原文地址:http://www.cnblogs.com/RicCC/archive/2009/09/25/mysql.html
存储引擎
| Attribute | MyISAM | Heap | BDB | InnoDB |
|---|---|---|---|---|
| Transactions | No | No | Yes | Yes |
| Lock granularity | Table | Table | Page (8 KB) | Row |
| Storage | Split files | In-memory | Single file per table | Tablespace(s) |
| Isolation levels | None | None | Read committed | All |
| Portable format | Yes | N/A | No | Yes |
| Referential integrity | No | No | No | Yes |
| Primary key with data | No | No | Yes | Yes |
| MySQL caches data records | No | Yes | Yes | Yes |
| Availability | All versions | All versions | MySQL-Max | All Versions |
To make it easier to follow the unique characteristics of each storage engine, I created this magic quadrant diagram:
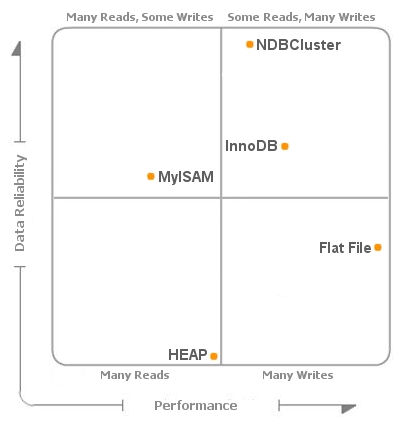
Below are some examples of using the best storage engine for different tasks:
Search Engine - NDBCluster
Web stats logging - Flat file for the logging with an offline processing
demon processing and writing all stats into InnoDB tables.
Financial Transactions - InnoDB
Session data - MyISAM or NDBCluster
Localized calculations - HEAP
Dictionary - MyISAM
MyISAM
设计为处理读频率远大于写频率的情况,查询性能非常好;不支持事务,没有REDO、UNDO日志;支持表锁;
每个表使用独立的文件,索引和数据都
存放在不同文件中,文件的存储以file
block(页)的形式存储。只缓存索引,并不缓存实际数据,每次读取数据时要使用磁盘IO,索引在内存中以cache block形式组织,与file
block对应。索引的缓存使用LRU算法管理,为了提高缓存的利用率,支持将缓存分成多个区域,例如分成Hot Area、Warm Area
key_buffer_size:设置缓存总大小
key_buffer_block_size:设置cache block大小
key_cache_division_limit:以百分比的形式将整个缓存区划分为多个区域。系统默认为100,即只有Warm Area
key_cache_age_threshold:控制各区域中的何时被降级,值越小,越容易降级到下一级area中
表的扫描分为Sequential Scan和Radom Scan 2种方式,read_buffer_size设置sequential scan时使用的缓存,read_rnd_buffer_size设置radom scan时使用的缓存
InnoDB
设计用于高并发读写情况,支持行锁(必须有索引支持);支持事务安全性,具有REDO、UNDO日志,具备故障恢复能力,其事务实现了SQL92的4个级别;支持外键,实现了数据库的引用完整性特性;
Adaptive
Hash Index:InnoDB自动检测索引状况,如果发现可以通过hash index提高效率,会在内部创建一个基于B-Tree的hash
index,并根据B-Tree索引的变化自动调整。hash
index并不基于整个B-Tree创建,只针对其中的某部分;并不会存储到磁盘,仅创建在缓存区中
InnoDB的数据文件支持共享表空间和独享
表空间2种模式,数据和索引存储在一起,支持数据和索引的缓存。存储结构从大到小依次为
tablespace->segment->extent->Page,page默认为16KB,每个extent包含64个
page,每个segment存放同一种数据,一般每个表存放于一个单独的segment中
锁机制
有表锁(MyISAM)、页锁(BDB)、行锁(InnoDB)三种
表锁:
有4个队列记录锁的使用情况:Current read-lock(当前读锁队列), Pending read-lock(等待读锁的队列), Current write-lock(当前写锁队列), Pending write-lock(等待写锁的队列)
读锁、写锁:
a). Current write-lock中当前资源的写锁会阻塞读锁和写锁请求.
b). Pending write-lock中WRITE类型的写锁会阻塞除了READ_HIGH_PRIORITY类型外的所有读锁请
求;READ_HIGH_PRIORITY类型的读锁比WRITE类型的写锁优先级高,因此它会阻塞Pending
write-lock中所有的写锁请求;除了WRITE类型的写锁,Pending
write-lock中其他类型的写锁优先级比读锁低(提高查询的响应时间)
c). Current write-lock中对资源的写锁类型为WRITE_ALLOW_WRITE时,允许除了WRITE_ONLY之外的所有读锁和写锁请求
MyISAM是MySQL官方开发的存储引擎,完全使用MySQL自己的表锁机制,其他几种支持事务的存储引擎都是让MySQL将锁处理交由存储引擎自行
实现,他们在MySQL中仅持有WRITE_ALLOW_WRITE类型的锁,至于锁的定义、并发冲突控制等都由各存储引擎处理
MyISAM表锁优化提示:MyISAM表锁读写互相阻塞,写锁优先级高于读锁
a). 参数选项low_priority_updates设置写锁优先级比读锁低,用于保证查询响应速度
b). 参数选项concurrent_insert配置是否使用并发插入特性,可以实现并发的读取和插入操作,配置值: 0:不允许并发插入;
1:数据文件中不存在空闲空间的时候可以在文件尾部进行并发插入;
2:不管数据文件是否存在空闲空间,均允许在文件尾部进行并发插入(插入操作将一直在文件尾部进行,中间的空闲空间无法利用,适用于删除操作很少的表)
InnoDB的行锁:
不是MySQL实现的锁机制,行锁都由其他存储引擎实现,这里以InnoDB为例(不同存储引擎实现机制也不一样)
Oracle的行锁是在物理块的事务槽中记录锁信息,而InnoDB是在索引键值的起始、结束位置上记录锁信息(间隙锁),所以InnoDB的行锁只是利用索引实现的一个范围锁,而利用索引可以定位到数据行
锁类型以及排他性:
| 共享锁(S) | 排他锁(X) | 意向共享锁(IS) | 意向排他锁(IX) | |
|---|---|---|---|---|
| 共享锁(S) | 兼容 | 冲突 | 兼容 | 冲突 |
| 排他锁(X) | 冲突 | 冲突 | 冲突 | 冲突 |
| 意向共享锁(IS) | 兼容 | 冲突 | 兼容 | 兼容 |
| 意向排他锁(IX) | 冲突 | 冲突 | 兼容 | 兼容 |
InnoDB行锁潜在的问题:
a). 如果无法使用索引信息,InnoDB将使用表锁
b). 当索引不是确定到某一行数据时,InnoDB锁定的是索引匹配到的整个范围内的数据。例如使用索引定位到了10条记录,而加上非索引的条件可以准确确定到一条记录,这种情况下InnoDB仍然锁定这10条记录
事务隔离级别:
InnoDB实现了SQL92的4个隔离级别:Read UnCommited, Read Commited, Repeatable Read, Serializable
InnoDB有死锁检测机制,将发生死锁的2个事务中较小(修改数据量比较少)的那个作为死锁牺牲品。当然只限于InnoDB存储引擎范围之内,跨存储引擎的死锁只能通过死锁超时设置进行处理
索引
MySQL主要有4类索引:B-Tree索引、Hash索引、Fulltext索引、R-Tree索引
B-Tree索引: 通用索引类型
InnoDB中的B-Tree索引分为Cluster形式的Primary Key和Secondary Index,与SQL
Server类似,Primary Key索引的叶节点是实际数据文件,按索引顺序排列,Secondary Index的叶节点只存储Primary
Key值。MyISAM的主键索引和非主键索引没什么区别,与InnoDB的Secondary
Index类似,只是其叶节点存放的不是PK值,而是直接定位到数据行的信息
Hash索引:
将数据的索引键值进行hash运算建立索引,查询匹配时将查询条件也做hash运算,比较hash值进行匹配。主要是Memory和NDB Cluster存储引擎使用
Hash索引的查询效率非常高,因为不需要像B-Tree一样从根匹配到页节点(《MySQL性能调优与架构设计》中说hash索引可以一次定位要查找的
记录,这种说法可能存在问题,Hash索引的组织、hash值的匹配同样需要数据结构和算法的实现,不可能一次定位,设想hash索引以B-Tree方式
组织,比B-Tree索引优秀的地方可能是其B-Tree数据量会小,即使这样也可能意味着hash冲突的存在,其效率比B-Tree索引高的说法是有待
验证的,可能需要有不少前提条件)
缺点:只能进行等值匹配;hash索引是无序的,可能需要额外的排序操作;无法进行部分匹配,只能全索引匹配;遇到hash冲突后效率可能会比较低
Fulltext索引: 只有MyISAM的CHAR, VARCHAR, TEXT三种数据类型支持fulltext索引,主要用于优化效率比较低的like '%***%'操作
MySQL的fulltext中文支持有待考察,fulltext索引的创建成本比较高
R-Tree索引: 用于空间数据检索
MySQL有空间数据类型GEOMETRY(5.0.16之前只有MyISAM支持,之后BDB、InnoDB、NDB Cluster、Archieve等支持),只有MyISAM存储引擎支持R-Tree索引