kafka作为消息中间件和大数据相关的系统联系非常密切。其实,对于kafka本身而言,它已不仅仅定位于消息中间件,从0.10开始,kafka提供了Stream(KQL)计算功能,开始有了实时处理能力。由于目前kafka主要还是作为消息中间件来使用,所以当前对kafka相关原理的研究也主要集中在消息队列这块。本文将会对kafka一些重要的原理和重要组件做一个一般性的介绍。
1,Kafka整体架构
Kafka的整体架构图如下,由Producer,Broker和Consumer组成。broker的controller选举,broker的上下线,topic的管理(删除,创建),以及replication的管理等都需要借助zookeeper来实现,而Consumer在消费过程中,可以将消费的进度消息保存到zookeeper(另外,也可以不通过zookeeper,将消费相关进度信息保存到Kafka内置的__consumer_offset这个topic中)。

从生产消费角度看:生产者(producer)可以写入消息到指定的topic。而消费有消费组合消费者的概念,一个topic可以有多个消费组,而一个消费组又可以有多个消费者。不同的消费组可以同事消费topic里面同一个消息,而同一个消息只能由一个消费组下面的某一个消费者消费。在0.8版本中,Kafka client API是scala写的,而在新的kafka版本中(0.9+)已经改成了Java实现。另外,从以上架构图中也可以看出,从部署的角度看,kafka server端的整体架构是类似于P2P的,而不像当前主流的master salve机构。
2,LogManager
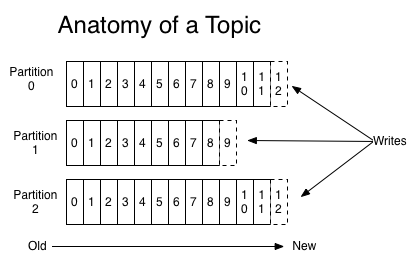
如下图,在Kafka中,逻辑上的topic可以从物理上被划分为多个partition来进行存储(具体多少个partition可以在创建topic的时候指定,或者创建后扩容,但是不能缩容)。每个partition当broker中有一个单独的目录,在这个partition目录中,在0.10版本包含三种文件:保存数据的log文件(log结尾),以及offset索引(index结尾)和时间索引文件(timeindex结尾)。
在同一个parition目录下,可以有多个segment(即log)文件,文件以offset number命名,如下图的xxx0368769.log文件,这个数字是上一个segment文件最后一条消息的逻辑offset的值,也就是说当前文件的最开始的一条记录的逻辑offset是当前文件名numbert加1。而在索引(index)文件中,保存着当前文件中消息序号和实际文件offset的索引,如下图中的6,1407表示的是当前文件中第6条信息的文件offset是1407,如果要读取这条消息只需要seek到该位置即可。

了解了以上存储结构,对于给定的partition的offset,如何读取该offset对应的值便比较清楚了。主要步骤如下:
a,在当前partition的leader的broker的数据目录下,找到当前对应partition的目录
b,根据当前目录下所有的log文件进行二分查找,从而定位该offset对应的具体segment文件。
c,将offset减去文件的number或者在该文件内部的序号,然后在索引文件中进行二分查找,找出最大小于或者等于序号。
d,根据索引文件的offset,定位到log文件,进行消息读取。
3,ReplicaManager
在分布式存储中,为了可扩展性,通常会进行切分(如HDFS中将文件切分成block,kafka中的topic切分成partition),然后分块存储。同时,为了提升健壮性和稳定性,又会进行冗余存储。Kafka中的单个parition通常设置有多个副本。在下图中,每个partition有3个副本,其中一个副本为leader,其余2个为follwer。Leader负责当前和producer和consumer交互,完成对当前partition的读写,而Follower跟leader进行交互,同步leader写入的信息。

在topic配置了多副本以后,一旦leader挂掉,Kafka controller会对当前的partition重新进行leader选举,选举的leader从之前的Follower中产生。为了避免在leader切换时造成数据丢失以及可用性问题,Follower需要尽可能快的跟上leader数据的同步进度。当然,最保守的方案是当producer向leader写入一条消息时,leader在向producer发送确认消息之前,确保该消息都已经同步到了Follower。如果这样的话,在replication为3时,可以同时忍受两台机器同时宕机,大大提高了稳定性,但是这种方案的缺点有也非常的明显,写入消息的延迟非常的大,而且一点有某台机器卡主,那么写入也将没法进行,可用性也很差。
那么在Kafka中,Leader和Follower的数据同步机制是咋样的呢?
在Kafka中,定义了ISR的概念。ISR表示的是和Leader保持同步的replica所在的broker集合(也包括leader)。通过延迟时间(rerplica.lag.time.max.ms)或者消息延后的条数(rerplica.lag.max.messages,在0.10版本中,这个参数已经去掉了)来判断Follower是否在ISR中。如果消息或者时间延后大于配置的阈值,则将该Follwer从ISR中剔除。通过ISR机制,使得Leader在等待follower同步消息时不至于太慢,在确保消息不丢失和吞吐量之前取得了一个比较好的平衡。
4,Kafka Controller
Controller在Kafka中扮演了很重要的角色,也是实现地最复杂的一块(设置在0.11开始打算重构这块)。Controller的主要作用如下:
a,Topic管理:包括Topic的创建,删除和partition扩容(不能缩容)。主要借助ZK,将创建或者删除topic的信息写入ZK(/brokers/topics/topic,/admin/delete_topics)路径下,Controller监听到对应的路径变化后,借助AdminManager完成topic的创建或者删除。
b,分区重分配:在集群扩容时,为了使的新的机器和老的机器负载均衡,一般可以通过手工运行kafka-reassign-partitions.sh触发分区的重新分配。这个过程也是借助ZK来实现的,将相关重分配信息写入ZK对应节点,Controller感知到以后,开始进行分区重分配操作。
c,Preferred Leader分配:Preferred Leader是指ISR中第一个broker id。一般情况下,如果所有的partition的leader都是Preferred leader,那么这个topic的partition的分布基本是比较均衡的,反之则不均衡。在不均衡的情况,可以发起Preferred Leader的分配(可以通过手工或者自动)。Controller默认会自动检查不均衡情况,一旦发现不均衡,则默认自动发起Preferred Leader分配操作。
d,更新元数据请求(UpdateMetadataRequest):当Topic Leader,ISR等元数据发生变化的时候,Controller会将这些更新的元数据发送到所有broker。
e,broker的上下线:这个过程和Topic的管理类似,也是通过ZK来感知,然后进行相关操作的。
5,小结
本文主要对kafka内部一些重要的组件和原理做了一般性的介绍,通过对这些原理的介绍,基本上都kafka内部的一些行为有一些大致的了解。后续会对更具体的实现细节做更多的分析(先挖个坑)。
参考资料:
http://orchome.com/
http://matt33.com/tags/kafka/
http://www.jasongj.com/tags/Kafka/
https://blog.csdn.net/u013256816