scrapy爬取网站案例
爬取抽屉网数据,存到Redis和MySQL中,实现持久化
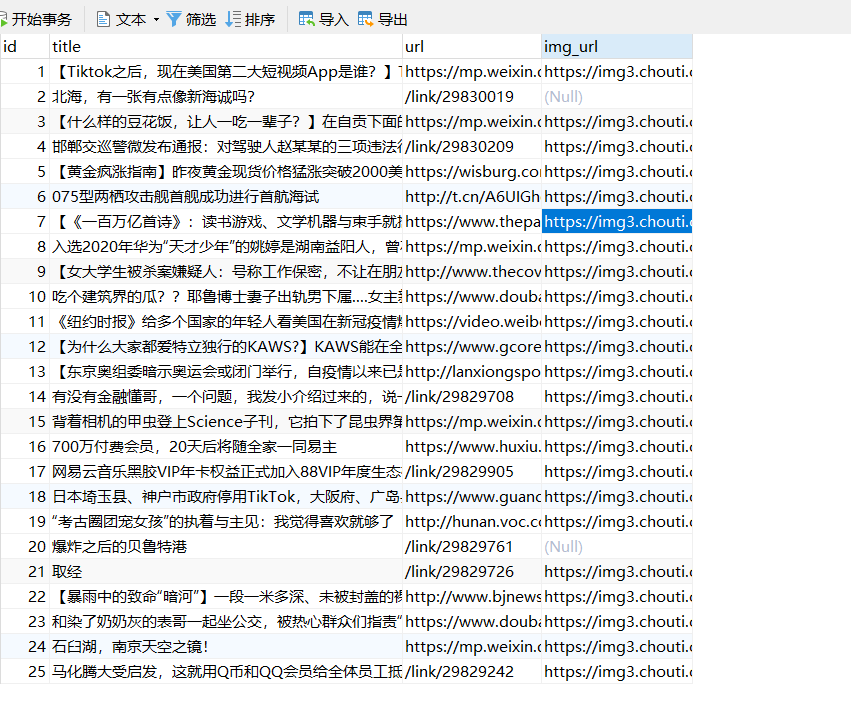
Mysql实现
# settings.py
ITEM_PIPELINES = {
'firstscrapy.pipelines.DrawerMysqlPipeline': 305,
}
# pipelines.py
class DrawerMysqlPipeline:
def __init__(self):
"""
初始化方法
host=None, user=None, password="",
database=None, port=0, unix_socket=None,
charset='',
"""
self.conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123456',
database='drawer',
charset='utf8'
)
self.cursor = self.conn.cursor(cursor=pymysql.cursors.DictCursor)
def open_spider(self,spider):
pass
def process_item(self, item, spider):
sql = 'insert into drawer (title,url,img_url)values (%s,%s,%s)' # sql语句
self.cursor.execute(sql,[item['title'],item['url'],item['img_url']]) # 执行sql
self.conn.commit() # 提交命令,修改数据库
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
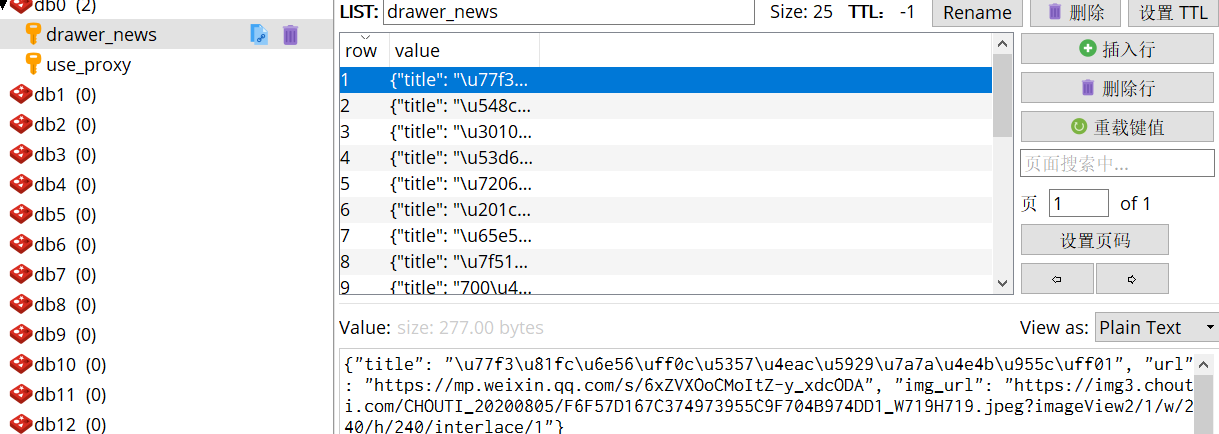
Redis实现
from redis import Redis
import json
class DrawerRedisPipeline:
def __init__(self):
self.conn = None
def open_spider(self,spider):
self.conn = Redis(host='127.0.0.1',port=6379)
def process_item(self, item, spider):
self.conn.lpush('drawer_news',json.dumps(dict(item)))
return item
def close_spider(self,spider):
pass
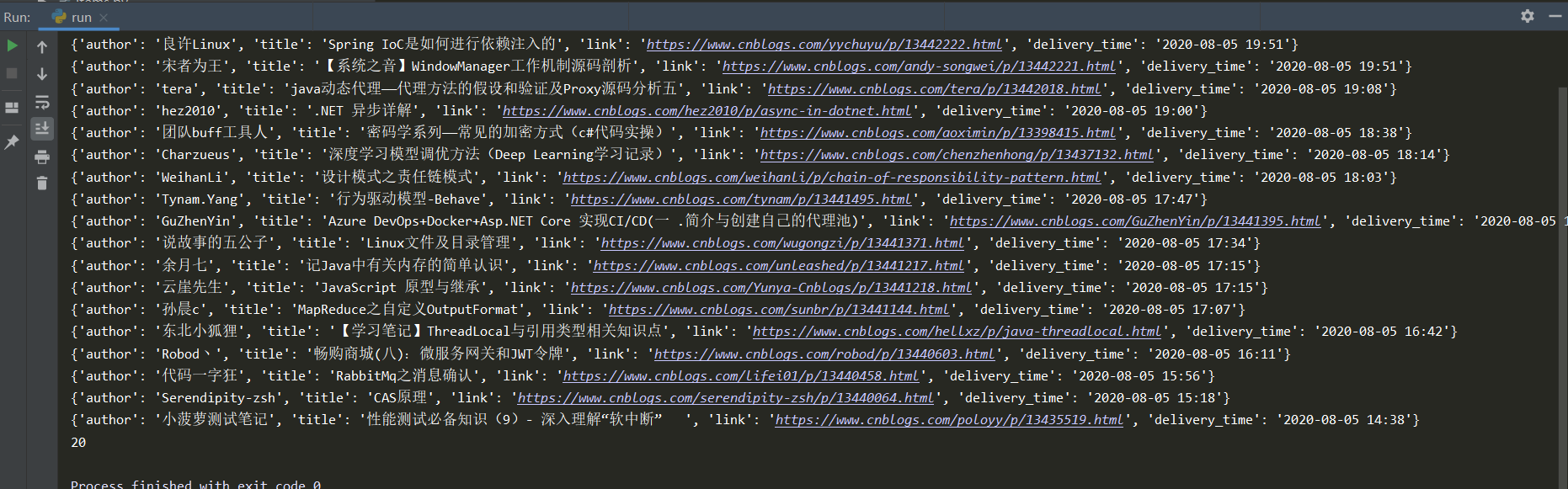
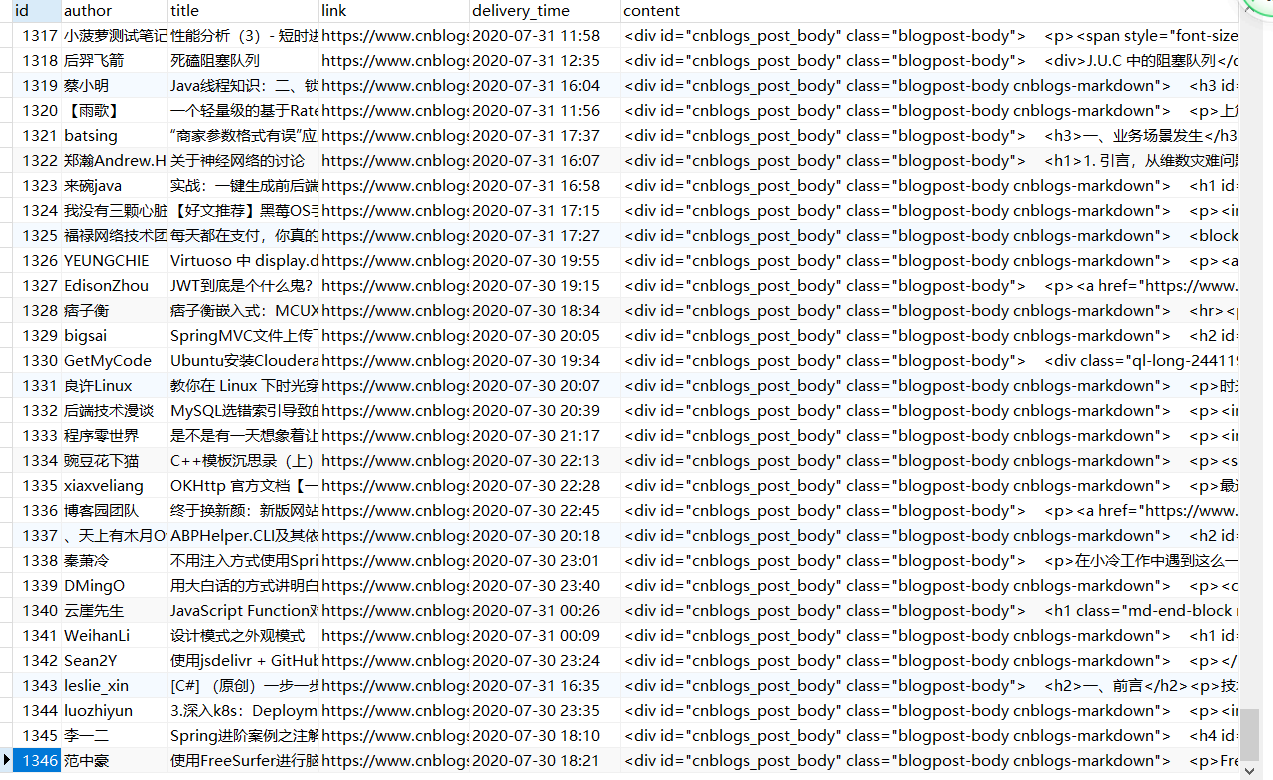
爬取cnblogs文章,把标题和连接地址打印出来
import scrapy
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs'
allowed_domains = ['www.cnblogs.com']
start_urls = ['https://www.cnblogs.com/']
def parse(self, response, **kwargs):
article_list = response.xpath('//article[@class="post-item"]')
article_info = []
for article in article_list:
article_info.append(
{
'author':article.xpath('.//a[@class="post-item-author"]/span/text()').extract_first(),
'title':article.xpath('.//a[@class="post-item-title"]/text()').extract_first(),
'link':article.xpath('.//a[@class="post-item-title"]/@href').extract_first(),
'delivery_time':article.xpath('.//span[@class="post-meta-item"]/span/text()').extract_first()
}
)
for art in article_info:
print(art)
print(len(article_info))
数据持久化
存储到MySQL数据库中
# items.py
class ArticleItem(scrapy.Item):
author = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
delivery_time = scrapy.Field()
content = scrapy.Field()
# cnblogs.py
import scrapy
from scrapy.http.request import Request
from firstscrapy.items import ArticleItem
# spider.py
import scrapy
from scrapy.http.request import Request
from firstscrapy.items import ArticleItem
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs'
allowed_domains = ['www.cnblogs.com']
start_urls = ['https://www.cnblogs.com/']
page_num = 1
items = []
def content_parse(self, response, **kwargs):
item = response.meta.get('item')
content = response.css('#cnblogs_post_body').extract_first()
item['content'] = str(content)
return item
def parse(self, response, **kwargs):
article_list = response.xpath('//article[@class="post-item"]')
for article in article_list:
item = ArticleItem()
item['author'] = article.xpath('.//a[@class="post-item-author"]/span/text()').extract_first()
item['title'] = article.xpath('.//a[@class="post-item-title"]/text()').extract_first()
item['link'] = article.xpath('.//a[@class="post-item-title"]/@href').extract_first()
item['delivery_time'] = article.xpath('.//span[@class="post-meta-item"]/span/text()').extract_first()
self.items.append(item)
if self.page_num < 20:
self.page_num += 1
next_url = f'https://www.cnblogs.com/sitehome/p/{self.page_num}'
yield Request(url=next_url, callback=self.parse)
for item in self.items:
yield Request(item['link'], meta={'item': item}, callback=self.content_parse)
自定给抽屉点赞
执行方案:
<1>先用 selenium获取用户登录的cookie
<2>再通过requests对象自动点赞
from selenium import webdriver
import time
import json
# 加载驱动
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
# 隐式等待10s
bro.implicitly_wait(10)
bro.get("https://dig.chouti.com/") # 浏览器打开抽屉
# 找到页面上的登录按钮
login_btn = bro.find_element_by_id("login_btn")
login_btn.click()
username = bro.find_element_by_name("phone")
password = bro.find_element_by_name("password")
username.send_keys("18395806407")
time.sleep(1)
password.send_keys("wang931219peng")
time.sleep(1)
button = bro.find_element_by_css_selector("button.login-btn")
button.click()
time.sleep(10)
cookie_list = bro.get_cookies()
print(cookie_list)
cookie = {}
for item in cookie_list:
cookie[item['name']] = item['value']
with open('cookie.txt',mode='w',encoding='utf-8') as fw:
fw.write(json.dumps(cookie)) # 存到文件中,也可以存到mysql或者Redis中


import requests
import json
with open('cookie.txt', mode='r', encoding='utf-8') as fr:
cookie = json.loads(fr.read())
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36',
'Referer': 'https://dig.chouti.com/'
}
res = requests.get("https://dig.chouti.com/top/24hr?_=1596712494547", headers=headers)
id_list = []
for item in res.json()['data']:
id_list.append(item['id']) # 添加id号
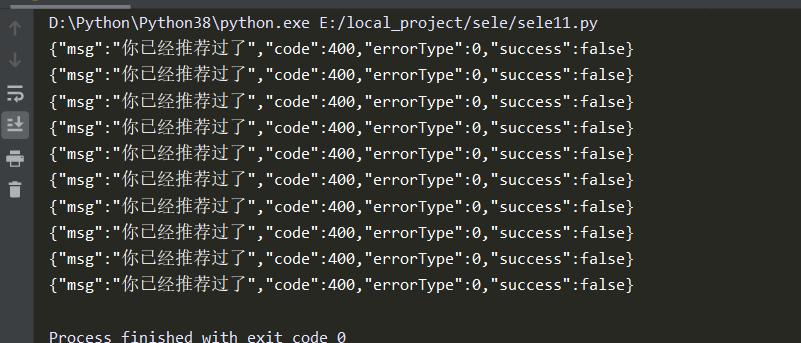
for id in id_list:
ret = requests.post('https://dig.chouti.com/link/vote', headers=headers, cookies=cookie, data={'linkId': id})
print(ret.text)
ret = requests.post(
"https://dig.chouti.com/comments/create",
headers=headers,
cookies=cookie,
data={
'content':'信春哥,得永生',
'linkId': id,
'parentId': 0
}
)
time.sleep(5)