PageRank算法是一种经典的网页排序算法,是谷歌的两位创始人佩奇 (Larry Page) 和布林 (Sergey Brin)提出的。他们借鉴了学术界评判学术论文重要性的通用方法, 就是论文的引用次数,来评判一个网页的重要性(给网页一个附加的PageRank值),然后据此来给网页排名。
基本思想
- 数量假设:如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是PageRank值会相对较高。
- 质量假设:如果一个PageRank值很高的网页链接到一个其他的网页,那么被链接到的网页的PageRank值会相应地因此而提高。

PageRank值的简单计算
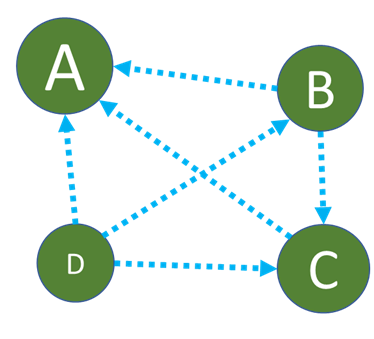
假设一个由只有4个页面组成的集合:A,B,C和D。如果所有页面都链向A,那么A的PR(PageRank)值将是B,C及D的和。

继续假设B也有链接到C,并且D有链接到其他三个页面。每个页面拥有的投票数是一定的,所以B相当于将自己的票分给A、C各一半。按同样的逻辑,D投出的票只有三分之一算到了A的PageRank上。
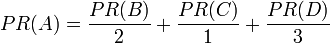
换句话说,根据出链总数平分一个页面的PR值。一个页面的出链是指自己指向其它页面的链接。
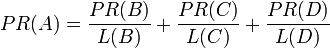
特殊情况的处理
在现实网络中,有些页面的出链数为0,即不链接到任何网页的页面,但是很多网页可以访问它。为了能处理这些网页,PangRank算法进行了一定的修正,引入了增加阻尼系数d(damping factor)。阻尼系数,一般定义为用户随机点击链接或在地址栏输入链接而进入其他网页的概率,根据工程经验一般取0.85。下面的公式是计算网页A的PR值公式。Ti是存在到A的链接的网页。C(Ti)是网页Ti中存在的链接的数量。d是。而(1-d)代表着不考虑入站链接的情况下随机进入一个页面的概率。
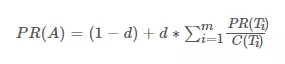
优缺点
优点:PageRank算法是一个与查询无关的静态算法,所有网页的PageRank值都是通过离线计算获得,从而有效减少了在线查询时的计算量,极大降低了查询响应时间。
缺点:
- 人们的查询具有主题特征,PageRank忽略了主题相关性,导致结果的相关性和主题性降低
- 旧的页面等级会比新页面高。因为即使是非常好的新页面也不会有很多上游链接,除非它是某个站点的子站点。