RDD是Spark对各类数据计算模型的统一抽象,被用于迭代计算过程以及任务输出结果的缓存读写。
在所有MapReduce框架中,shuffle是连接map任务和reduce任务的桥梁。shuffle性能优劣直接决定了
整个计算引擎的性能和吞吐量。
6.1 迭代计算
MappedRDD的iterator方法
6.2 什么是shuffle
shuffle是所有MapReduce计算框架所必须经过的阶段,shuffle用于打通map任务的输出与reduce任务的输入,
map任务的中间输出结果按照key值哈希后分配给某一个reduce任务。
目前Spark的shuffle已经做了多种性能优化,主要解决方案包括:
1>将map任务输出的bucket(给每个partition的reduce)合并到同一个文件中,这解决了bucket数量很对多,但是本身数据体积不大
时,造成shuffle很频繁,磁盘I/O成为性能瓶颈的问题。
2>map任务逐条输出计算结果,而不是一次性输出到内存中,并使用缓存及其聚合算法对中间结果进行聚合,大大减小了中间结果所占的内存大小。
3>缓存溢出判断,超过大小时,将数据写入磁盘,防止内存溢出
4>reduce任务对拉取到的map任务中间结果逐条读取,而不是一次性读入内存,并在内存中使用聚合和排序,大大减少了数据占用内存
5>reduce任务将要拉取的Block按照BlockManager地址划分,然后将同一BlockManager地址中的Block累计为少量网络请求,减少网络I/O
6.3 map端计算结果缓存处理
首先理解两个概念:
bypassMergeThreshold:传递到reduce端再做merge操作的阈值。默认200
bypassMergeSort:标记是否传递到reduce端再做合并和排序
map端计算结果缓存有三种处理方式:
1.map端对计算结果在缓存中执行聚合和排序。
2.map不适用缓存,也不执行聚合和排序,直接调用spillToPartitionFiles将各个partition直接写到自己存储文件,
最后由reduce端对计算结果执行合并和排序。
3.map端对计算结果简单缓存。
6.3.1 map端结算结果缓存聚合
在一个任务的分区数量通常很多,如果只是简单地将数据存储到Executor上。在执行reduce任务时会存在大量的网络I/O操作。
这时网络I/O将成为系统性能的瓶颈,reduce任务读取map任务的计算结果变慢,导致其他任务不得不选择分配到更远的节点。
通过在map端对计算结果在缓存中执行聚合和排序,能够节省I/O操作,进而提升系统性能。
6.3.2 map端计算结果简单缓存
6.3.3 容量限制
AppendOnlyMap和SizeTrackingPairBuffer的容量都可以增长,那么数据量不大的时候不会有问题。
由于大数据处理的数据量往往都比较大,全部都放入内存内会将系统内存撑爆,Spark为了防止这个问题,
提供函数maybeSpillConllection。
6.4 map端计算结果持久化
wirtePartitionFile用于持久化计算结果。
1.溢出到分区文件后合并:将内存中缓存的多个partition的计算结果分别写入临时Block文件,再将这些Block文件的内容全部写入到Block输出文件中。
2.内存中排序合并:将缓存的中间计算结果按照partition分组后写入Block输出文件。
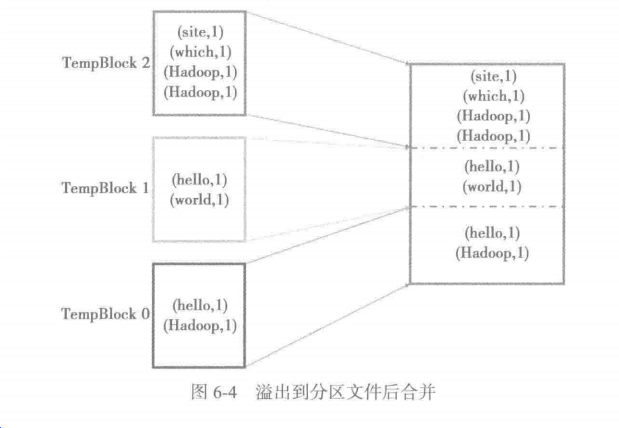
6.4.1 溢出分区文件
每个map任务实际最后只会生成一个磁盘文件。
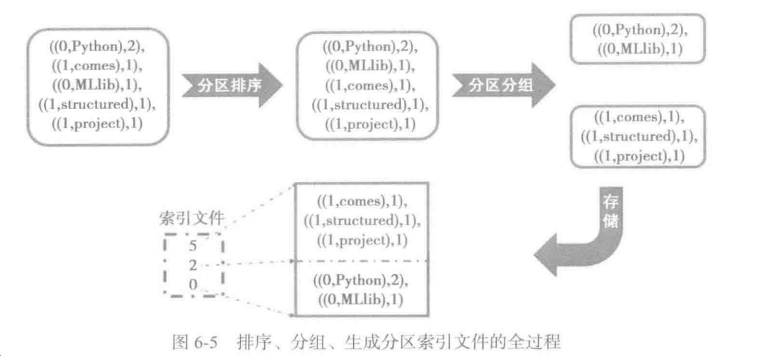
6.4.2 排序与分区分组
partitionedIterator 通过对集合按照指定的比较器进行比较,按照partition id分组,生成迭代器。
6.4.3 分区索引文件
6.5 reduce端读取中间计算结果
6.5.1 获取map任务状态
6.5.2 划分本地与远程Block
6.5.3 获取远程Block
sendRequest方法用于远程请求中间结果。
sendRequest利用FetchRequest里封装的BlockId、size、address等信息。
调用shuffleClient的fetchBlocks方法获取其他节点上的中间结果。
6.5.4 获取本地Block
fetchLocalBlock用于对本地中间计算结果的获取。
6.6 reduce端计算
6.6.1 如何同时处理多个map任务的中间结果
6.6.2 reduce端在缓存中对中间计算结果执行聚合和排序
6.7 map端和reduce端组合分析
6.7.1 在map端溢出分区文件,在reduce端合并组合

6.7.2 在map端简单缓存、排序分组,在reduce端合并组合

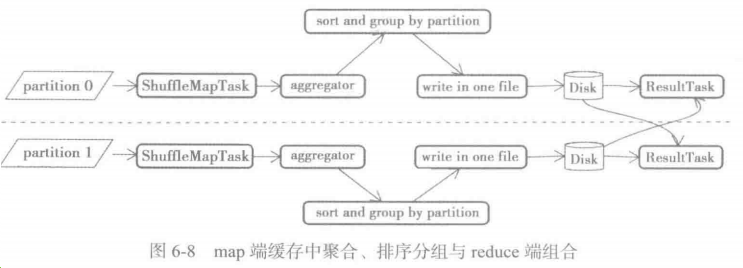
6.7.3 在map端缓存中聚合、排序分组,在reduce端组合
6.8 小结
本章从迭代计算的层层剥离开始,分析了map和reduce任务的处理逻辑。