Python之函数
标签(空格分隔): 函数
- 现在老板要求你写一个监控程序,24小时全年无休的监控你们公司的网站服务器的系统的状况,当CPU、memory、disk等指标的使用量超过阀值时即发邮件警报
- 你会采取如下的方法:

2.上述代码是实现了功能但是重复代码太多了:不易维护,如果日后需要修改发邮件的代码,就会很麻烦,每个地方都要遍历一遍;
3.因此只需要把重复的代码提取出来,放在一个公共的地方,起一个名字,以后谁想用这段代码,就通过这个名字调用就行了,如下:



例如:如下的一个简单的函数:
def syhi():#the name of def
print("hello world")
syhi()# 调用函数
- 备注:函数名是指向内存这段代码的地址,只有加上括号是执行内存里面的具体的内容;
- 另一种内容是带参数的函数:例如当你想用同一个函数,但是有些地方又是不一样的,这时候怎么办呢,就使用参数;
a=7
b=5
c=a**b
print(c)
#另一种是函数的形式:
def calc(x,y)
res=x**y
return res # return the result
c =calc(a,b)
print(c)
- 放了参数的函数在调用的时候一定要传参数,不然会报错的;
- 函数的特性:减少重复代码,使程序变的可扩展,使程序变得易于维护;
函数的默认参数
1.形参:
只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元,因此,形参只在函数内部有效,函数调用结束返回主调用函数后则不能再使用该形参变量;
2.实参:
实参可以是常量,变量,表达式,函数等,无论实参是何种类型的量,在进行函数调用的时,他们都必须有确定的值,以便把这些值传给形参,因此应预先用赋值,输入等办法使参数获得确定值;

- 形参就是一把椅子,放在这里,占个位子而已,只到有人调用,赋值的时候才会分配内存单元,在调用结束,既可释放;
- 实参,就是实实在在存在,什么类型都接受;
3.默认参数:
def stu_resgister(name,age,country,course):
print("----学生注册信息-----")
print('姓名:',name)
print('年龄:',age)
print('国家:',country)
print('课程:',course)
stu_resgister('王了',22,'china','python_devops')
stu_resgister('王了2',23,'china','python_devops')
stu_resgister('王了3',24,'china','linux')
通过上述我们可以:把国家设置为默认:
def stu_resgister(name,age,course,country='china'):
....
stu_resgister('王了3',24,'linux')
stu_resgister('王了1',24,'linux',Korean) #可以修改值
在调用时候就是默认是:China了
- 如果修改:def stu_resgister(name,age,country='china',course):铁律就是:默认参数必须要放到位置参数的后边;

关键参数:

非固定参数
例如:写个报警函数,以前发送给1个人:
def send_alert(msg,user):
print('坏了')
send_alert('赶快','xiaoA')
如果要给10个人发送呢,这里我们要调用10次;那有没有什么好的方法呢;其实很简单:
def send_alert(msg,*user):
for u in user:
print('坏了',u)
send_alert('赶快','xiaoA','xiaob','xiaoC','xiaoD')#
'xiaoA','xiaob','xiaoC','xiaoD'这些会打包发给user
1.如果参数中出现了,形参中出现了,那么传递的参数就是可变的,不是固定了,传过来的参数打包元组;一般是:args
2.方式二:*args是打包的元组,那么我是不是可以自己打包,列表和元组:例如:
send_alert('赶快',['xiaoA','xiaob','xiaoC','xiaoD'])
如果上边传的话,def send_alert(msg,user):里面的user会把:['xiaoA','xiaob','xiaoC','xiaoD']当成元祖的第一个元素(['xiaoA','xiaob','xiaoC','xiaoD'],)这样是不是打包了一次,之后,后边又打包了一次,所以这是不对的;如果按照上述传,在列表的前面加上*['xiaoA','xiaob','xiaoC','xiaoD']就可以了,这样他会直接把自己打包的传给user,('xiaoA','xiaob','xiaoC','xiaoD')
- 非固定参数的另一种形式:一种是上述的元组的形式,一种是字典的形式:
def func(name,*args,**kwargs):
print(name,args,kwargs)
func('wang',22,'nv','tester')
执行结果:wang (22, 'nv', 'tester') {}
后边有个空的字典,按照常理来说应该有些参数会放到字典里面,只是我们还没有get到这个放到里面的点,**kwargs接收的是关键字参数,指定参数名的,未定义的关键字参数;
def func(name,*args,**kwargs):
print(name,args,kwargs)
func('wang',22,'nv','tester',addr='henan',num=12341234)
执行结果:wang (22, 'nv', 'tester') {'addr': 'henan', 'num': 12341234}
def func(name,*args,**kwargs):
print(name,args,kwargs)
d={'degree':'primary school'}
func('wang',d)
执行结果为:
wang ({'degree': 'primary school'},) {}
def func(name,*args,**kwargs):
print(name,args,kwargs)
d={'degree':'primary school'}
func('wang',**d)
执行结果为:
wang () {'degree': 'primary school'}
函数的返回值:
这里形象的解释一下函数:函数就是把一堆代码,打包放在那里,比如说一个发邮件的功能,然后这个功能被调用,说到这里大家应该会想知道,我们调了,但是调的一个结果是啥?有没有成功?如果成功,干A事情,如果不成功做B的事情;
返回值的定义:函数外部的代码要想获得函数的执行结果,就可以在函数里用return语句把结果返回;
def stu_info(name,age,course='python',country='china'):
print("姓名",name)
print("年龄",age)
print("国籍",country)
print("课程",course)
if age>22:
return False #这里任何东西都可以,是你想要的结果
else:
return true
stu_status=stu_info('wang',34,course='全栈开发',country='CN')
if stu_status:
print('ok')
else:
print('not ok ')
如果没有写返回值,默认返回的是什么呢?以前的我们的代码也没有写过return都可以使用的,那以前的有返回值吗?
def stu_info(name,age,course='python',country='china'):
print("姓名",name)
print("年龄",age)
print("国籍",country)
print("课程",course)
stu_status=stu_info('wang',34,course='全栈开发',country='CN')
print(stu_status)
执行结果:
姓名 wang
年龄 34
国籍 CN
课程 全栈开发
None
其实:默认返回了None
一般带return就是为了函数的执行的结果,函数的执行的结果,一般在函数执行完毕的时候,但是看如下的代码呢?
def stu_info(name,age,course='python',country='china'):
print("姓名",name)
print("年龄",age)
print("国籍",country)
print("课程",course)
return None
print('乐乐123')
stu_status=stu_info('wang',34,course='全栈开发',country='CN')
print(stu_status)
你说上述的执行代码结果是什么?结果最后是None,还是:乐乐123
答:上述的执行结果:
姓名 wang
年龄 34
国籍 CN
课程 全栈开发
None
- 记住:函数只要碰到:return,就是函数的结束;如果未指定的return,那么这个函数的返回值为None;
def stu_info(name,age,course='python',country='china'):
print("姓名",name)
print("年龄",age)
print("国籍",country)
print("课程",course)
return None
print('乐乐123')
return 1
stu_status=stu_info('wang',34,course='全栈开发',country='CN')
print(stu_status)
这个程序呢?是返回的是:None还是1呢?
答案是:
姓名 wang
年龄 34
国籍 CN
课程 全栈开发
None
- 还是那句话,函数只要碰到:return,就是函数的结束;
还有一个问题:函数的return是只能返回一个值呢,还是可以有多个值?
def stu_info(name,age,course='python',country='china'):
print("姓名",name)
print("年龄",age)
print("国籍",country)
print("课程",course)
return name,age
stu_status=stu_info('wang',34,course='全栈开发',country='CN')
print(stu_status)
执行结果为:
姓名 wang
年龄 34
国籍 CN
课程 全栈开发
('wang', 34)
- 这里记住:函数的返回永远且只能返回一个,如果想返回多个值,要使用,号,他会把这多个值,变成一个元组,如果:return [name,age],他的结果是:['wang',34]
局部变量:
例如:我现在函数的外边定义了一个变量,然后再函数里面修改这个变量,函数外边和里面的变量有什么区别;
name='A'
def func():
name='B'
print(name)
func()
print(name)
执行结果:
B
A
这是为什么呢?
so:这就涉及到了,我们接下来要说的局部变量了,你在函数里面定义的变量就叫做局部变量;还以上述的代码为例:(具体原因我写在注释里面了)
name='A'#这里定义了一个变量
def func():
name='B'#这里你以为修改n了上边的变量,其实不是的,只是你又定义了一个name变量而已,这是两个完全独立的变量;
print(name)
func()
print(name)
如果上述表达还不清楚,我们可以进一步查看他的内存地址:
name='A'
def func():
name='B'
print(name,id(name))
func()
print(name,id(name))
执行结果:
B 6759424
A 2475104
通过上述大家可以看到内存地址是不一样的,这里应该明白了吧,这里是两个变量,只不过是名字一样而已;
- 因此说:局部变量是不能够修改全局变量的,这里的改不是改,是上述的原理是,新建;
- 同样是上述的代码,如果把局部变量消除了,函数还能打印这个name吗?
name='A'
def func():
#name='B'
print(name,id(name))
func()
print(name,id(name))
执行结果:
A 30524512
A 30524512
so:当函数局部没有对应的变量的时候,是可以调用全局变量的,但是当局部有对应的变量的时候,优先使用自己的局变量;
- 按照上述的理论反推:如果里面的能够调用外边的全局,那么外边的能够调用函数里面的局部变量吗?
答案:不能;
如果能的话,我们在第一次的代码中,就表现出来了:如果可以的话,那么如下代码的最后一个词print就应该是里面的B;但是如下代码:是报错的:NameError: name 'name' is not defined
#name='A'
def func():
name='B'
print(name,id(name))
func()
print(name,id(name))
函数里面修改全局变量:
我想在函数里面修改全局变量,但是怎么修改呢?根据以上的讲解,我在函数里面修改全局的就相当于,新建了一个变量,只是名字一样而已;
- 那么我要修改全局怎么办呢?
这里加个新的知识点:global,global name
name='A'
def func():
global name
name='B'
print(name,id(name))
func()
print(name,id(name))
执行结果:
B 4326927360
B 4326927360
所以说global就是在函数里面,修改全局变量;
- 如下代码呢?是否可行,把name修改放在global之前
name='A'
def func():
name = 'B'
global name
print(name,id(name))
func()
print(name,id(name))
执行结果:
SyntaxError: name 'name' is assigned to before global declaration
答案是不行的,不能把局部变量放在修改global之前;
- 但是以实际的开发经验而言,不建议使用global,因为这个全局变量可能会所有的人用,你自己的修改了,但是一旦运行,你的改了,实际是没有改的;一般情况下不用,只需要知道就可以了;
函数里面修改列表数据
- 我们之前只是修改了字符串,现在看看别的类型能不能行?
names=['wang','li2','qian3']
def func():
names=['wang','li2']
print(names)
func()
print(names)
执行结果:
['wang', 'li2']
['wang', 'li2', 'qian3']
那就说明和我们之前的字符串的是一样的逻辑,
- 如果我对上述的代码的names执行的是删除的操作呢?
names=['wang','li2','qian3']
def func():
del names[2]
print(names)
func()
print(names)
大家感觉执行结果是怎样的?
执行结果:
['wang', 'li2']
['wang', 'li2']
以及如下的代码:
names=['wang','li2','qian3']
def func():
del names[2]
names[1]='wanghaha'
print(names)
func()
print(names)
执行结果:
['wang', 'wanghaha']
['wang', 'wanghaha']
- 按照我们以前的理论来说:函数的内部的变量是局部变量,是不能修改的,修改就是相当于新建一个变量,可以上述的两段代码都可以修改,这是为什么呢?
解析:
1.第一次我们:在函数中:names=['wang','li2']的时候是不能修改的,因为你是对列表的整体进行重新赋值,列表的整体是一个内存地址,所以这里就不能对全局进行修改;
- del names[2]
names[1]='wanghaha'这就可以了,这是因为,你不是对整体,这是对列表的中的一个元素进行操作,列表的其中一个元素又是有一个独立的内存地址;
3.整体的内存地址不能被修改,只能被引用;
- 所以什么样的不可以被修改:字符串,数组,其余都可以;
函数的嵌套:
- 什么是嵌套,就是函数里面在搞一个函数;
def func():
print('xiao A')
def func2():
print('xiao B')
func()
1.然后问题:我执行完之后打印的是什么;
执行结果:
xiao A
2.看到上述的结果,有人会有疑问为什么呢?只有:一个执行了呢?
- 这里记住一句话,任何函数在定义完成之后,都要去通过函数的名字去调用它,如果不去调用它,是不会执行的;
def func():
print('xiao A')
def func2():
print('xiao B')
func2()
func()
执行结果:
xiao A
xiao B
- 函数内部可以在定义函数,要想执行,一定要被调用才能执行
def func():
age=82
print('xiao A',age)
def func2():
age=67
print('xiao B',age)
func2()
func()
执行结果:
xiao A 82
xiao B 67
age=14
def func():
age=73
print(age)
def func2():
print(age)
func2()
func()
执行结果:
73
73
- 上述结果可以看到:函数的变量在执行的时候,会先找寻自己的函数的变量,如果自己没有他会往上边父类的函数中查找,如果上边没有,他会去找全局变量;
如下的代码呢?
def func():
def func2():
print(age)
age=12
func2()
func()
执行结果:
12
解析上述结果:
先执行:func,然后age=12,然后执行:func2就是会使用age=12
函数-作用域:
- python 中函数就是一个作用域(javascript类似),作用域就是判断变量属于你,还是属于我;
age=18
def func():
age=13
print('wang')
def fun2():
age=84
print('mim')
- 这里给大家强调一个句话:代码定义完成后,他的作用域已经生成,作用域的关系,就是一层一层的向上查找;
匿名函数:
def calc(x,y)
return x*y
如下的一段代码和上边的代码是一样的
lambda x,y:x*y#声明了一个匿名函数;
- 但是匿名函数没有名字怎么调用呢?以前我们说过函数只有通过:函数名()这种形式被调用;
没有名字就不能被调用,现在只是一个函数而已;
print(lambda x,y : x**y)
执行结果:< function < lambda> at 0x101bcae18>
- 如果真想调用就把这个函数给他赋值给一个变量,然后在调用
例如:
func=lambda x,y : x**y
func(3,2)
执行结果:9
def calc(x,y):
if x<y:
return x*y
else:
return x/y
如果要实现上述代码的逻辑使用匿名函数可以吗?这里记住匿名函数不支持使用if,else,for循环等复杂的逻辑的,不过上述的代码我们使用匿名函数+三元运算符是可以实现的;
例如:
lambda x,y:x*y if x<y else:x/y
记住匿名函数就是把多行代码,变为一行;
- 匿名函数的作用:
需求如下:[0,1,2,3,4,5,6,7,8,9]把列表里面的数字都变为自身相乘,你应该怎么操作?
下边我们使用普通函数来实现该需求:
data=list(range(10))
print(data)
for index,i in enumerate(data):
data[index]=i*i
print(data)
怎样通过匿名实现呢?我们可以通过map()来实现
def f2(n):
return n*n
我们可以使用map(函数,参数)来实现
print(list(map(lambda x:x*x,data)))
高阶函数
- 定义:
一个函数可以接收另一个函数作为参数,这种函数就称为高阶函数;
只需要满足一下两个条件就是高阶函数:
1.接受一个或多个函数作为输入
2.return返回另外一个函数
例如:
def add(x,y,f):
return f(x)+f(y)
res =add(3,-6,abs)
print(res)
def func2(x,y):
return abs,x,y
res=func2(3,-10)
上述就是返回的时候返回了一个函数,他也是一个高阶函数;
总结:
高阶函数:主要满足:上述的1.2.两个条件都是高阶函数;
递归:
- 简单的定义:递归就是在函数的执行过程中调用自己;
def recrusion(n):
print(n)
recrusion(n+1)
recrusion(1)
执行结果为:从1 一直到998,后边还有报错,具体如下信息:
1...
994
995
996
997
998Traceback (most recent call last):
RecursionError: maximum recursion depth exceeded while calling a Python object
为什么产生,如上的结果:打印1,然后再函数里面有调用自己参数是2,依次往下推,产生了一个死循环;
- 但是为什么会有报错呢?
1.maximum recursion depth exceeded while calling a Python object,就是在调用的时候,不断的循环,超过了最大限制的次数,python就会报错,这里我们可以查看python的最大的递归限制:
import sys
print(sys.getrecursionlimit())
执行结果是:
1000
所以:以上的递归报错是因为,达到了递归的一个最大的限制;
python的最大限制的值是可以修改的:通过如上的命令:
sys.setrecursionlimit(1500)
- 为什么python会限制1000次呢?
因为:你递归1000次的时候,前面的999个还是存在的函数,是要占用一定的内存的,如果不限制,无限制的执行下去,电脑系统很快会被撑爆了,所以这里python增加了限制;
递归与栈的关系:
在Python中,递归限制最多层次,本质的原因是什么?
1.本质的原因是因为:计算机中,函数的调用是通过栈这种数据结构来实现的,在Python中不存在这种东西,栈就是类似手抢弹壳,栈的数据结构就像个弹壳一样,里面的子弹就像数据一样,栈就像一个弹壳,他和函数有什么关系?因为函数本身在执行过程中,是占有内存空间的,就是存在栈中的,你每次执行函数就像往弹壳里面压子弹一样,很快就达到了限制,如果放的多了,就会有个问题,叫栈溢出,Python解释器帮你封装了这部分东西,我们不需要关心这个;
2.每当进行一次函数调用,就会增加一个栈帧,每当函数返回,栈就会减少一层栈帧,由于栈的大小不是无限次的,所以递归调用的次数过多,会导致栈溢出;
递归的作用:
现在有个需求:10/2,直到除到0为止;
def cacl(n):
v=int(n/2)
print(v)
if v==0:
return 'Done'
cacl(v)
cacl(10)
那么如下的代码呢?
def cacl(n):
v=int(n/2)
print(v)
if v==0:
return 'Done'
cacl(v)
print(v)
cacl(10)
执行结果:
5
2
1
0
1
2
5
为什么print(v)放在递归调用函数的后边就出现了1,2,5
因为当是0的时候,最里层的函数结束了,结束后会返回到之前调用它的位置,即上一层,上一层打印的是2,再就是5,再就是10,即最外层的函数;
- 总结:这个递归就是要一层一层的进去,还要一层一层的出来;
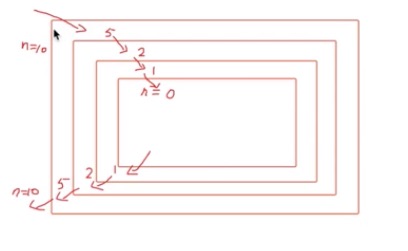
- 总结:
1.通过上边的例子:我们可以看到递归必须有一个明确的结束条件,不然就是一个死循环;
2.每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3.递归的执行效果不高,递归层次多会导致栈溢出;
- 递归有什么作用呢?
1.可以用于解决很多算法问题,把复杂的问题分成一个个小问题,--解决
2.比如求:斐波那契数列,汉诺塔,多级评论树,二分查找,求阶乘,用递归求斐波那契数列,汉诺塔,对于初学者来说,可能理解起来不是太容易,所以,我们用阶乘和二分查找来给大家演示;
递归作用:
求任何大于1的自然数n阶乘表示方法:例如:4的阶乘;
def jie(n):
if n==1:
return 1
return n*jie(n-1)
print(jie(4))
执行结果是:
24
尾递归的优化,
递归的效率低,有没有什么优化的方式呢?
这里通过一个方式叫:尾递归
答案:
def cal(n):
print(n)
return cal(n+1)
cal(1)
如上述的代码:就是一个尾递归的例子;
1.此时死循环了,但是该函数的结果是:当前return结果,没有必要在保留上次函数的结果,这就是在函数的尾部就直接返回,就是不用每次函数递归执行结果都要保留在栈里面,这种只需要保留当前的结果就好了,如果是1000次的调用,我们只用到了最后一个词的调用,其余的都直接返回了,就是类似一个弹壳,里面放一个子弹,打出一个子弹,这样就能提高效率了;
2.尾递归的优化,并不是所有的语言都支持,C语言支持,Python里面不支持尾递归;Java不支持;
函数的内置方法:
问题:在Python里面我们可以使用len()的方法,等等;
答:函数要使用是不是要先定义,len()要调用,是不是也要是有定义的;答案就是Python解释器定义好的;

1.abs()取绝对值;
2.dict()把一个数据转换成字典
3.help()帮助
4.min()从列表里面取最小的数
5.max()取最大值
6.all()判断可循环的数据,是否是全部为真,只要有个是false就是false,空列表的话返回的是True;
a=[1,2,3]
all(a)# True
a.append(0)
all(a)# 执行结果为False
7.bool()判断是否False或者True
bool(0)# 执行结果:False
8.any()可循环的数列有一个是真就是真,
any([1,4,5,-1,3,0])#执行结果:True
any([False,0])#执行结果:False
9.dirI()打印当前程序中所有存在的变量,有些是Python解释器自带的;
10.hex()把一个数转成16进制
11.slice()切片,slice(start,stop[,step])用处不大,自行研究
12.divmod()求整除(x//y,x%y)
divmod(10,3)# 执行结果:3,1
13.sorted()
l=[1,3,4,5,2,55,22]
print(sorted(l))
d={}
for i in range(20):
d[i]=i-50
print(d) #结果是乱序的,如果想排序怎么办呢?变成列表呗
print(d.items())
#如果想按照values排序呢?
d2=d.items()
#这样排序不知道是values还是key
print(sorted(d.items()))
print(sorted(d.items(),key=lambda x:x[1]))
d[0]=399
print(sorted(d.items(),key=lambda x:x[1],reverse=True))
以上是sorted()一些列子,大家自行研究己试试
14.ascii()是不是ASCII编码,没有什么作用
a='abc中卫'
print(ascii(a))
执行结果:
'abcu4e2du536b'
15.oct()变成八进制
16.eval()把zi'fu字符串转换成为公式;
f='1+3/2'
#我想做的是,把这个字符串读出来,做成公式,这里我们可以通过eval
print(eval(f))
code ='''
if 3>5:
print('3 bigger 5')
else:
print('dddd')
'''
print(eval(code))#查看报错我们得出结论eval能做的事情只能是处理单行的代码
17.exec()这个和eval()作用是一样的,exec能处理多行
code =''
if 3>5:
print('3 bigger 5')
else:
print('dddd')
''
print(exec(code))
执行结果:
dddd
None
- exec()和eval()的区别:
code =''
def foo():
print('run foo')
return 1234
foo()
''
print(exec(code))
执行结果:
run foo
None
这里看到exec是拿不到返回值的,eval是可以的:
res=eval('1+2+3')
res2=exec('1+2+3+4')
print(res,res2)
执行结果:
6 None
18.ord()
ord('a')#返回a在ascci码对应的位置;97
chr(98)#根据值查找ascii对应的内容:b
19.sum()求和
20.bytearray(),直接修改字符串内容,原内存地址修改,不是开辟一个内存空间;
s='43'
s[0]=88
执行结果:
TypeError: 'str' object does not support item assignment
- 我们要想修改字符串怎么办呢?
s='abcd中国'
s=bytearray(s,encoding='utf-8')
s[0]=98
print(s[0])
s[0]=65
print(s[0])
执行结果:
98
65
21.map()接收两个参数,一个是函数,一个是序列;
map(lambda x:x*x ,[1,2,3,4,5])
a=list(map(lambda x:x*x ,[1,2,3,4,5]))
print(a)
执行结果:
[1, 4, 9, 16, 25]
22.filter()把符合条件的值过滤出来,快速从一个列表里面找到你想要的值;当这个:lambda x:x>3为True,就从列表里面拿出来结果来,如下的代码
print(list(filter(lambda x:x>3,[1,2,3,4,5,6,7])))
执行结果:
[4, 5, 6, 7]
23.reduce(),map(),filter()被称为三剑客,reduce(),Python2有,Python3放到别的地方了,functiontools里面了;
import functools
#所有的值加起来;
functools.reduce(lambda x,y:x+y,[1,2,3,4,5,6677,9])
functools.reduce(lambda x,y:x*y,[1,2,3,4,5,6677,9])
functools.reduce(lambda x,y:x+y,[1,2,3,4,5,6677,9],3)#有索引值,从哪里开始的
24.pow()求多少次方
25.print()打印
help(print)
print(value, ..., sep=' ', end='
', file=sys.stdout, flush=False)
s='hey,myname is alex
,from shandong'
print(s)
print(s,end=',')
print(s,sep='')
print('niniou','hellowor')
print('niuniu','douniu',sep='-->')
执行结果:
hey,myname is alex
,from shandong
hey,myname is alex
,from shandong,hey,myname is alex
,from shandong
niniou hellowor
niuniu-->douniu
通过上述的执行结果可以看到,print的一些方法的用处;
- print 最后是有换行的;
26.callable()判断一个东西是否可调用;
27.vars()打印当前的所有的变量和变量的值
28.locals()打印函数的所有的局部变量
def f():
n=3
print(locals())
f()
29.round()保留几位小数;
30.hash()把字符创变为数字;
函数的进阶:
- 名称空间
1.又名name space,顾明思议,就是存放名字地方,存什么名字?举例说明:x=1,1存放在内存中,那么名字x存放在哪里呢?名称空间是存放名字x与1绑定关系的地方;
名称空间的共有3种,分别如下:
1.locals:是函数内的名称空间,包括局部变量和形参
2.globals:全局变量,函数定义所在模块的名字空间
3.builtins:内置模块的名字空间;
不同变量的作用域不同,就是由这个变量所在的命名空间决定的
作用域即范围:- 全局范围:全局存活,全局有效
- 局部范围:临时存活,局部有效
查看作用域的方法:globals(),locals()
闭包
- 闭包的定义:
个人总结:
闭包:就是内部函数使用了外部函数的变量,同时外部函数的返回值是内层的函数的内存地址,在我们调用外部函数的时候,其实得出的结果是内部函数的内存地址,这种内部函数和外部函数的相互使用,纠缠的关系,就叫做闭包;
def fun1():
n=10
def fun2():
print(n)
return fun2
f=fun1()
print(f)
f()
执行结果:
< function func.
10
从上述的代码可以看出:
print(f)其实打印的结果是:fun2的内存地址,而f()实际打印的是fun1的局部变量;
- 上述案例的分析:
这里代码的最终执行的是fun2,打印的是确实fun1的局部变量,理论在fun1()这个函数调用以后,内部的变量就应该释放掉,这样我们打印的n就应该是不存在的,但是执行的时候是存在的;这个和之前学的函数调用之后,局部变量就释放了,这个理论是有矛盾的,以前说过,局部变量临时有效,执行就有,不执行就没有,但是为什么释放了,为什么还能用呢,这就是闭包,闭包就是为了解释这种现象;
装饰器
你是一家视频网站的后端开发工程师,你们网站有以下几个版块
def home():
print("---首页----")
def Love():
print("----爱情片----")
def KongBu():
print("----恐怖片----")
def CityLife():
print("----都市生活----")
视频刚上线初期,为了吸引用户,你们采取了免费政策,所有视频免费观看,迅速吸引了一大批用户,免费一段时间后,想收费得先让其进行用户认证,认证通过后,再判定这个用户是否是VIP付费会员就可以了,是VIP就让看,不是VIP就不让看就行了呗。 你觉得这个需求很是简单,因为要对多个版块进行认证,那应该把认证功能提取出来单独写个模块,然后每个版块里调用 就可以了,于是就开始了 。
user_status=False #用户登录了把这里改为True
def login():
_username='wang'#假如这是DB里面的用户名、
_password='abc123'#假如这是DB里面存的用户名
global user_status
if user_status==False:
username=input("user:")
password=input("password")
if username==_username and password==_password:
print("please login")
user_status=True
else:
print("the wrong usernam or password")
else:
print("用户已经登录验证通过 ")
def home():
print("---首页----")
def Love():
login()#执行之前加上验证
print("----爱情片----")
def KongBu():
print("----恐怖片----")
def CityLife():
login()#执行之前加上验证
print("----都市生活----")
Love()
CityLife()
如果现在有很多模块需要加认证模块,你的代码虽然实现了功能,但是需要更改需要加认证的各个模块的代码,这直接违反了软件开发中的一个原则“开放-封闭”原则,简单来说,它规定已经实现的功能代码不允许被修改,但可以被扩展,即:
封闭:已实现的功能代码块不应该被修改
开放:对现有功能的扩展开放;
- 如何在不改原有功能代码的情况下加上认证功能呢?
依然记得:我们以前学习的高阶函数,就是把一个函数当做一个参数传给另外一个函数,当时说,有一天,你会用到它的,没想到这时这个知识点突然从脑子里蹦出来了,我只需要写个认证方法,每次调用需要验证的功能时,直接把这个功能的函数名当做一个参数传给我的验证模块不就行了么?
user_status=False
def login(func):
_username='wang'#假如这是DB里面的用户名、
_password='abc123'#假如这是DB里面存的用户名
global user_status
if user_status==False:
username=input("user:")
password=input("password")
if username==_username and password==_password:
print("please login")
user_status=True
else:
print("the wrong usernam or password")
else:
print("用户已经登录验证通过 ")
if user_status==True:
func()#只要通过了就调用相应的功能;
def home():
print("---首页----")
def Love():
print("----爱情片----")
def KongBu():
print("----恐怖片----")
def CityLife():
print("----都市生活----")
login(Love)#把需要认证的模块当做参数传给login()
login(CityLife)
执行结果:
user:wang
password:abc123
please login
----爱情片----
用户已经登录验证通过
----都市生活----
- 问题:上述功能实现了,有没有什么不妥的地方?你功能是实现了,但是你又犯了一个大忌,什么大忌?
你改变了调用方式呀,想一想,现在没每个需要认证的模块,都必须调用你的login()方法,并把自己的函数名传给你,人家之前可不是这么调用的,试想,如果有100个模块需要认证,那这100个模块都得更改调用方式,这么多模块肯定不止是一个人写的,让每个人再去修改调用方式才能加上认证,你会被骂死的。。。。
- 还记的我们之前学习的匿名函数吗?
def plus(n):
return n+1
plus2 = lambda x:x+1
其实这两个的效果是一样的;
这里我们给lambda x:x+1起了个名字叫plus2,是不是相当于def plus2(x) ?
答案:是的
这里只想告诉我们,给函数赋值变量名就像def func_name是一样的效果,如下面的plus(n)函数,你调用时可以用plus名,还可以再起个其它名字,如:
calc = plus
calc(n)
- 你明白我想传达什么意思了么?
如下:之前我们写的需要认证的代码:
login(Love)#把需要认证的模块当做参数传给login()
login(CityLife)
你之所改变了调用方式,是因为用户每次调用时需要执行login(CityLife),类似的。其实稍一改就可以了呀
Love=login(Love)#把需要认证的模块当做参数传给login(),然后在赋值给自己的模块的名字;
CityLife=login(CityLife)
这样以来,其它人调用Love时,其实相当于调用了login(Love), 通过login里的验证后,就会自动调用Love的功能。
Love=login(Love) #你在这里相当于把Love这个函数替换了
CityLife=login(CityLife)#你在这里相当于把CityLife这个函数替换了
#那用户调用时依然可以写
Love()
CityLife()
但是上述代码有一个问题:还不等用户调用Love(),这里的:Love=login(Love),都已经执行完了,怎样才能实现,当用户掉用的时候才会执行呢?
1.之前我们有学过:函数的嵌套,现在我们可以在login函数里面增加一个inner()然后让login(func)返回的是,inner的内存地址,这样我们在Love=login(Love)的时候,就得到的结果其实就是inner的内存地址,然后用户在调用Love()的时候,才会真的去验证这个认证需求;
user_status=False
def login(func):
def inner():#定义一个内部函数
_username='wang'#假如这是DB里面的用户名、
_password='abc123'#假如这是DB里面存的用户名
global user_status
if user_status==False:
username=input("user:")
password=input("password")
if username==_username and password==_password:
print("please login")
user_status=True
else:
print("the wrong usernam or password")
else:
print("用户已经登录验证通过 ")
if user_status==True:
func()#只要通过了就调用相应的功能;
return inner#在调用login(func)这个函数的时候,返回的是inner的一个内存地址;
def home():
print("---首页----")
def Love():
print("----爱情片----")
def KongBu():
print("----恐怖片----")
def CityLife():
print("----都市生活----")
Love=login(Love)#把需要认证的模块当做参数传给login(),当login(Love)其实得到的是inner的一个内存地址
CityLife=login(CityLife)#把需要认证的模块当做参数传给login(),当login(Love)其实得到的是inner的一个内存地址
Love()#相当于inner()
CityLife()
如果所有的都要按照上述的代码写,会很冗余,python针对这种情况有自己专门的书写格式:在需要认证的函数上边加一行@login,其实是和:Love=login(Love)效果是一样的;所以代码可以这么写:
user_status=False
def login(func):
def inner():#定义一个内部函数
_username='wang'#假如这是DB里面的用户名、
_password='abc123'#假如这是DB里面存的用户名
global user_status
if user_status==False:
username=input("user:")
password=input("password")
if username==_username and password==_password:
print("please login")
user_status=True
else:
print("the wrong usernam or password")
else:
print("用户已经登录验证通过 ")
if user_status==True:
func()#只要通过了就调用相应的功能;
return inner#在调用login(func)这个函数的时候,返回的是inner的一个内存地址;
def home():
print("---首页----")
@login #认证的装饰器
def Love():
print("----爱情片----")
def KongBu():
print("----恐怖片----")
@login #认证的装饰器
def CityLife():
print("----都市生活----")
Love()
CityLife()
如果我们给函数传入参数:Love('beijing');
TypeError: inner() takes 0 positional arguments but 1 was given;
如上述的结果会报错:why?
- 这里大家思考一下:我们在第一次调用:Love的时候,是不是相当于Love=login(Love),结果相当于inner的内存地址,第二次:Love()的时候,才是相当于走了inner()函数的调用,但是我们可以看出inner()里面没有传入参数,所以会报错的;
- 如果要支持,传入参数:也不是不可以这里直接稍微修改一下就可以了:
user_status=False
def login(func):
def inner(*args,**kwargs):#定义一个内部函数并且添加参数
_username='wang'#假如这是DB里面的用户名、
_password='abc123'#假如这是DB里面存的用户名
global user_status
if user_status==False:
username=input("user:")
password=input("password")
if username==_username and password==_password:
print("please login")
user_status=True
else:
print("the wrong usernam or password")
else:
print("用户已经登录验证通过 ")
if user_status==True:
func(*args,**kwargs)#只要通过了就调用相应的功能,添加参数,传到相应的版块;
return inner#在调用login(func)这个函数的时候,返回的是inner的一个内存地址;
def home():
print("---首页----")
@login #认证的装饰器
def Love(arg):
print("----爱情片----")
def KongBu():
print("----恐怖片----")
@login #认证的装饰器
def CityLife(arg):
print("----都市生活----")
Love('beijing')
CityLife('shanghai')
如果用户需求是:
增加对QQ,微博,等登录的验证:
user_status = False
def login(auth_type):
def auth(func):
def inner(*args, **kwargs): # 定义一个内部函数并且添加参数
_username = 'wang' # 假如这是DB里面的用户名、
_password = 'abc123' # 假如这是DB里面存的用户名
global user_status
if user_status == False:
username = input("user:")
password = input("password")
if username == _username and password == _password:
print("please login")
user_status = True
else:
print("the wrong usernam or password")
else:
print("用户已经登录验证通过 ")
if user_status == True:
func(*args, **kwargs) # 只要通过了就调用相应的功能,添加参数,传到相应的版块;
return inner # 在调用login(func)这个函数的时候,返回的是inner的一个内存地址;
return auth
def home():
print("---首页----")
@login('qq') # 认证的装饰器
def Love(arg):
print("----爱情片----")
def KongBu():
print("----恐怖片----")
@login('weibo') # 认证的装饰器
def CityLife(arg):
print("----都市生活----")
Love('beijing')
CityLife('shanghai')