Density-based spatial clustering of applications with noise (DBSCAN)
名字较长,记它的initials,DBSAN/di,bi,skæn/,他基于数据的密度来聚类,所以适合数据稠密的情况,且在数据非凸情况下优于Kmeans。
DBSCAN对密度的定义
两个参数$(varepsilon ,Minpoints)$,$varepsilon$表示任一样本点领域的阈值,Minpoints表示该领域内的所有样本点个数的下限。
假设数据集D=Xi,i=1,2,,,n
定义
1,$varepsilon$-领域 :表示对于样本点$x_{i}in D$,$varepsilon$-领域包含所有距离不大于$varepsilon$的子样本。
2,核心对象(core point):表示对于样本点$x_{i}in D$,在$varepsilon$-领域内的样本点个数最少为Minpoints,则称$x_{i}$为核心对象。
3,密度直达(directly destiny reachable):在核心对象$x_{i}$的$varepsilon$-领域内有一点$x_{j}$,称$x_{j}$由$x_{i}$的密度直达,无对称性。
4,密度可达(destiny reachable):对于核心对象p,核心对象o由p密度直达,核心对象q由o密度直达,我们称q由p密度可达,注意箭头为单向,即无对称性。

5,密度相连:g由o密度可达,h由o密度可达,g,h密度相连。

DBSCAN聚类
定义:由密度可达导出的最大的密度相连的子样本即为一簇。
流程:任意找到一个没有类别的核心对象,找到所有由这个核心对象密度可达的子样本,作为一类。接着再找一个没有类别的核心对象。。。
疑点:1,DBCSAN允许一些样本点不属于任一簇,称为噪点 。
2,距离的度量,对于小样本用欧氏距离,计算所有样本点的两两距离;大样本时,采用KD树或者球树(此为KNN中的思想,不懂直接搬过来的,有机会补)
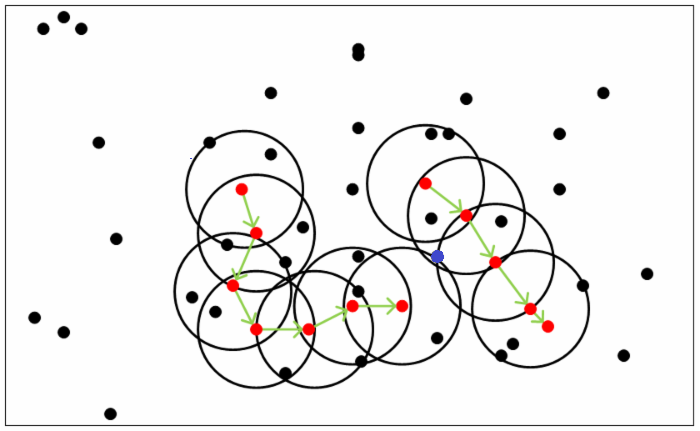
3,当某样本点可由两个核心对象密度直达,但是这两个核心对象不在一个簇如下图蓝色点,DBCSAN采用先来后到的原则。
参考:
https://www.cnblogs.com/pinard/p/6208966.html