tomcat已经启动完成了,那么是怎么处理请求的呢?怎么到了我们所写的servlet的呢?
目录
- Http11ConnectionHandler
- Http11Processor
- CoyoteAdapter
- StandardEngineValve
- StandardWrapperValve
- 总结
Http11ConnectionHandler
在tomcat 启动之后会使用socket.accept接收请求,接收到之后会调用自己的processSocket来处理请求,在该方法中启动一个SocketProcessor线程,在该内部类的run方法内调用Http11ConnectionHandler.process,过程如下:
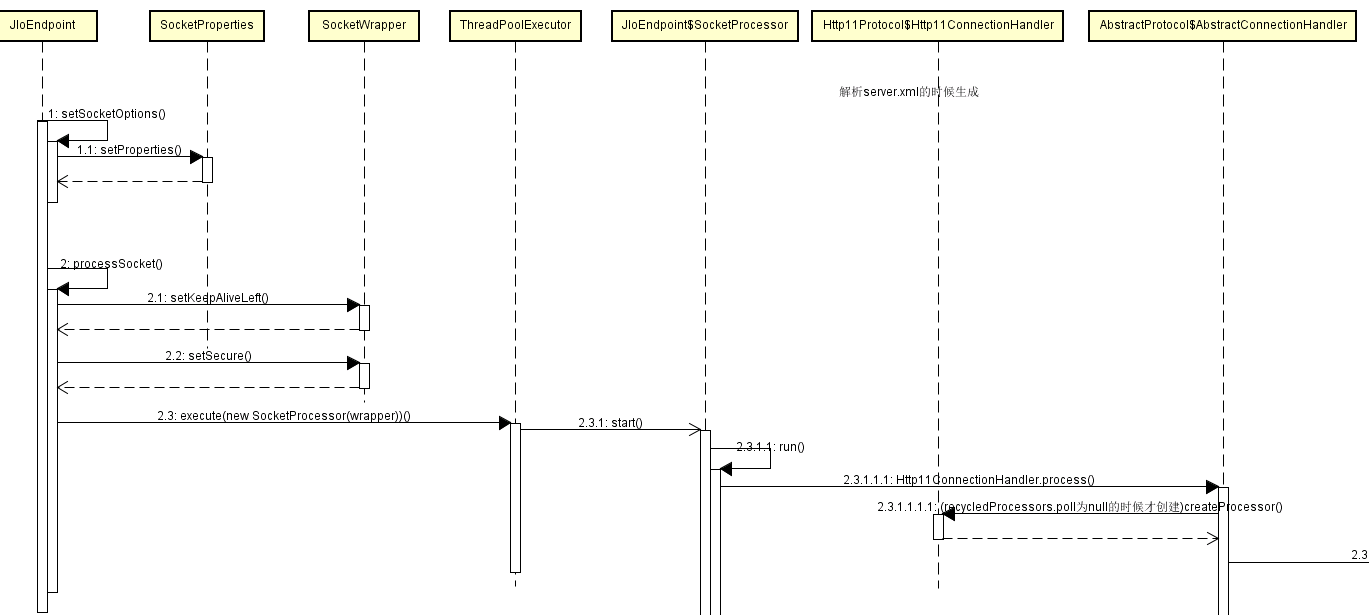
实际执行的是超类AbstractConnectionHandler.process方法,主要作用:
- 从connections里面获取processor
- 如果processor为null则尝试从队列里面获取一个processor,该队列是一个RecycledProcessors类继承自ConcurrentLinkedQueue,是一个线程安全的队列,因为同时会有多个线程获取processor
- 如果processor还是为null(表明还未创建或者已经用完),那么创建一个新的processor,调用Http11ConnectionHandler.createProcessor,该方法会创建一个新的Http11Processor(但是并不会立即添加到上面提到的队列里面,而是在请求处理完成之后才会添加到队列里面)
- 调用Http11Processor.process
Http11Processor
在connector出来完成之后会启动processor线程,关于processor的类图如下:
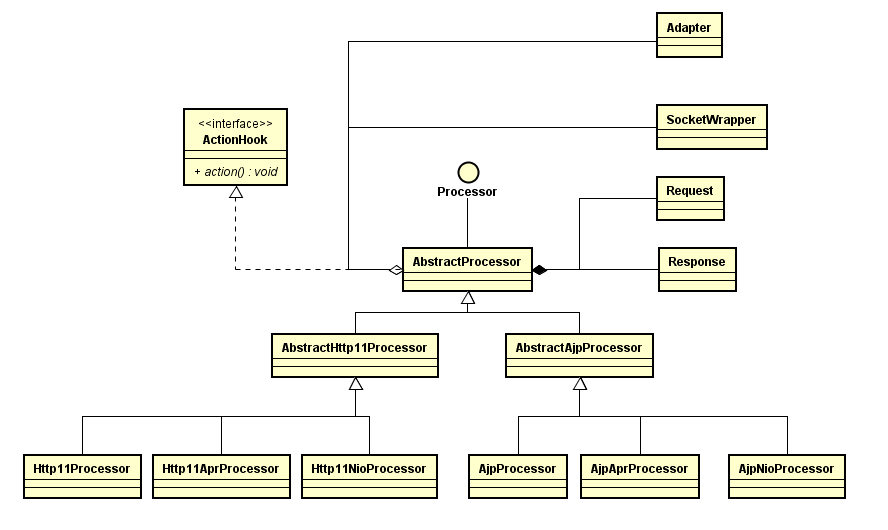
和处理协议一 一对应,不同的协议也有不同的processor,在AbstractProcessor里面有Request和Response,不过是org.apache.coyote包下面的,这是在connector层面的连接器,是primitive的。
实际执行的也是超类AbstractHttp11Processor.process,主要功能如下:
- 获得socket的输入、输出流
- parsing request header、method、requestURI
- 设置input filters,并设置content-length等header
- 调用CoyoteAdapter.service
CoyoteAdapter
由connector和processor过渡到container的类,使用了adapter模式,将container适配到processor。主要的方法就是CoyoteAdapter.service:
- 获取org.apache.connector.Request和Response,这两个类经过facade模式之后就是最后我们servlet中使用的request和response
- 如果是新建的processor,request和response为null,那么就调用connector.createRequest和createResponse新建,然后设置到coyote.request的note中
- 调用postParseRequest,添加wrapper和servlet之间的映射(在后面load servlet的时候用到,request.setWrapper((Wrapper) request.getMappingData().wrapper);),parseSessionId解析sessionId
- connector.getService().getContainer().getPipeline().getFirst().invoke(request, response),依次是:Connector,StandardService,StandardEngine,StandardPipeline,StandardEngineValve
- 在执行完之后,完成请求也在这个方法中:request.finishRequest(上面说过的processor就是在这儿回收的),response.finishResponse(请求在这里返回到客户端,outputStream)
- 最后,recycle request和response,清空request和response所有信息
StandardEngineValve
这个是StandardEngine的基础阀(每个容器都有一个pipeline,每个pipeline都有一个基础阀,用来调用servlet)在adapter中最后调用到了StandardEngineValve.invoke方法,该方法主要进行了以下操作
- request.getHost:获取host
- host.getPipeline().getFirst().invoke(request, response):依次是StandardHost,StandardPipeline,StandardHostValve
接下来就是容器逐级依次调用,下一个是StandardHostValve:
context.getPipeline().getFirst().invoke(request, response);
在接下来是NonloginAuthencator
context.invokeNext(request,response)
接着是StandardContextValve
wrapper.getPipeline().getFirst().invoke(request, response);
接下来就是StandardWrapperValve,在这里进行了很多工作。
StandardWrapperValve
这是StandardWrapper的基础阀,作用就是获取servlet实例并调用filterChain,主要方法是invoke:
- 获取容器wrapper,通过wrapper分配一个servlet实例
- 使用ApplicationFilterFactory创建filterChain,web.xml配置的filter在这里加入到filter链中
- filterChain.doFilter调用filter链,这里没有配置额外的filter,只有一个默认的WsFilter(对websocket的支持),在所有的filterChain调用完成之后,就是调用servlet.service 方法,开始进入我们写的servlet里面
- 在上面调用完成之后,释放filterChain(将filter置空),释放servlet(会受到instantPool里面)
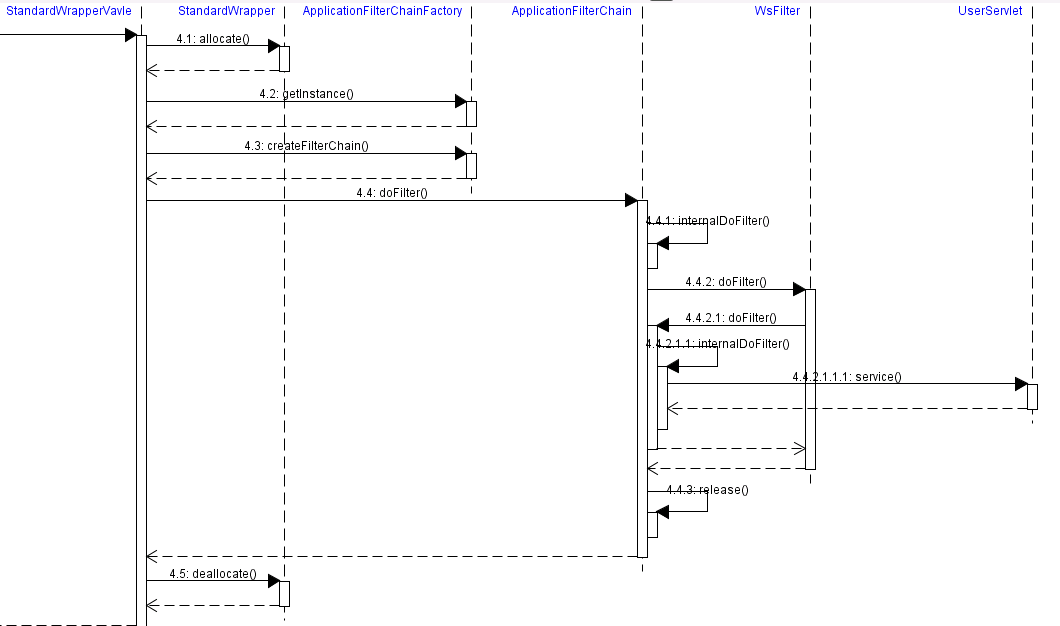
这个执行流程如上,最后一个UserServlet是我自定义的简单的servlet。到了自定义的servlet之后,依次请求也就是到了最深层,接下来就是逐层范返回,并做一些清理工作(当然了还有一些长连接的维护等等)。
总结
从socket监听接收开始,到我们自定义的servlet处理请求结束,是一次完整的请求过程,为了说明白请求的整个过程,省略了很多细节,比如:三种request(coyote.Request,connector.Request,RequestFacade)之间的转换,session的管理等等。