在这一篇文章中,我们主要来介绍多线程抓取数据。

多线程是以并发的方式执行的,在这里要注意,Python的多线程程序只能运行在一个单核上以并发的方式运行,即便是多核的机器,所以说,使用多线程抓取可以极大地提高抓取效率
下面我们以requests为例介绍多线程抓取,然后在通过与单线程程序比较,体会多线程的效率的提高
这一次,我就不用我的网站做测试了,因为网站的内容此时还并不是太多,不能体现多线程的优势
我们通过当当网来测试我们的多线程实例,通过对搜索结果的同一抓取实现功能的演示,搜索模式地址如下
http://search.dangdang.com/?key=Python&act=input&page_index=1
可以看到key代表的是搜索关键字,act代表你是通过什么方式搜索的,page_index代表的是搜索页面的页码
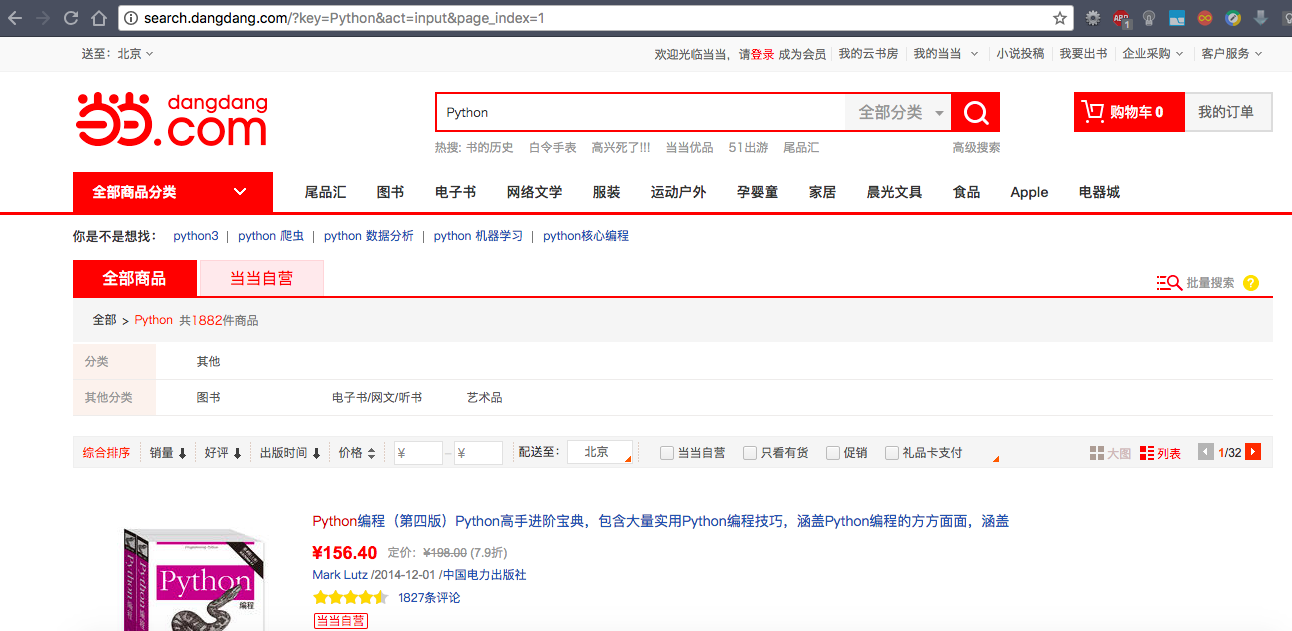
在抓取到上面的页码后,要对里面的信息进行提取,最后将提取的信息保存在文本文件中,文件中保存每一本书的书名,以及他的链接
下面我们定义抓取实验所需要的方法(或函数)
# coding=utf-8
__Author__ = "susmote"
import requests
from bs4 import BeautifulSoup
def format_str(s):
return s.replace("
", "").replace(" ", "").replace(" ", "")
def get_urls_in_pages(from_page_num, to_page_num):
urls = []
search_word = "python"
url_part_1 = "http://search.dangdang.com/?key="
url_part_2 = "&act=input"
url_part_3 = "&page_index="
for i in range(from_page_num, to_page_num + 1):
urls.append(url_part_1 + search_word + url_part_2 + url_part_3 + str(i))
all_href_list = []
for url in urls:
print(url)
resp = requests.get(url)
bs = BeautifulSoup(resp.text, "lxml")
a_list = bs.find_all("a")
needed_list = []
for a in a_list:
if 'name' in a.attrs:
name_val = a['name']
href_val = a['href']
title = a.text
if 'itemlist-title' in name_val and title != "":
if [title, href_val] not in needed_list:
needed_list.append([format_str(title), format_str(href_val)])
all_href_list += needed_list
all_href_file = open(str(from_page_num) + '_' + str(to_page_num) + '_' + 'all_hrefs.txt', 'w')
for href in all_href_list:
all_href_file.write(' '.join(href) + '
')
all_href_file.close()
print(from_page_num, to_page_num, len(all_href_list))
下面我们来解释一下这些代码
首先,format_str是用来在提取信息后去掉多余的空白
而get_url_in_pages方法是执行功能的主体,这个方法接收的参数是指页码的范围,函数体中,urls主要用来存放基于两个参数所生成的所有要抓取的页面的链接,我把url分为3个部分,也是为了方便之后对链接的组合,然后的for循环就是做的是拼接的工作,这里我不多做解释了,如果不懂,请留言
下一步,我们定义了一个列表all_href_list ,这个列表是用来存储每页中包含图书信息的,实际上它又是一个嵌套的列表,里面的元素是[书名, 链接],他的形式如下所示
all_href_list = [
['书名1', "链接1"],
['书名2', "链接2"],
['书名3', "链接3"],
......
]
后面的代码就是对灭一页进行抓取和提取信息了,这部分的代码都在for url in urls这个循环体中,首先打印链接,然后调用requs的get方法,获取页面,之后又使用BeautifulSoup将get请求放回的HTML文本进行分析,转为BeautifulSoup能够处理的结构,命名为bs
之后我们定义的needed_list是用来存放书名和链接的,bs.find_all('a')抽取了页面中所有的链接元素,for a in a_list 对每一个列表中的元素进行遍历分析,在这之前,我们通过浏览器发现了他的结构
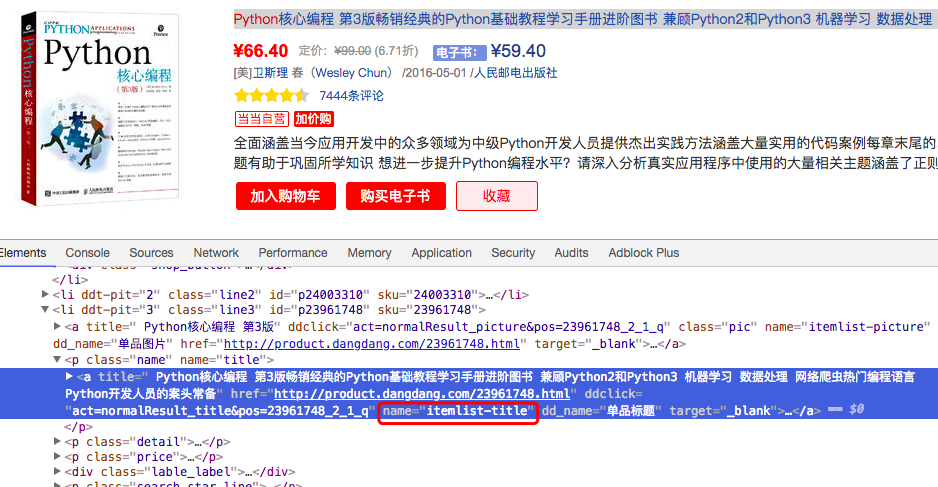
每个书籍元素中都会有一个属性name,值为"itemlist_title",通过这个我们很容易的就筛选出了书籍元素,然后将书籍信息,以及链接元素href一同存入列表,在存之前,我们还做了一些判断,是否已经存在这个链接了,和这个元素的链接为空
每抽取完一个页面的链接后,就可以把它加入到all_href_list中,也就是下面这行代码
all_href_list += needed_list
注意我在这里使用的是 += 运算符
获取到范围内所有的链接元素后,就可以写入文件了,在这里我不做过多解释了
然后我们下一步就是定义多线程了,因为我们搜索关键词总的页数是32页

所以我们在这里准备用3个线程来完成这些任务,也就是每个线程处理10个页面,在单线程的情况下,这30页用一个线程单独完成
下面我们给出抓取方案的代码
# coding=utf-8
__Author__ = "susmote"
import time
import threading
from mining_func import get_urls_in_pages
def multiple_threads_test():
start_time = time.time()
page_range_list = [
(1, 10),
(11, 20),
(21, 32),
]
th_list = []
for page_range in page_range_list:
th = threading.Thread(target = get_urls_in_pages, args = (page_range[0], page_range[1]))
th_list.append(th)
for th in th_list:
th.start()
for th in th_list:
th.join()
end_time = time.time()
print("共使用时间1:", end_time - start_time)
return end_time - start_time
简单解释一下,为了获取运行的时间,我们定义了一个开始时间start_time 和 一个结束时间end_time,运行时间也就是结束时间减去开始时间
然后定义的一个列表page_range_list也就是把页码分为三段,前面有提到过
之后又定义了一个列表th_list也就是存储所有线程对象的列表,之后通过一个循环,生成了3个线程对象,分别对应着不同的页码范围,把他们存入列表
然后在后面的循环中,分别执行th.start(),开启线程,在后面,我们为了使这些异步并发执行的线程都执行完毕后再退出函数,这里使用了线程的join方法,等待各线程执行完毕
下面就是最激动人心的时候了,对代码进行测试
在这里,我们写下如下代码
# coding=utf-8
__Author__ = "susmote"
from mining_threading import multiple_threads_test
if __name__ == "__main__":
mt = multiple_threads_test()
print('mt', mt)
为了使测试结果更加精确,我们进行三次实验,取平均时间
第一次实验

使用时间6.651
第二次实验

使用时间6.876
第三次实验

使用时间6.960
平均时间如下

6.829
下面是单进程代码
# coding=utf-8
__Author__ = "susmote"
import time
from mining_func import get_urls_in_pages
def sigle_test():
start_time = time.time()
get_urls_in_pages(1, 32)
end_time = time.time()
print("共使用时间 : ", end_time - start_time)
return end_time - start_time
调用函数如下
# coding=utf-8
__Author__ = "susmote"
from single_mining import single_test
if __name__ == "__main__":
st = single_test()
print('st ', st)
在命令行下执行
第一次

10.138
第二次

10.290
第三次

10.087
平均花费时间

10.171
所以说,多线程的确能够提高抓取的效率,注意,这是在数据比较少的情况进行的,如果数据量比较大的话,多线程的优势就很明显了
你可以自己去更改搜索关键词,和页码,或是重新找一个网页(抓取跟网速也有很大的关系)
附几张抓取数据的图