音频处理有以下几个模块:
1.降噪NS
2.回音消除aec
3.回声控制acem
4.音频增益agc
5.静音检测
1.降噪NS -noice_suppression.h

原理:
维纳滤波原理
输入信号通过一个线性时不变系统之后产生一个输出信号,使得输出信号尽量逼近期望信号,使其估计误差最小化,
能够最小化这个估计误差的最优滤波器称为维纳滤波器。
基本思想:
对接收到的每一帧带噪语音信号,以对该帧的初始噪声估计为前提,定义语音概率函数,测量每一帧带噪信号的分类特征,使用测量出来的分类特征,计算每一帧基于多特征的语音概率,在对计算出的语音概率进行动态因子(信号分类特征和阈值参数)加权,根据计算出的每帧基于特征的语音概率,修改多帧中每一帧的语音概率函数,以及使用修改后每帧语音概率函数,更新每帧中的初始噪声(连续多帧中每一帧的分位数噪声)估计.
特征值
频谱平坦度计算(Compute Spectral Flatness)
假设语音比噪声有更多的谐波,语音频谱往往会在基频(基音)和谐波中出现峰值,噪声相对平坦。
计算公式:
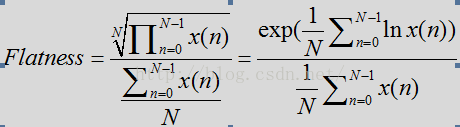
N:STFT后频率点数
B:频率带数量
K:频点指数
j:频带指数
每个频带有大量频率点,128个频率点可分成4个频带(低带,中低频带,中高频带,高频),每个频带32个频点
对于噪声Flatness偏大且为常数,而对于语音,计算出的数量则偏下且为变量。
对应代码:计算特征数据光谱平坦度featuredata[0]
// Compute spectral flatness on input spectrum 计算 // magnIn is the magnitude spectrum // spectral flatness is returned in inst->featureData[0] void WebRtcNs_ComputeSpectralFlatness(NSinst_t* inst, float* magnIn) { int i; int shiftLP = 1; //option to remove first bin(s) from spectral measures float avgSpectralFlatnessNum, avgSpectralFlatnessDen, spectralTmp; // comute spectral measures // for flatness 跳过第一个频点,即直流频点Den是denominator(分母)的缩写,avgSpectralFlatnessDen是上述公式分母计算用到的 avgSpectralFlatnessNum = 0.0; avgSpectralFlatnessDen = inst->sumMagn; for (i = 0; i < shiftLP; i++) { avgSpectralFlatnessDen -= magnIn[i]; } // compute log of ratio of the geometric to arithmetic mean: check for log(0) case //TVAG是time-average的缩写,对于能量出现异常的处理。利用前一次平坦度直接取平均返回。 for (i = shiftLP; i < inst->magnLen; i++) { if (magnIn[i] > 0.0) { avgSpectralFlatnessNum += (float)log(magnIn[i]); } else { inst->featureData[0] -= SPECT_FL_TAVG * inst->featureData[0]; return; } } //normalize avgSpectralFlatnessDen = avgSpectralFlatnessDen / inst->magnLen; avgSpectralFlatnessNum = avgSpectralFlatnessNum / inst->magnLen; //ratio and inverse log: check for case of log(0) spectralTmp = (float)exp(avgSpectralFlatnessNum) / avgSpectralFlatnessDen; //time-avg update of spectral flatness feature inst->featureData[0] += SPECT_FL_TAVG * (spectralTmp - inst->featureData[0]); //inst->featureData[0] +=0-SPECT_FL_TAVG * inst->featureData[0] // done with flatness feature }
代码逻辑

Compute Spectral Difference 计算频谱差异
假设:噪声频谱比语音频谱更稳定,因此,假设噪声频谱体形状在任何给定阶段都倾向于保持相同,
此特征用于测量输入频谱与噪声频谱形状的偏差。
通过相关系数计算差异性
相关系数计算:cov(x,y)^2/(D(x)D(Y))
代码:// Compute the difference measure between input spectrum and a template/learned noise spectrum
// magnIn is the input spectrum // the reference/template spectrum is inst->magnAvgPause[i] // returns (normalized) spectral difference in inst->featureData[4] void WebRtcNs_ComputeSpectralDifference(NSinst_t* inst, float* magnIn) { // avgDiffNormMagn = var(magnIn) - cov(magnIn, magnAvgPause)^2 / var(magnAvgPause) int i; float avgPause, avgMagn, covMagnPause, varPause, varMagn, avgDiffNormMagn; avgPause = 0.0; avgMagn = inst->sumMagn; // compute average quantities for (i = 0; i < inst->magnLen; i++) { //conservative smooth noise spectrum from pause frames avgPause += inst->magnAvgPause[i]; }
avgPause = avgPause / ((float)inst->magnLen); avgMagn = avgMagn / ((float)inst->magnLen); covMagnPause = 0.0; varPause = 0.0; varMagn = 0.0; // compute variance and covariance quantities
// covMagnPause 协方差 varPause varMagn 各自的方差
for (i = 0; i < inst->magnLen; i++) { covMagnPause += (magnIn[i] - avgMagn) * (inst->magnAvgPause[i] - avgPause); varPause += (inst->magnAvgPause[i] - avgPause) * (inst->magnAvgPause[i] - avgPause); varMagn += (magnIn[i] - avgMagn) * (magnIn[i] - avgMagn); } covMagnPause = covMagnPause / ((float)inst->magnLen); varPause = varPause / ((float)inst->magnLen); varMagn = varMagn / ((float)inst->magnLen); // update of average magnitude spectrum inst->featureData[6] += inst->signalEnergy; //计算相关系数 avgDiffNormMagn = varMagn - (covMagnPause * covMagnPause) / (varPause + (float)0.0001); // normalize and compute time-avg update of difference feature 归一化 avgDiffNormMagn = (float)(avgDiffNormMagn / (inst->featureData[5] + (float)0.0001)); inst->featureData[4] += SPECT_DIFF_TAVG * (avgDiffNormMagn - inst->featureData[4]); }
Compute SNR
根据分位数噪声估计计算前后信噪比。
后验信噪比:观测到的能量与噪声功率相关输入功率相比的瞬态SNR:
Y:输入含有噪声的频谱
N:噪声频谱
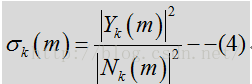
先验SNR是与噪声功率相关的纯净信号功率的期望值
X:输入的纯净信号(语音信号)
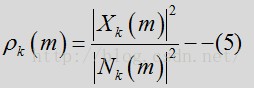
webrtc实际计算采用数量级而非平方数量级
纯净信号是未知信号,先验 SNR的估计是上一帧经估计的先验SNR和瞬态SNR的平均值
ydd:时间平滑参数 值越大 流畅度越高 延迟越大
H:smooth 上一帧的维纳滤波器
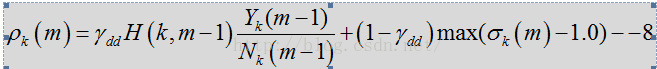
相关代码计算snrloc snrpri snrlocpost
1011 // directed decision update of snrPrior 1012: snrLocPrior[i] = DD_PR_SNR * previousEstimateStsa[i] + ((float)1.0 - DD_PR_SNR)* snrLocPost[i]; 1013 // post and prior snr needed for step 2 1106 // directed decision update of snrPrior 1107: snrPrior = DD_PR_SNR * previousEstimateStsa[i] + ((float)1.0 - DD_PR_SNR) 1108 * currentEstimateStsa;
lrt因素平均值 feature[3]
// compute feature based on average LR factor // this is the average over all frequencies of the smooth log lrt logLrtTimeAvgKsum = 0.0; for (i = 0; i < inst->magnLen; i++) { tmpFloat1 = (float)1.0 + (float)2.0 * snrLocPrior[i]; tmpFloat2 = (float)2.0 * snrLocPrior[i] / (tmpFloat1 + (float)0.0001); besselTmp = (snrLocPost[i] + (float)1.0) * tmpFloat2; inst->logLrtTimeAvg[i] += LRT_TAVG * (besselTmp - (float)log(tmpFloat1) - inst->logLrtTimeAvg[i]); logLrtTimeAvgKsum += inst->logLrtTimeAvg[i]; } logLrtTimeAvgKsum = (float)logLrtTimeAvgKsum / (inst->magnLen); inst->featureData[3] = logLrtTimeAvgKsum; // done with computation of LR factor
/* * Copyright (c) 2012 The WebRTC project authors. All Rights Reserved. * * Use of this source code is governed by a BSD-style license * that can be found in the LICENSE file in the root of the source * tree. An additional intellectual property rights grant can be found * in the file PATENTS. All contributing project authors may * be found in the AUTHORS file in the root of the source tree. */ #ifndef WEBRTC_MODULES_AUDIO_PROCESSING_NS_INCLUDE_NOISE_SUPPRESSION_H_ #define WEBRTC_MODULES_AUDIO_PROCESSING_NS_INCLUDE_NOISE_SUPPRESSION_H_ #include "typedefs.h" typedef struct NsHandleT NsHandle; #ifdef __cplusplus extern "C" { #endif /* * This function creates an instance to the noise suppression structure * * Input: * - NS_inst : Pointer to noise suppression instance that should be * created * * Output: * - NS_inst : Pointer to created noise suppression instance * * Return value : 0 - Ok * -1 - Error */
//输入应创建的降噪实例指针,输出已创建的降噪实例指针,返回成功获失败
int WebRtcNs_Create(NsHandle** NS_inst); /* * This function frees the dynamic memory of a specified noise suppression * instance. * * Input: * - NS_inst : Pointer to NS instance that should be freed * * Return value : 0 - Ok * -1 - Error */
//释放降噪指针空间
int WebRtcNs_Free(NsHandle* NS_inst); /* * This function initializes a NS instance and has to be called before any other * processing is made. * * Input: * - NS_inst : Instance that should be initialized * - fs : sampling frequency * * Output: * - NS_inst : Initialized instance * * Return value : 0 - Ok * -1 - Error */
//初始化降噪实例、采样率,在其他处理之前调用
int WebRtcNs_Init(NsHandle* NS_inst, uint32_t fs); /* * This changes the aggressiveness of the noise suppression method. * * Input: * - NS_inst : Noise suppression instance. * - mode : 0: Mild, 1: Medium , 2: Aggressive * * Output: * - NS_inst : Updated instance. * * Return value : 0 - Ok * -1 - Error */
//设置降噪级数
输入:需要进行噪声处理的实例、降噪级数
输出:处理后的实例
mode 0:轻度,1:中度,2:重度
//
int WebRtcNs_set_policy(NsHandle* NS_inst, int mode); /* * This functions does Noise Suppression for the inserted speech frame. The * input and output signals should always be 10ms (80 or 160 samples). * * Input * - NS_inst : Noise suppression instance. * - spframe : Pointer to speech frame buffer for L band * - spframe_H : Pointer to speech frame buffer for H band * - fs : sampling frequency * * Output: * - NS_inst : Updated NS instance * - outframe : Pointer to output frame for L band * - outframe_H : Pointer to output frame for H band * * Return value : 0 - OK * -1 - Error */
//对插入的语音帧进行处理,输入和输出信号总保持在10ms长度
//采样个数为80/160
//输入噪声消除实例 ,L波段语音帧缓冲区的指针,H波段的语音帧缓冲区指针,各自对应的输出指针
int WebRtcNs_Process(NsHandle* NS_inst, short* spframe, short* spframe_H, short* outframe, short* outframe_H); /* Returns the internally used prior speech probability of the current frame. * There is a frequency bin based one as well, with which this should not be * confused. * * Input * - handle : Noise suppression instance. * * Return value : Prior speech probability in interval [0.0, 1.0]. * -1 - NULL pointer or uninitialized instance. */
//返回当前帧使用先前语音的概率 输入实例,返回概率
float WebRtcNs_prior_speech_probability(NsHandle* handle); #ifdef __cplusplus } #endif #endif // WEBRTC_MODULES_AUDIO_PROCESSING_NS_INCLUDE_NOISE_SUPPRESSION_H_
参考:https://blog.csdn.net/godloveyuxu/article/details/73657931