上一篇介绍了zookeeper的单机启动,集群模式下启动和单机启动有相似的地方,但是也有各自的特点。集群模式的配置方式和单机模式也是不一样的,这一篇主要包含以下内容:
-
概念介绍:角色,服务器状态
-
服务器组件启动
-
leader选举
概念介绍:角色,服务器状态
集群模式会有多台server,每台server根据不同的角色会有不同的状态,server状态的定义如下
public enum ServerState {
LOOKING, FOLLOWING, LEADING, OBSERVING;
}
LOOKING:表示服务器处于选举状态,说明集群正在进行投票选举,选出leader
FOLLOWING:表示服务器处于following状态,表示当前server的角色是follower
LEADING:表示服务器处于leading状态,当前server角色是leader
OBSERVING:表示服务器处于OBSERVING状态,当前server角色是OBSERVER
对应server的角色有:
leader
投票选出的leader,可以处理读写请求。处理写请求的时候收集各个参与投票者的选票,来决出投票结果
follower
作用:
- 参与leader选举,可能被选为leader
- 接收处理读请求
- 接收写请求,转发给leader,并参与投票决定写操作是否提交
observer
为了支持zk集群可扩展性,如果直接增加follower的数量,会导致投票的性能下降。也就是防止参与投票的server太多,导致leader选举收敛速度较慢,选举所需时间过长。
observer和follower类似,但是不参与选举和投票,
- 接收处理读请求
- 接收写请求,转发给leader,但是不参与投票,接收leader的投票结果,同步数据
这样在支持集群可扩展性的同时又不会影响投票的性能
服务器组件启动
集群模式下服务器启动的组件一部分和单机模式下类似,只是启动的流程和时机有所差别
- FileTxnSnapLog
- NIOServerCnxnFactory
- Jetty

也是会启动上面三个组件,但是因为集群模式还有其他组件需要启动,所以具体启动的逻辑不太一样。
除了上面这些组件外,集群模式下还有一些用来支撑集群模式的组件
- QuorumPeer:用来启动各个组件,是选举过程的mainloop,在loop中判断当前server状态来决定做不同的处理
- FastLeaderElection:默认选举算法
- QuorumCnxManager:选举过程中的网络通信组件
QuorumPeer
解除出来的QuorumPeerConfig配置都设置到QuorumPeer对应的属性中,主线程启动完QuorumPeer后,调用该线程的join方法等待该线程退出。
QuorumCnxManager
负责各个server之间的通信,维护了和各个server之间的连接,下面的线程负责与其他server建立连接
org.apache.zookeeper.server.quorum.QuorumCnxManager.Listener
还维护了与其他每个server连接对应的发送队列,SendWorker线程负责发送packet给其他server
final ConcurrentHashMap<Long, ArrayBlockingQueue<ByteBuffer>> queueSendMap;
这个map的key是建立网络连接的server的myid,value是对应的发送队列。
还有接收队列,RecvWorker是用来接收其他server发来的Message的线程,将收到的Message放入队列中
org.apache.zookeeper.server.quorum.QuorumCnxManager#recvQueue
leader选举
选举入口在下面的方法中
org.apache.zookeeper.server.quorum.FastLeaderElection#lookForLeader
判断投票结果的策略
上面这个是其中的一种选举算法,选举过程中,各个server收到投票后需要进行投票结果抉择,判断投票结果的策略有两种
// 按照分组权重
org.apache.zookeeper.server.quorum.flexible.QuorumHierarchical
// 简单按照是否是大多数,超过参与投票数的一半
org.apache.zookeeper.server.quorum.flexible.QuorumMaj
选票的网络传输
zookeeper中选举使用的端口和正常处理client请求的端口是不一样的,而且由于投票的数据和处理请求的数据不一样,数据传输的方法也不一样。选举使用的网络传输相关的类和数据结构如下
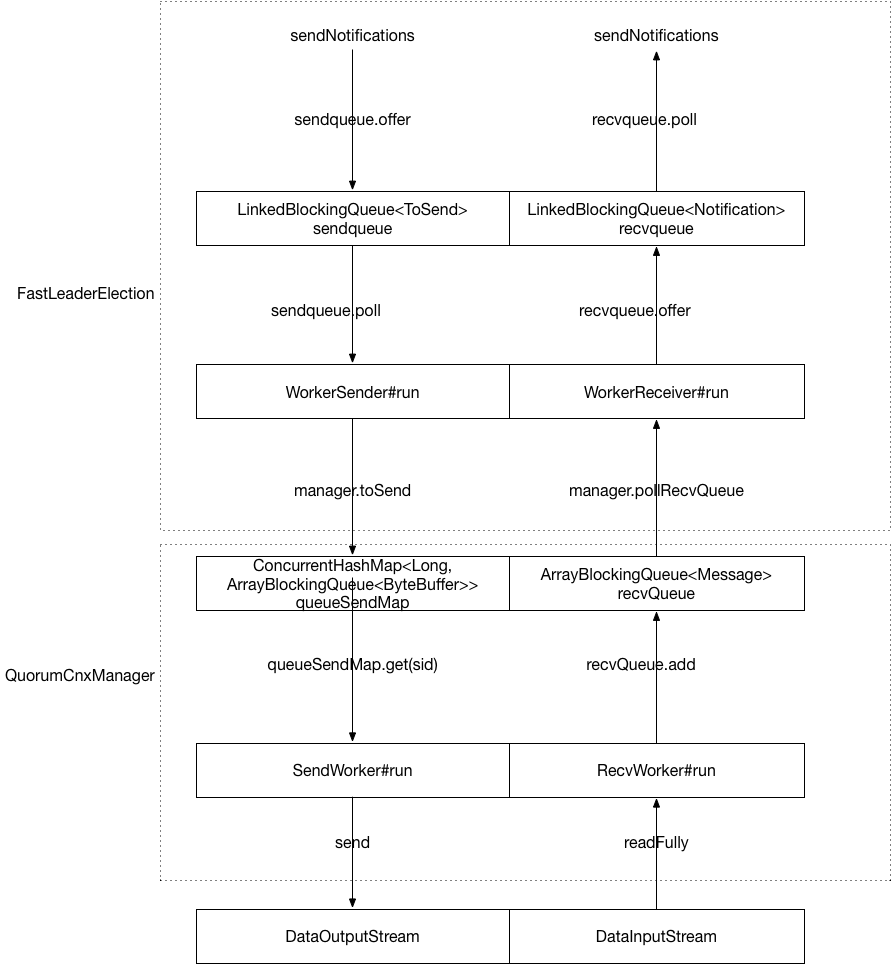
选举过程
-
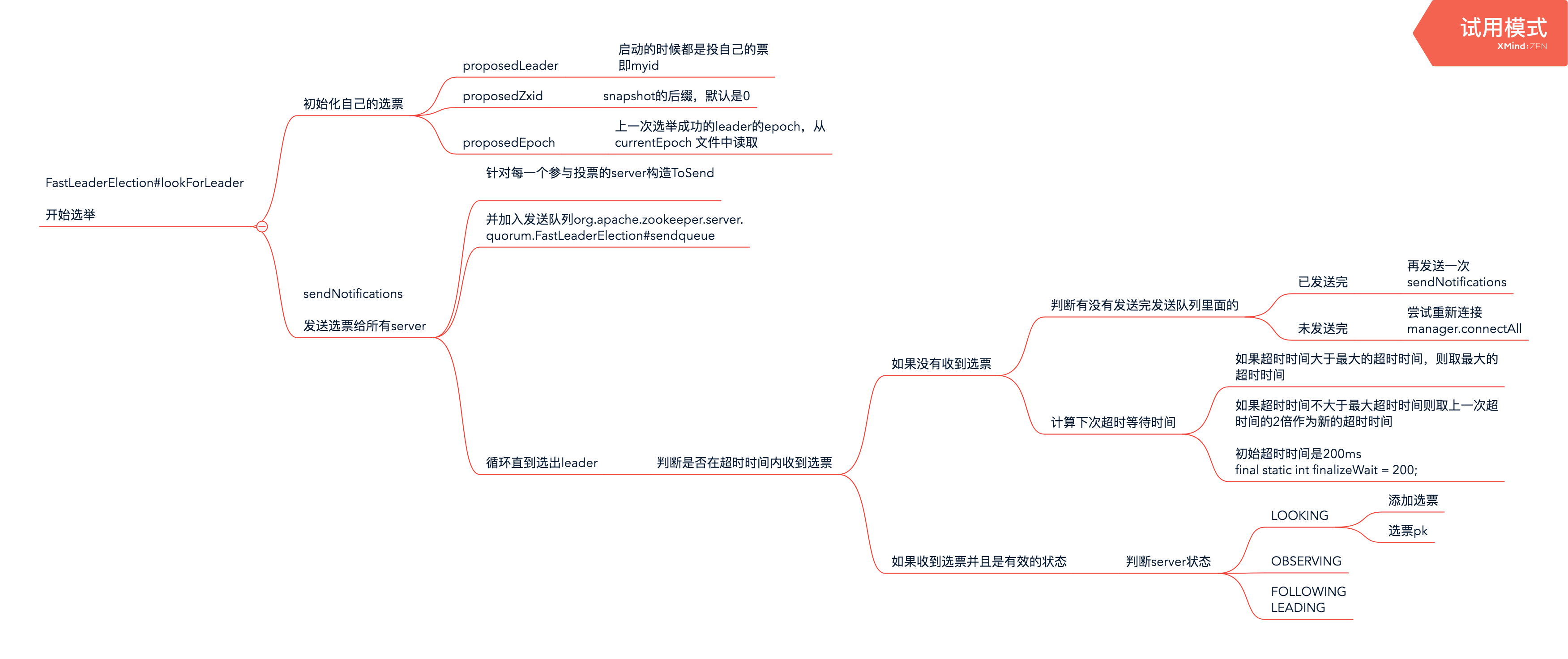
各自初始化选票
-
- proposedLeader:一开始都是选举自己,myid
- proposedZxid:最后一次处理成功的事务的zxid
- proposedEpoch:上一次选举成功的leader的epoch,从currentEpoch 文件中读取
- proposedLeader:一开始都是选举自己,myid
-
发送自己的选票给其他参选者
-
接收其他参选者的选票
-
-
收到其他参选者的选票后会放入recvqueue,这个是阻塞队列,从里面超时获取
-
如果超时没有获取到选票vote则采用退避算法,下次使用更长的超时时间
-
校验选票的有效性,并且当前机器处于looking状态,开始判断是否接受
-
-
如果收到的选票的electionEpoch大于当前机器选票的logicalclock
-
-
进行选票pk,收到的选票和本机初始选票pk,如果收到的选票胜出则更新本地的选票为收到的选票
-
-
pk的算法
-
- org.apache.zookeeper.server.quorum.FastLeaderElection#totalOrderPredicate
- 选取epoch较大的
- 如果epoch相等则取zxid较大的
- 如果zxid相等则取myid较大的
- org.apache.zookeeper.server.quorum.FastLeaderElection#totalOrderPredicate
-
-
-
如果本机初始选票胜出则更新为当前机器的选票
-
更新完选票之后重新发出自己的选票
-
-
-
-
-
- 如果n.electionEpoch < logicalclock.get()则丢弃选票,继续准备接收其他选票
-
-
如果n.electionEpoch == logicalclock.get()并且收到的选票pk(pk算法totalOrderPredicate)之后胜出
-
- 更新本机选票并且,发送新的选票给其他参选者
-
执行到这里,说明收到的这个选票有效,将选票记录下来,recvset
-
统计选票
-
- org.apache.zookeeper.server.quorum.FastLeaderElection#getVoteTracker
- 看看已经收到的投票中,和当前机器选票一致的票数
- org.apache.zookeeper.server.quorum.FastLeaderElection#getVoteTracker
-
判断投票结果
-
-
org.apache.zookeeper.server.quorum.SyncedLearnerTracker#hasAllQuorums
-
根据具体的策略判断
-
-
QuorumHierarchical
-
QuorumMaj,默认是这个
-
- 判断投该票的主机数目是否占参与投票主机数的大部分,也就是大于1/2
-
-
-
如果本轮选举成功
-
- 如果等finalizeWait时间后还没有其他选票的时候,就认为当前选举结束
- 设置当前主机状态
- 退出本轮选举
- 如果等finalizeWait时间后还没有其他选票的时候,就认为当前选举结束
-
-
-
-
-
-
选举的整个流程为
总结
集群启动过程其实就是在单机启动的部分基础上,增加了关于集群的一些组件,而且有leader的选举。