '''
小结:时间戳是计算机能够识别的时间;格式化时间是人能够看懂的时间;结构化时间则是用来操作时间的
几种格式之间的转换(格式化时间 和 时间戳 之间不能直接转换)
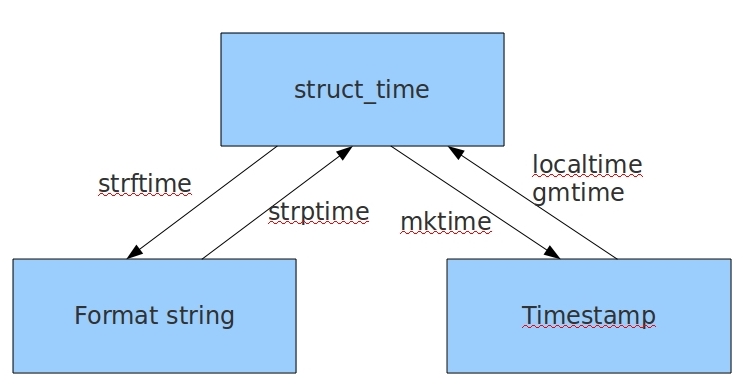
import time # ------------------------------------------------------ # 时间戳 --> 结构化时间 gmtime localtime # time.gmtime(时间戳) UTC时间 # 与英国伦敦当地时间一致 # time.localtime(时间戳) 当地时间 # 在北京执行:与UTC时间相差8小时,UTC时间+8小时 = 北京时间 # ------------------------------------------------------ # now_time = time.time() now_time = 1564915435.9014683 print(now_time) # 1564915435.9014683 print(type(now_time)) # <class 'float'> print(time.gmtime(now_time)) # time.struct_time(tm_year=2019, tm_mon=8, tm_mday=4, tm_hour=10, tm_min=43, tm_sec=55, tm_wday=6, tm_yday=216, tm_isdst=0) print(time.localtime(now_time)) # time.struct_time(tm_year=2019, tm_mon=8, tm_mday=4, tm_hour=18, tm_min=43, tm_sec=55, tm_wday=6, tm_yday=216, tm_isdst=0) print(type(time.localtime(now_time))) # <class 'time.struct_time'> # ------------------------------------------------------ # 结构化时间 --> 时间戳 mktime # ------------------------------------------------------ tuple_time = time.gmtime(now_time) print(time.mktime(tuple_time)) # 1564886635.0 tuple_time2 = time.localtime(now_time) print(time.mktime(tuple_time2)) # 1564915435.0 print(type(time.mktime(tuple_time2))) # <class 'float'> # ------------------------------------------------------ # 结构化时间 --> 格式化时间 strftime # ------------------------------------------------------ # gmtime --> 格式化时间 print(time.strftime('%Y-%m-%d %H:%M:%S', tuple_time)) # 2019-08-04 10:43:55 # localtime --> 格式化时间 print(time.strftime('%Y-%m-%d %H:%M:%S', tuple_time2)) # 2019-08-04 18:43:55 print(type(time.strftime('%Y-%m-%d %H:%M:%S', tuple_time2))) # <class 'str'> # ------------------------------------------------------ # 格式化时间 --> 结构化时间 strptime # ------------------------------------------------------ print(time.strptime('2019-08-04 10:43:55', '%Y-%m-%d %H:%M:%S')) # time.struct_time(tm_year=2019, tm_mon=8, tm_mday=4, tm_hour=10, tm_min=43, tm_sec=55, tm_wday=6, tm_yday=216, tm_isdst=-1) print(time.strptime('2019-08-04 18:43:55', '%Y-%m-%d %H:%M:%S')) # time.struct_time(tm_year=2019, tm_mon=8, tm_mday=4, tm_hour=18, tm_min=43, tm_sec=55, tm_wday=6, tm_yday=216, tm_isdst=-1) print(type(time.strptime('2019-08-04 18:43:55', '%Y-%m-%d %H:%M:%S'))) # <class 'time.struct_time'>
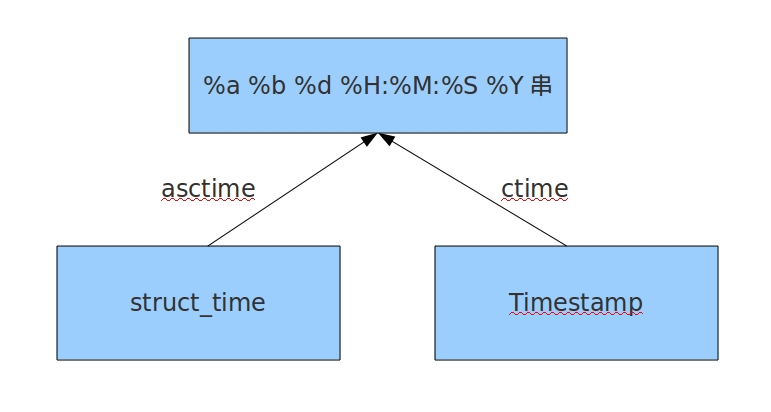
import time now_time = 1564915435.9014683 tuple_time = time.gmtime(now_time) tuple_time2 = time.localtime(now_time) # ------------------------------------------------------ # 格式化时间 --> 结构化时间 strptime # ------------------------------------------------------ print(time.strptime('2019-08-04 10:43:55', '%Y-%m-%d %H:%M:%S')) # time.struct_time(tm_year=2019, tm_mon=8, tm_mday=4, tm_hour=10, tm_min=43, tm_sec=55, tm_wday=6, tm_yday=216, tm_isdst=-1) print(time.strptime('2019-08-04 18:43:55', '%Y-%m-%d %H:%M:%S')) # time.struct_time(tm_year=2019, tm_mon=8, tm_mday=4, tm_hour=18, tm_min=43, tm_sec=55, tm_wday=6, tm_yday=216, tm_isdst=-1) print(type(time.strptime('2019-08-04 18:43:55', '%Y-%m-%d %H:%M:%S'))) # <class 'time.struct_time'> # ------------------------------------------------------ # 结构化时间 转 %a %b %d %H:%M:%S %Y # ------------------------------------------------------ print(time.asctime(tuple_time)) print(time.asctime(tuple_time2)) print(time.asctime()) # Sun Aug 4 10:43:55 2019 # Sun Aug 4 18:43:55 2019 # Sun Aug 4 20:11:50 2019 # ------------------------------------------------------ # 时间戳 --> %a %b %d %H:%M:%S %Y # ------------------------------------------------------ print(time.ctime(now_time)) print(time.ctime()) # Sun Aug 4 18:43:55 2019 # Sun Aug 4 20:11:50 2019 print(type(time.asctime())) # <class 'str'> print(type(time.ctime())) # <class 'str'>
案例计算两日期之间的日期间隔
''' 计算纪念日过去了多久小案例 ''' import time target_time = time.mktime(time.strptime('2017-11-21 21:11:34', '%Y-%m-%d %H:%M:%S')) # 纪念日时间(将格式化时间转换为结构化时间再转换为时间戳) # now_time = time.mktime(time.strptime('2017-09-12 11:00:00', '%Y-%m-%d %H:%M:%S')) # 当前时间或指定时间(算之间的时间距离) now_time = time.time() # 当前时间(当前时间时间戳) dif_time = now_time - target_time # 相距时间 struct_time = time.gmtime(dif_time) # 将时间戳转换为结构化时间 print('距离目标日期过去了%d年%d月%d天%d小时%d分钟%d秒' % (struct_time.tm_year - 1970, struct_time.tm_mon - 1, struct_time.tm_mday - 1, struct_time.tm_hour, struct_time.tm_min, struct_time.tm_sec)) # 将结构化时间转换为格式化时间(人能看得懂的时间格式) # 距离目标日期过去了1年8月3天23小时59分钟10秒
datetime模块
import datetime # 自定义日期 res = datetime.date(2019, 7, 15) print(res) # 2019-07-15 # 获取本地时间 # 年月日 now_date = datetime.date.today() print(now_date) # 2019-07-01 # 年月日时分秒 now_time = datetime.datetime.today() print(now_time) # 2019-07-01 17:46:08.214170 # 无论是年月日,还是年月日时分秒对象都可以调用以下方法获取针对性的数据 # 以datetime对象举例 print(now_time.year) # 获取年份2019 print(now_time.month) # 获取月份7 print(now_time.day) # 获取日1 print(now_time.weekday()) # 获取星期(weekday星期是0-6) 0表示周一 print(now_time.isoweekday()) # 获取星期(weekday星期是1-7) 1表示周一 # timedelta对象 # 可以对时间进行运算操作 import datetime # 获得本地日期 年月日 tday = datetime.date.today() # 定义操作时间 day=7 也就是可以对另一个时间对象加7天或者减少7点 tdelta = datetime.timedelta(days=7) # 打印今天的日期 print('今天的日期:{}'.format(tday)) # 2019-07-01 # 打印七天后的日期 print('从今天向后推7天:{}'.format(tday + tdelta)) # 2019-07-08 # 总结:日期对象与timedelta之间的关系 """ 日期对象 = 日期对象 +/- timedelta对象 timedelta对象 = 日期对象 +/- 日期对象 验证: """ # 定义日期对象 now_date1 = datetime.date.today() # 定义timedelta对象 lta = datetime.timedelta(days=6) now_date2 = now_date1 + lta # 日期对象 = 日期对象 +/- timedelta对象 print(type(now_date2)) # <class 'datetime.date'> lta2 = now_date1 - now_date2 # timedelta对象 = 日期对象 +/- 日期对象 print(type(lta2)) # <class 'datetime.timedelta'> # 小练习 计算举例今年过生日还有多少天 birthday = datetime.date(2019, 12, 21) now_date = datetime.date.today() days = birthday - now_date print('生日:{}'.format(birthday)) print('今天的日期:{}'.format(tday)) print('距离生日还有{}天'.format(days)) # 总结年月日时分秒及时区问题 import datetime dt_today = datetime.datetime.today() dt_now = datetime.datetime.now() dt_utcnow = datetime.datetime.utcnow() # UTC时间与我们的北京时间cha ju print(dt_today) print(dt_now) print(dt_utcnow)
# time """ 三种表现形式 1.时间戳 2.格式化时间(用来展示给人看的) 3.结构化时间 """ import time # print(time.time()) # print(time.strftime('%Y-%m-%d')) # print(time.strftime('%Y-%m-%d %H:%M:%S')) # print(time.strftime('%Y-%m-%d %X')) # %X等价于%H:%M:%S # print(time.strftime('%H:%M')) # print(time.strftime('%Y/%m')) # print(time.localtime()) # print(time.localtime(time.time())) # res = time.localtime(time.time()) # print(time.time()) # print(time.mktime(res)) # print(time.strftime('%Y-%m',time.localtime())) # print(time.strptime(time.strftime('%Y-%m',time.localtime()),'%Y-%m')) # datetime import datetime # print(datetime.date.today()) # date>>>:年月日 # print(datetime.datetime.today()) # datetime>>>:年月日 时分秒 # res = datetime.date.today() # res1 = datetime.datetime.today() # print(res.year) # print(res.month) # print(res.day) # print(res.weekday()) # 0-6表示星期 0表示周一 # print(res.isoweekday()) # 1-7表示星期 7就是周日 """ (******) 日期对象 = 日期对象 +/- timedelta对象 timedelta对象 = 日期对象 +/- 日期对象 """ # current_time = datetime.date.today() # 日期对象 # timetel_t = datetime.timedelta(days=7) # timedelta对象 # res1 = current_time+timetel_t # 日期对象 # # print(current_time - timetel_t) # print(res1-current_time) # 小练习 计算今天距离今年过生日还有多少天 # birth = datetime.datetime(2019,12,21,8,8,8) # current_time = datetime.datetime.today() # print(birth-current_time) # UTC时间 # dt_today = datetime.datetime.today() # dt_now = datetime.datetime.now() # dt_utcnow = datetime.datetime.utcnow() # print(dt_utcnow,dt_now,dt_today)
计算日期时间案例
''' 计算过去了多少天小案例 ''' import datetime target_time = datetime.datetime(2017, 11, 21, 21, 11, 34) current_time = datetime.datetime.today() dif_time = current_time - target_time print(f"距离目标日期过去了{dif_time.days}天") # 距离目标日期过去了612天
random模块-随机模块
python产生随机数的(无规律)模块, # 此部分的打印结果仅供参考(因为是随机的,所以可能每次都会不同)
import random # random 随机生成 0-1之间的小数 print(random.random()) # 0.322594699359685 # randint(1, 5)随机生成1-5之间的整数(包含1和5) print(random.randint(1, 5)) # 2 # choice 随机返回传入的迭代对象中的一个值 print(random.choice([1, '23', [4, 5]])) # [4, 5] # shuffle 打乱传入列表的元素顺序 item = [1, 3, 5, 6, 7] print(random.shuffle(item), item) # None [6, 7, 1, 3, 5] print(random.shuffle(item), item) # None [6, 7, 5, 1, 3]
import random # uniform(1, 3) 随机返回一个大于1小于3的小数 print(random.uniform(1, 3)) # 2.2101994265961986 # randrange(1, 10, 2) 随机返回一个大于1且小于10之间的奇数 print(random.randrange(1, 10, 2)) # 3 # sample(可迭代对象, 返回个数) 随机选择指定个数(第二个参数)的元素返回(放在列表里) print(random.sample([1, '23', [4, 5]], 2)) # [[4, 5], 1]
生成指定位数验证码demo
''' 要求: 5位数的随机字符串验证码(组成:大写字母 小写字母 数字) 写成函数,用户输入几,就生成几位 print(ord('a'), ord('z')) # 97 122 print(ord('A'), ord('Z')) # 65 90 print(ord('0'), ord('9')) # 48 57 '''
import random def get_code(n): code = '' for i in range(n): # 先生成随机的大写字母 小写字母 数字 upper_str = chr(random.randint(65, 90)) lower_str = chr(random.randint(97, 122)) random_int = str(random.randint(0, 9)) # 从上面三个中随机选择一个作为随机验证码的某一位 code += random.choice([upper_str, lower_str, random_int]) return code n = int(input("Please input the count of you want>>>:").strip()) # 假定用户输入的都是合法数字 res = get_code(n) print(res) # Please input the count of you want>>>:5 # P5SSZ
# 生成所有0-9数字字符列表 num_list = [chr(i) for i in range(48, 57+1)] # 生成所有小写字母列表 lower_letter_list = [chr(i) for i in range(97, 122+1)] # 生成所有大写字母列表 upper_letter_list = [chr(i) for i in range(65, 90+1)] # 将大小写字母以及数字都放到一个大列表里去 verify_char_list = [] verify_char_list.extend(num_list) verify_char_list.extend(lower_letter_list) verify_char_list.extend(upper_letter_list) # print(verify_char_list) # # ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'] # 根据用户输入的次数,生成指定位数的随机字符串 def get_verify_code(count): # 写法一 # random_code = [] # for i in range(count): # # 随机取一个字符,并放到验证码的列表里 # random_code.append(random.choice(verify_char_list)) # return ''.join(random_code) # 将列表里的所有字符拼起来,返回给调用者 # 写法二 (有bug,这样生成的验证码,每一位都不同,不太符合常规) random_code = random.sample(verify_char_list, count) return ''.join(random_code) count = int(input("Please input the count of your verify code>>>:").strip()) print(get_verify_code(count)) # Please input the count of your verify code>>>:8 # Ht1ixiea
os模块-操作系统的文件系统
os模块是与操作系统交互的一个接口
常见方法
import os # os模块主要用来与文件系统打交道 # os.path.dirname() 获取上级目录 BASE_DIR = os.path.dirname(os.path.dirname(__file__)) # os.path.join() 拼接路径专用(不需要自己处理window与linux等平台的目录分隔符(/)不同问题) name = 'jason' print(os.path.join(BASE_DIR, f'{name}.json')) # E:/PyCharm 2019.1.3/ProjectFile/day010jason.json my_path = os.path.join(BASE_DIR, 'db', 'db2', 'CodeMan', f'{name}.json') # 可传多个参数,依次拼接 print(my_path) # E:/PyCharm 2019.1.3/ProjectFile/day010dbdb2CodeManjason.json # os.listdir() 列出指定目录下的所有文件 print(os.listdir(os.path.dirname(__file__))) # ['.idea', ..省略大量文件..., 'sys模块巩固.py', 'test.py', 'test2.py', '__pycache__'] # os.path.split() 将path分割成目录和文件名二元组返回 print(os.path.split(my_path)) # ('E:/PyCharm 2019.1.3/ProjectFile/day010\db\db2\CodeMan', 'jason.json') print(os.path.abspath(__file__)) # 获取当前文件的绝对路径 # E:PyCharm 2019.1.3ProjectFileday010day022os模块巩固练习.py os.remove(my_path) # 删除指定文件 os.rename(my_path, 'new_name') # 重命名指定文件 # 上面两个方法可以组合用在修改文件内容上,先删除,再重命名 # os.mkdir('tank老师精选') # 自动创建文件夹,文件存在时会报错 print(os.path.exists(r'E:PyCharm 2019.1.3ProjectFileday010day016作品')) # 判断文件是否存在 # False print(os.path.exists(r'E:PyCharm 2019.1.3ProjectFileday010day016作品 ank老师.txt')) # 判断文件是否存在 # True print(os.path.isfile(r'E:PyCharm 2019.1.3ProjectFileday010day016 ank老师精选')) # 只能判断文件 不能判断文件夹 # False print(os.path.isfile(r'E:PyCharm 2019.1.3ProjectFileday010day016作品 ank老师.txt')) # 只能判断文件 不能判断文件夹 # True # os.rmdir(r'D:Python项目day16作品') # 会报错,只能删空文件夹 print(os.getcwd()) # 获取当前工作目录 # E:PyCharm 2019.1.3ProjectFileday010day016 print(os.chdir(r'E:PyCharm 2019.1.3ProjectFileday010day016老师们的作品')) # 切换当前所在的目录, 找不到会报错 # None print(os.getcwd()) # E:PyCharm 2019.1.3ProjectFileday010day016作品 print(os.path.getsize(r'E:PyCharm 2019.1.3ProjectFileday010day016作品 ank老师.txt')) # 字节大小,找不到报错 # 22 with open(r'E:PyCharm 2019.1.3ProjectFileday010day016作品 ank老师.txt', encoding='utf-8') as f: print(len(f.read())) # f.read在r 模式下默认读取的是字符数哦(1个字符的中文是3个字节) # 10 # ------------------------------------------------- # 其他可能用到的方法参考(用到相关的直接来查就行了) # ------------------------------------------------- ''' os.makedirs('dirname1/dirname2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息 os.system("bash command") 运行shell命令,直接显示 os.popen("bash command).read() 运行shell命令,获取执行结果 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.path os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 '''
其余不太重要的
# ------------------------------------------------- # 了解知识(用到相关的直接来查就行了) # ------------------------------------------------- print(os.stat(r'E:PyCharm 2019.1.3ProjectFileday010day022os模块巩固练习.py')) # os.stat_result(st_mode=33206, st_ino=844424930417653, st_dev=3050226722, st_nlink=1, st_uid=0, st_gid=0, st_size=3842, st_atime=1564143417, st_mtime=1564143417, st_ctime=1564140424) ''' 上述返回参数 st_mode: inode 保护模式 st_ino: inode 节点号。 st_dev: inode 驻留的设备。 st_nlink: inode 的链接数。 st_uid: 所有者的用户ID。 st_gid: 所有者的组ID。 st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。 st_atime: 上次访问的时间。 st_mtime: 最后一次修改的时间。 st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。 ''' print(os.sep) # 输出当前操作系统的路径分隔符 # print(os.linesep) # 输出当前平台使用的行终止符,win下为" ",Linux下为" "(windows下是 所以控制台打印了两个空行) # # print(os.pathsep) # 输出用于分割文件路径的字符串 win下为;,Linux下为: # ; print(os.name) # 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' # nt # os.system('ping www.baidu.com') # 执行命令行命令(中文会乱码)Execute the command in a subshell. # # ���� Ping www.a.shifen.com [61.135.169.121] ���� 32 �ֽڵ�����: # # ���� 61.135.169.121 �Ļظ�: �ֽ�=32 ʱ��=43ms TTL=54 # # ���� 61.135.169.121 �Ļظ�: �ֽ�=32 ʱ��=26ms TTL=54 # # ���� 61.135.169.121 �Ļظ�: �ֽ�=32 ʱ��=26ms TTL=54 # # ���� 61.135.169.121 �Ļظ�: �ֽ�=32 ʱ��=25ms TTL=54 # 按了 Ctrl + C 终止 # # # # 61.135.169.121 �� Ping ͳ����Ϣ: # # ���ݰ�: �ѷ��� = 4���ѽ��� = 4����ʧ = 0 (0% ��ʧ)�� # # �����г̵Ĺ���ʱ��(�Ժ���Ϊ��λ): # # ��� = 25ms��� = 43ms��ƽ�� = 30ms my_path = r'E:PyCharm 2019.1.3ProjectFileday010day022os模块巩固练习.py' print(os.path.getatime(my_path)) # 返回path所指向的文件或者目录的最后访问时间(时间戳) # 1564144609.6118524 print(os.path.getmtime(my_path)) # 返回path所指向的文件或者目录的最后一次修改时间(时间戳) # 1564144609.6118524 print(os.path.getctime(my_path)) # 返回path所指向的文件或者目录的创建时间(时间戳) # 1564140424.6713605 import time struct_time = time.gmtime(os.path.getmtime(my_path)) print(struct_time) # 时区原因,差了八个小时 # time.struct_time(tm_year=2019, tm_mon=7, tm_mday=26, tm_hour=12, tm_min=43, tm_sec=23, tm_wday=4, tm_yday=207, tm_isdst=0) print(time.strftime("%Y-%m-%d %H:%M:%S")) # 2019-07-26 20:43:23
sys模块-python解释器
sys模块是与python解释器交互的一个接口
import sys print(sys.version) # 获取当前使用python解释器的版本 # 3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:54:40) [MSC v.1900 64 bit (AMD64)] print(sys.platform) # 获取操作系统平台名称(不知道什么原理,我的是window64位) # win32 print(sys.path) # 获取当前python解释内的环境变量(查找自定义模块时的查找目录) # ['E:\......\day022', ..省略一大串... 'E:\....\pycharm_matplotlib_backend'] print(sys.modules) # 存放了内存中已加载的模块,加载模块时会在这里面找,找不到再去按照查找顺序加载 ''' {'builtins': ....., '__main__': <module '__main__' ..省略大段... from 'E:/....../sys模块巩固.py'>, 'os': <module 'os' from .. os.py'>} ''' # print(sys.modules['test']) # 模块还没有加载,此时会直接报错,KeyError: 'test' import test print(sys.modules['test']) # <module 'test' from 'E:\PyCharm 2019.1.3\ProjectFile\day010\day022\test.py'> # sys.argv # 命令行参数List,第一个元素是程序本身路径 # 获取当前文件系统的字符编码 print(sys.getfilesystemencoding()) # utf-8 print(sys.getrecursionlimit()) # 获取python递归函数的递归深度 # 1000 print(sys.setrecursionlimit(200)) # 自定义python递归函数的递归深度 # None print(sys.getrecursionlimit()) # 获取python递归函数的递归深度 # 200 print(sys.exit(0)) # sys.exit(0)直接结束程序,后面的代码不会执行 正常退出时exit(0),错误退出sys.exit(1) print("halo~")
import sys try: sys.exit(1) except SystemExit as e: print(e)
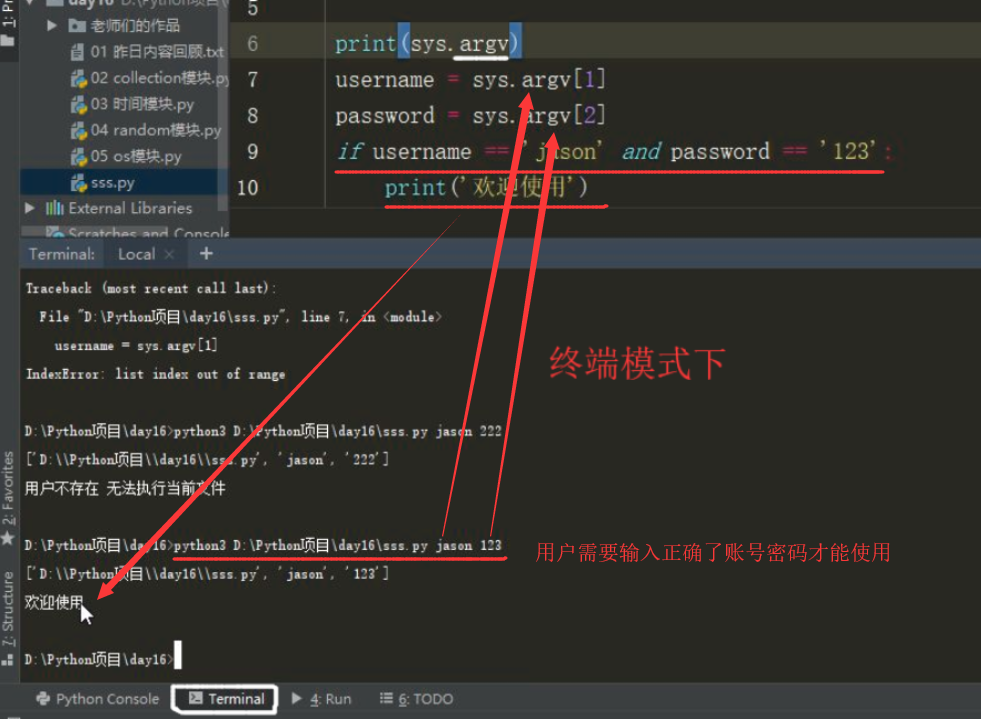
import sys print(sys.argv) # 命令行启动文件 可以做身份的验证 if len(sys.argv) <= 1: print('请输入用户名和密码') else: username = sys.argv[1] password = sys.argv[2] if username == 'jason' and password == '123': print('欢迎使用') # 当前这个py文件逻辑代码 else: print('用户不存在 无法执行当前文件')
json与pickle模块-反序列化模块
序列:序列就是指字符串
序列化:其它数据类型转换为字符串的过程
为什么要序列化
''' 为什么要序列化: 写入文件的数据必须是字符串或者二进制(数据类型中只有字符串可以encode可以变成二进制) 各个语言(python java c++)的数据类型不一样(数据之间要共用,传递) 基于网络传输的数据必须是二进制 '''
两个过程: # 序列化:把其它数据类型转换成字符串 , # 反序列化:把字符串转成其它数据类型
在python中两个序列化模块的特点
''' json模块(*********) 所有的编程语言都支持json 格式 支持的python数据类型很少,字符串、列表、字典、整型、元组(转成列表了)(对象、函数 不是所有语言都能相通) pickle模块 只支持python 一门语言 python所有的数据类型都支持 '''
json模块
''' 序列化时 python中的数据类型与json中的转换关系 +-------------------+---------------+ | Python | JSON | +===================+===============+ | dict | object | +-------------------+---------------+ | list, tuple | array | +-------------------+---------------+ | str | string | +-------------------+---------------+ | int, float | number | +-------------------+---------------+ | True | true | +-------------------+---------------+ | False | false | +-------------------+---------------+ | None | null | +-------------------+---------------+ '''
import json # dumps 序列化:将一个传入的数据类型序列化(转换)为字符串 dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} str_dic = json.dumps(dic) print(str_dic, type(str_dic)) # json转换的字符串类型的字典的字符是由 "" 表示的(不管你是单引号还是双引号) # {"k1": "v1", "k2": "v2", "k3": "v3"} <class 'str'> l = [1, 2, 45, 6, 7] str_l = json.dumps(l) print(str_l, type(str_l)) # [1, 2, 45, 6, 7] <class 'str'> t = (13, 2, 45, 66, 7) str_t = json.dumps(t) print(str_t, type(str_t)) # json中没有元组类型,python中的list、tuple序列化后都会成为(json里数组类型的)字符串 # [13, 2, 45, 66, 7] <class 'str'> # loads 反序列化:将json字符串反序列化(转换)回python的对应数据类型 str_dic = json.loads(str_dic) print(str_dic, type(str_dic)) # {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} <class 'dict'> str_l = json.loads(str_l) print(str_l, type(str_l)) # [1, 2, 45, 6, 7] <class 'list'> # 已经返不回tuple元组了(json列表反序列化的python中的list列表) str_t = json.loads(str_t) print(str_t, type(str_t)) # [13, 2, 45, 66, 7] <class 'list'>
# fp 形参,代表文件句柄对象 ''' dump load 是与文件一起操作的 ''' dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} # 没有这个文件没关系,w模式会自动创建 with open('userinfo.txt', 'w', encoding='utf-8') as f: json.dump(dic, f) # 将python数据类型序列化为字符串并自动写入文件 with open('userinfo.txt', 'r', encoding='utf-8') as f: res = json.load(f) # 将字符串反序列化成python数据类型 print(res, type(res)) # {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} <class 'dict'>
看完上面dump load,在你实际操作时可能会遇到有多个字典反序列化不回来的情况,可以这样处理
案例一:用户信息存储
按下面的目录建好文件,右键运行即可(此部分代码仅有一个注册功能,主要目的是演示json 序列化反序列化数据到文件中)
[{"username": "tank", "pwd": "59f471f262ab586fb959ded0e2c7b94f", "operation": []}, {"username": "jason", "pwd": "59f471f262ab586fb959ded0e2c7b94f", "operation": []}, {"username": "egon", "pwd": "59f471f262ab586fb959ded0e2c7b94f", "operation": []}]
[{ "username": "tank", "pwd": "59f471f262ab586fb959ded0e2c7b94f", "operation": [] }, { "username": "jason", "pwd": "59f471f262ab586fb959ded0e2c7b94f", "operation": [] }, { "username": "egon", "pwd": "59f471f262ab586fb959ded0e2c7b94f", "operation": [] }]
import os import json BASE_DIR = os.path.dirname(os.path.dirname(__file__)) DB_DIR = os.path.join(BASE_DIR, 'db') admin_file = os.path.join(DB_DIR, "admin.json") def select(admin_name): if os.path.exists(admin_file): with open(admin_file, mode='r', encoding='utf-8') as f: all = json.load(f, encoding='utf-8') for line in all: if admin_name in line.get('username'): return True else: return False def save_admin(admin_dict): admins = [] if os.path.exists(admin_file) and os.path.getsize(admin_file): with open(admin_file, mode='r', encoding='utf-8') as f: has_admin = False all = json.load(f, encoding='utf-8') # 通过json.load将文件的所有内容反序列化成python中的数据类型 for line in all: if admin_dict['username'] in line.get('username'): admins.append(admin_dict) has_admin = True else: admins.append(line) if not has_admin: admins.append(admin_dict) else: admins.append(admin_dict) with open(admin_file, mode='w', encoding='utf-8') as f: json.dump(admins, f, ensure_ascii=False) # 将python的数据类型通过json.dump序列化成json中的数据存入文件 return True
from db import admin_db_handler from lib import common def check_admin_exits(admin_name): return admin_db_handler.select(admin_name) def register_admin(username, pwd): pwd = common.get_md5(pwd) admin_dict = { 'username': username, 'pwd': pwd, 'operation': [], } flag = admin_db_handler.save_admin(admin_dict) return flag
''' 前言: 管理员系统与普通用户系统相隔离,管理员系统作为后台,不向用户公开 ''' from interface import admin_interface def register(): while True: admin_name = input("请输入管理员用户名>>>:").strip() if admin_name == 'q': break if admin_interface.check_admin_exits(admin_name): print("该管理员用户名已存在,请重新输入") continue pwd = input("请输入密码>>>:").strip() repwd = input("请再次输入密码>>>:").strip() if pwd != repwd: print("两次密码不一致,请重新输入") continue if admin_interface.register_admin(admin_name, pwd): print(f"{admin_name}用户注册成功") break def login(): pass def lock_user(): pass def unlock_user(): pass def change_user_balance(): pass def reset_user_password(): # 管理员可以直接根据用户名设置新密码 pass func_list = { "1": register, "2": login, "3": lock_user, "4": unlock_user, "5": change_user_balance, "6": reset_user_password, } current_admin = { 'username': None, 'pwd': None, 'operation': [], } def run(): while True: print(""" 1.注册 2.登录 3.冻结用户 4.解冻用户 5.更改用户余额 6.重置用户密码 """) choice = input("请选择功能编号>>>:").strip() if choice == 'q': print("感谢您的使用,祝您生活愉快~") break elif choice in func_list: func_list[choice]() else: print("正确输入功能编号!")
import os import sys BASE_DIR = os.path.dirname(os.path.dirname(__file__)) sys.path.append(BASE_DIR) from core import admin_src if __name__ == '__main__': admin_src.run()
import hashlib import logging.config from conf import settings # 字符串md5加密(密码加密) def get_md5(string: str) -> str: md = hashlib.md5() md.update('md5_salt'.encode('utf-8')) md.update(string.encode('utf-8')) return md.hexdigest()
案例二
# 用 loads 来分行处理字符串,然后再返回 import json dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} with open('userinfo.txt', 'w', encoding='utf-8') as f: json_str = json.dumps(dic) # 放两边,存两个字典 f.write('%s ' % json_str) f.write('%s ' % json_str) with open('userinfo.txt', 'r', encoding='utf-8') as f: for line in f: # 一行一行反序列化回字符串 res = json.loads(line) print(res, type(res)) t = (1, 2, 3, 4) print(json.dumps(t)) # {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} <class 'dict'> # {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} <class 'dict'> # [1, 2, 3, 4]
d1 = {'name': '孙坚强超坚强'}
print(json.dumps(d1))
print(json.dumps(d1, ensure_ascii=False)) # 通过指定 ensure_ascii=False来避免
# {"name": "u5b59u575au5f3au8d85u575au5f3a"}
# {"name": "孙坚强超坚强"}
pickle模块
大体上与json模块一致(支持的语言种类不同,pickle只支持python,数据序列化成二进制数据)
import pickle # pickle 模块支持python中的所有数据类型,但是他只能支持python一门语言 # dumps loads 序列化反序列化,序列化的结果是二进制 d = {'name': 'Arson'} res = pickle.dumps(d) # 将对象直接转成二进制 print(pickle.dumps(d)) # b'x80x03}qx00Xx04x00x00x00nameqx01Xx05x00x00x00Arsonqx02s.' res1 = pickle.loads(res) print(res1, type(res1)) # {'name': 'Arson'} <class 'dict'>
import pickle """ 用pickle操作文件的时候 文件的打开模式必须是b模式(b模式不能加encoding哦) """ # dump load 配合文件使用的序列化反序列化 with open('userinfo_1.txt', 'wb') as f: pickle.dump(d, f) with open('userinfo_1.txt', 'rb') as f: res = pickle.load(f) print(res, type(res)) # {'name': 'Arson'} <class 'dict'>
subprocess模块
subprocess模块,子进程模块
远程操作电脑的歩鄹:
# 远程操作电脑 # 1.用户通过网络连接上了这台电脑 # 2.用户输入相应的命令,基于网络发送给了你这台电脑上的某个程序 # 3.获取用户命令,利用subprocess模块执行该命令 # 4.将执行结果再基于网络再发送给用户 # 这样就实现了 用户远程操作你这台电脑的操作
import subprocess # 执行传入的第一个参数(如果参数是错误命令,则会打印 stderr 信息) obj = subprocess.Popen('tasklist', shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) print(obj) # <subprocess.Popen object at 0x00000200D3CC8668> print('正确命令返回的结果stdout', obj.stdout.read().decode('GBK')) # 没错误就返回(Windows终端默认编码GBK) # stdout # 映像名称 PID 会话名 会话# 内存使用 # ========================= ======== ================ =========== ============ # System Idle Process 0 Services 0 8 K # System 4 Services 0 140 K # Registry 96 Services 0 34,416 K # ........省略大量信息 print('错误命令返回的提示信息stderr', obj.stderr.read().decode('GBK')) # 在第一个参数不存在的时候,stderr才会输出信息 # stderr 'dfsfs' 不是内部或外部命令,也不是可运行的程序 # 或批处理文件。
小案例,在python命令行执行操作系统命令
while True: cmd = input('cmd>>>:').strip() import subprocess obj = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) # print(obj) print('正确命令返回的结果stdout', obj.stdout.read().decode('gbk')) print('错误命令返回的提示信息stderr', obj.stderr.read().decode('gbk'))