最近在啃jQuery1.11源码,上来就遇到Sizzle这个jQuery的大核心,虽然已经清楚了Sizzle的用途,先绕过去也没事,但明知山有虎偏向虎山行才是我们要做的。
本文面向的阅读对象:正在学习Sizzle源码或有一定前端基础的同学们,可以一边看源码一边看这些文章进行验证,所以虽然我会分析源码中的正则表达式,有大量的注释,但不会讲正则表达式的基本用法!(我会给出一些链接,但不一定全面,请锻炼自主搜索的能力;为了避免歧义,本文的一些词会采用源码中的英文或js中的属性名)
Sizzle部分的代码已经啃完,本系列还有后续,这几天将会一一放出。本文主要分为两个部分:什么是Sizzle、Sizzle的原理以及Sizzle结构概览
什么是Sizzle?
简单地来说,Sizzle是一个可以让你用CSS 选择器(selector)形式去获取DOM元素的引擎。
当我们想了解一个函数的用途和源码,必须先看它的要求和效果,就是输入和输出。
例如:你提供一个CSS selector 'html > body',Sizzle会返回给你一个数组,数组中只有一个元素body元素。
还有更复杂的CSS selector,比如 ‘body > div#main div.content input[type="text"]:nth(2)’,更多selector的用法请看
Sizzle的原理
我们先想想,如果让我们自己写一个Sizzle,先不考虑其中遇到的设计和细节问题,你会怎么做?
一个很自然的想法是,从父元素顺藤摸瓜往下一层层找下去。比如‘html > body’,我先找到nodeName为html的元素,再查看html的子元素里有没有一个nodeName为body的元素即可。
那么会面对几个问题:
你怎么知道在哪儿找html元素?于是我们需要一个查找上下文(context),默认为文档节点(document)
你怎么知道要找的是html元素而非h元素或者ht元素?所以我们需要一个词法分析器(tokenize),把selector切成三个词元(token)(一个数组(tokens)),[‘html’,'>','body']。(关于词法分析器,请学习编译原理相关知识)
难道处理‘html’和处理‘>’的方式是一样的?你怎么知道它要查找子元素?我们知道它们是不同的类型的词元(token),所以要记录词元的类型,上面的数组变为[{value:'html',type:'TAG'},{value:'>',type:'>'},{value:'body',type:'TAG'}],再交给对应的处理函数处理
难道每次我们都来上面这么一套么?我们经常用的不就是$('#id')或者$('.className')这样简单的用法么?所以我们可以把这种高频率的特殊情况拿出来先处理,处理不掉再用统一的方法处理。
上面这一套,从左往右匹配,从逻辑上来看是没什么问题的。那么思考下面这种情况:
‘因为DOM是一种树形结构,所以越往下层,子节点是越多的,那么会有这样一种情况,body元素下有10000个div子元素,其中在5000的位置处有一个div的id为suprise。’这时给你一个内容为body > div#suprise的selector,你写的引擎会怎么处理?
继续用上面的方法,先找出body元素,然后一个个遍历body的子元素?
可以预见的是性能上的悲剧。。。
所以我们的Sizzle采用的是从右向左的匹配方式:
先调用getElementById('suprise')来获得该DOM元素(find过程)(因为浏览器低层目测会建立id的索引,所以获得非常快,即使需要遍历DOM树,也比我们自己遍历DOM树快),
再根据'>'判断其父元素是否是body元素(filter过程)即可。
OK,到这里为止性能方面有了一定的改进,再考虑一种情况:
'当我们需要查找的层次很深时,比如selector为body > div#main div.content input[type="text"]时,我们需要先找到待选(seed)的input,再依次过滤[type="text"]、div.content 、div#main 、body>,你们会怎么做?'
判断不同的token类型,再通过查找找到对应的过滤函数,并调用对应的过滤函数(filter),这是一个正常的想法。
那么我需要再用该selector来查找一次呢?(这是使用jQuery非常常见的场景)把上面的过滤过程再重复一遍?
于是另一种提升性能的方式出现了——缓存,把上面的多个过滤函数编译成一个匹配函数(matcher),然后以key-value的形式存在缓存里面,当我们再次查找同样的selector时,只需要把编译好的匹配函数(matcher)给取出来过滤用就可以了。
Sizzle的全部原理大致如上,至于特性检测、沙盒、bugfix这些细节,后面再说
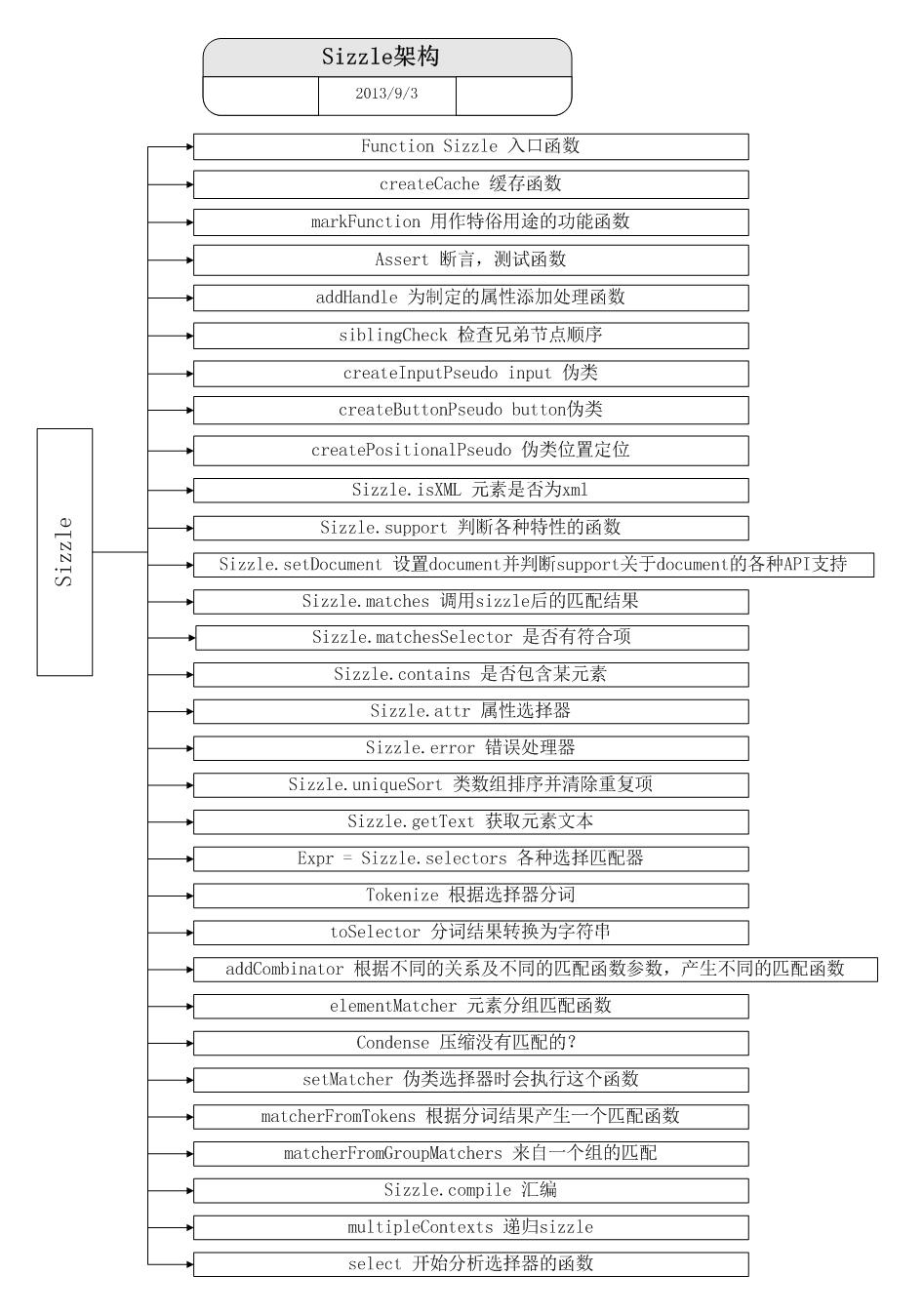
Sizzle的结构概览
Sizzle的结构不用记,大致看看就好,后面会一一说到的,放一张图,来源:http://www.cnblogs.com/mufc-go/p/3299261.html
本文完。
剩下的下午健完身回来再发。
感谢@司徒正美(1.3版本源码分析),@nuysoft(1.7版本源码分析),@Aaron(2.03版本源码分析)给我的参考。
如果你喜欢这篇文章,请给我一个推荐,如果觉得有问题,请在评论里抽打我!