零 导言
软件安全课上,老师讲了AC算法,写个博客,记一下吧。
那么AC算法是干啥的呢?
——是为了解决多模式匹配问题。换句话说,就是在大字符串S中,看看小字符串s1, s2,...有没有出现。
AC算法的时间复杂度是线性的,思路非常巧妙,也挺好理解的。但是有些的对于AC算法的介绍,挺难看懂的。这是因为原始的AC算法,会存在内存占用过多的问题,因为我们引入了”双数组“的方法来减少内存占用。所以,实际运用的AC算法,都是用双数组的方法写的。
一 基本信息
首先要说明的是,AC全称Aho-Corasick,由Alfred V.Aho和Margaret J.Corasick提出。
1975年,AC算法产生于贝尔实验室,该算法应用有限自动机巧妙地将字符串比较转化为状态转移。
AC算法是基于AC自动机的,那么什么是有限自动机呢,”形式语言与自动机“这门课里讲了,对吧。不过就算不知道,关系也不大。
AC自动机是一种树形自动机,包含一组状态,每个状态用一个数字代表。状态机读入文本串y中的字符,然后通过产生状态转移的方式来处理文本。
其实上面的都是废话,重点是下面一句。AC自动机的行为通过三个函数来指示:转向函数g、失效函数f和输出函数output。
二 具体实现与实例
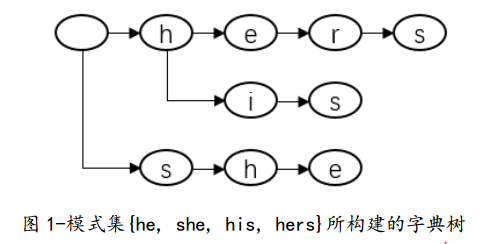
下面以模式集{he, she, his, hers}为例,演示AC算法的工作过程。首先,对于模式集,建一棵字典树,就是下面这棵树。
(一)转向函数
首先,来张图。下图中的树,结构并没有什么变化,只是每个节点对应了一个状态,从状态0到状态9。所谓状态转移g(i,c)=j,就是指状态i 读一个字符c 转移到状态j , 比如g(0,'h')=1,g(1,'e')=2。
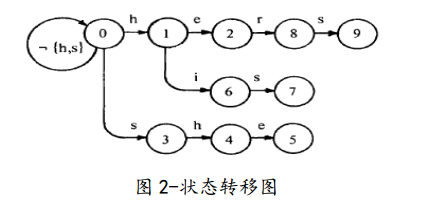
这个还是比较直观的。在建立字典树的时候,转向函数也就建立好了。
建立转向函数有什么用呢?你想啊,假设待匹配的字符是”hersqwew“,那么我们首先从状态0出发,然后读'h',根据g(0,'h')=1,我们跳到状态1;然后读'e',根据g(1,'e')=2,我们跳到状态2;按照这种步骤,一直跳到状态9,那么是不是说明待匹配的字符串中包含模式"hers"和"he"呢?
那么,可能会有人问了,要是在状态0读入字符‘i’,我们该跳到哪里呢?这也就是失效函数需要负责的事情。
(二)失效函数
相对于转向函数,失效函数的构建相对来说复杂一些。
失效函数,顾名思义,就是指转向函数失效之后,程序所执行的函数。转向函数失效之后,失效函数将指定下一个状态。
比如当我们发现g(0,'r')-1的时候,根据f(0)=0,我们跳到状态0。同理,我们发现g(2,'a')=-1的时候,根据f(2)=0,我们也跳到状态0。那么是不是都跳到状态0呢?显然不是。你试想,假设待匹配的字符串为”shis“,我们首先从状态0出发,0->3->4,然后我们我们发现g(4,'i')=-1,那么按理来说,我们应该跳到状态6,因为我们可以看得出“shis”中包含模式“his”。也就是说,应该有f(4)=1,然后通过g(1,'i')=6,我们完成从4->6的跳转。
例子讲完了,那规律是什么呢?
对于f(4)=1,我们发现有g(3,'h')=4和g(0,'h')=1。
来个复杂点的例子,对于待匹配串“shers”,它包含"she"、"he"、"hers"三个模式。当我们读到e的时候,已经到了状态5,再读r,我们发现应该跳到2,然后到3,也就是有f(5)=2。在这里我们发现,g(3,'h')=4和g(0,'h')=1, 以及g(4,'e')=5和g(1,'e')=2。
规律说完了,好好理解一下。可能你会觉得构建起来,比较麻烦,但其实实现起来比较简单。
失效函数构建方法
我们先引入深度d的概念,这里的深度和我们树中常说的深度是一个意思,举个例子d(1)=1,d(6)=2。我们按照如下步骤建立失效函数:
- f(0)=0;
- d=1;
- 循环直到d取最大深度{ 根据深度为d-1的函数值,计算所有深度为d的函数值; d++}
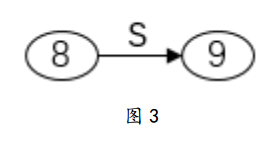
第3步中,”根据深度为d-1的函数值,计算所有深度为d的函数值”,举个例子,对于状态9,存在g(8,s)=9,那么f(9)=g(f(8),s)。按照这个递推式我们就可以从深度d-1的推到深度d 的是失效函数值了。
(三)输出函数
通过转向函数和失效函数,我们能够实现AC自动机一个个地读入字符,然后进行状态跳转。我们还缺一个输出结果的函数,比如当我们跳到了状态2,我们这时应该输出"he",当当我们跳到了状态5,我们应该输出"she"和"he"(注意:不仅仅是"she")。
好了,那我们怎么建立输出函数呢?
分为两部分。首先,在建立转向函数g 的时候,我们就可以建立输出函数,比如output(2)="he", output(9)="hers"等。然后,在建立失效函数f 的时候,我们更新输出函数。具体来说,当我们发现f(s)=s'的时候,有 output(s)=output(s)∪output(s')。例如,有f(5)=2,则output(5)=output(5)∪output(2)={"she","he"}。
(四)匹配过程
在预处理阶段,我们求得转向函数g 、失效函数f 和输出函数output。结果如下(你们可以试着求一下,对一下答案)
转向函数 g(0,'h')=1, g(1,'e')=2, g(2,'r')=8, g(8,'s')=9,
g(1,'i')=6, g(6,'s')=7,
g(0,‘s')=3, g(3,'h')=4, g(4,'e')=5
其他为-1
失效函数 f(4)=1, f(5)=2, f(7)=3, f(9)=3, 其他为0
输出函数 output(2)={"he"}, output(9)={"hers"}, output(5)={"she","he"}, output(7)={"his"} 其他为{}
匹配阶段相对来说,比较简单。
搜索查询阶段 文本扫描开始时,初始状态为0,二输入文本y 的首字符作为当前输入字符。然后,开始按照转向函数进行状态转移。如果转移函数失败则查询失效函数,自动机状态转为失效函数定义的状态。每次的状态转移都要检查输出函数。
也就是说,假设待匹配字符为"hisshers",那么状态转移为:0->1->6-> 7->3 -> 0->3 ->4-> 5->2 ->8->9,依次输出"his"、"she"、"he"、"he"、"hers"。
三 利用双数组进行优化
(一)为什么需要优化
在一开始,我们讲到AC算法存在内存占用过多的问题。那这是怎么回事呢?
对于转向函数g,比如g(i,c)=j ,它有两个输入参数: 当前状态i 和读入的字符c ,和一个输出值j 。那这些怎么存储呢?如果是C语言(不是c++, 或者python),我们肯定就是用数组存的。这样的话,这个数组就会非常大,如果使用ASCII码的话,每个状态的转向函数至少是256a个字节(a为存储一个状态所占的字节数)。然而,这个数组中大量的元素都为-1(NULL),也就是有大量的内存被浪费。
于是,我们引入了双数组的改进方法。
(二)怎么通过双数组优化
双数组,但实际上有三个数组:next数组、base数组和check数组。(我也不知道为什么叫双数组*_*,可能是因为双数组方法的灵魂是base和check数组吧)
假设我们已经计算出next、base和check,那么转向函数的伪代码将会是这样的
def g_index(current_state, ch):
next_state=next[¤t_state+base[current_state]+ch] if check[next_state]==curent_state: return next_state else: return -1
下面分别解释一下三个数组
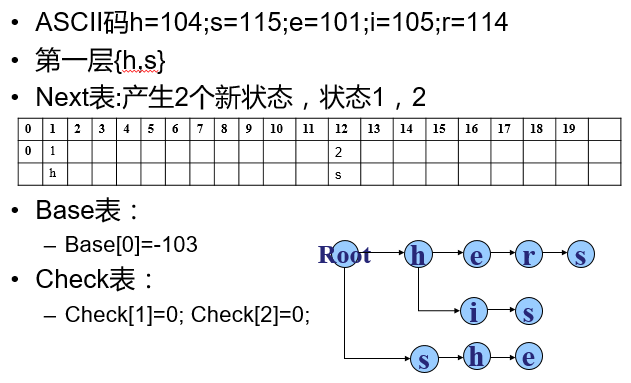
next数组 next为转向函数表,下标是位置偏移量,输出是状态值。
base数组 下标是状态值,输出是base值。Next表中当前状态为s,输入为c时,假设应跳转为状态t,状态t在Next表中的位置=状态S的位置+状态S的Base值+输入c的ASCII码值。
check数组 下标是状态值,输出是下标状态的父状态的值。
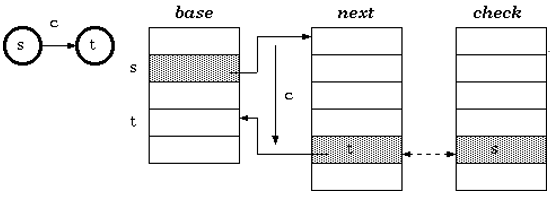
其实,说这么多,倒不如一个例子来的简单。
例子
(一)
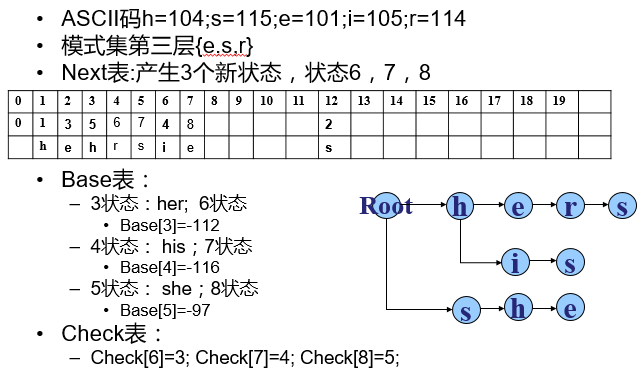
(二)

(三)
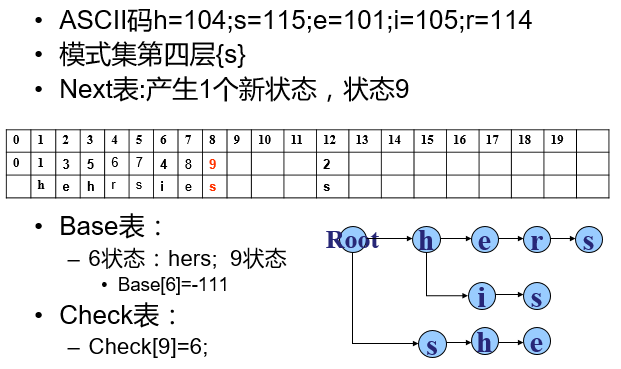
(四)
四 python代码
此外,感谢junboli指出了代码中的错误,现已修正。
# python3
from collections import defaultdict
class Node:
def __init__(self,state_num,ch=None):
self.state_num = state_num
self.ch = ch
self.children = []
class Trie(Node):
"""
实现了一个简单的字典树
"""
def __init__(self):
Node.__init__(self,0)
def init(self):
self._state_num_max = 0
self.goto_dic = defaultdict(lambda :-1)
self.fail_dic = defaultdict(int)
self.output_dic = defaultdict(list)
def build(self,patterns):
"""
参数 patterns 如['he', 'she', 'his', 'hers']
"""
for pattern in patterns:
self._build_for_each_pattern(pattern)
self._build_fail()
def _build_for_each_pattern(self,pattern):
"""
将pattern添加到当前的字典树中
"""
current = self
for ch in pattern:
# 判断字符 ch 是否为节点 current 的子节点
index = self._ch_exist_in_node_children(current,ch)
# 不存在 添加新节点并转向
if index == -1:
current = self._add_child_and_goto(current,ch)
# 存在 直接 goto
else:
current = current.children[index]
self.output_dic[current.state_num] = [pattern]
def _ch_exist_in_node_children(self,current,ch):
"""
判断字符 ch 是否为节点 current 的子节点,如果是则返回位置,否则返回-1
"""
for index in range(len(current.children)):
child = current.children[index]
if child.ch == ch:
return index
return -1
def _add_child_and_goto(self,current,ch):
"""
在当前的字典树中添加新节点并转向
新节点的编号为 当前最大状态编号+1
"""
self._state_num_max += 1
next_node = Node(self._state_num_max,ch)
current.children.append(next_node)
# 修改转向函数
self.goto_dic[(current.state_num,ch)] = self._state_num_max
return next_node
def _build_fail(self):
node_at_level = self.children
while node_at_level:
node_at_next_level = []
for parent in node_at_level:
node_at_next_level.extend(parent.children)
for child in parent.children:
v = self.fail_dic[parent.state_num]
while self.goto_dic[(v,child.ch)] == -1 and v != 0:
v = self.fail_dic[v]
fail_value = self.goto_dic[(v,child.ch)]
self.fail_dic[child.state_num] = fail_value
if self.fail_dic[child.state_num] != 0:
self.output_dic[child.state_num].extend(self.output_dic[fail_value])
node_at_level = node_at_next_level
class AC(Trie):
def __init__(self):
Trie.__init__(self)
def init(self,patterns):
Trie.init(self)
self.build(patterns)
def goto(self,s,ch):
if s == 0:
if (s,ch) not in self.goto_dic:
return 0
return self.goto_dic[(s,ch)]
def fail(self,s):
return self.fail_dic[s]
def output(self,s):
return self.output_dic[s]
def search(self,text):
current_state = 0
ch_index = 0
while ch_index < len(text):
ch = text[ch_index]
if self.goto(current_state,ch) == -1:
current_state = self.fail(current_state)
current_state = self.goto(current_state,ch)
patterns = self.output(current_state)
if patterns:
print (current_state,*patterns)
ch_index += 1
if __name__ == "__main__":
ac = AC()
ac.init(['hert', 'this', 'ishe', 'hit','it'])
ac.search("ithisherti")
本文链接:http://www.superzhang.site/blog/AC-algorithm-and-its-python-implementation/